by Joche Ojeda | Oct 21, 2024 | A.I, Semantic Kernel
A few weeks ago, I received the exciting news that DevExpress had released a new chat component (you can read more about it here). This was a big deal for me because I had been experimenting with the Semantic Kernel for almost a year. Most of my experiments fell into three categories:
- NUnit projects with no UI (useful when you need to prove a concept).
- XAF ASP.NET projects using a large textbox (String with unlimited size in XAF) to emulate a chat control.
- XAF applications using a custom chat component that I developed—which, honestly, didn’t look great because I’m more of a backend developer than a UI specialist. Still, the component did the job.
Once I got my hands on the new Chat component, the first thing I did was write a property editor to easily integrate it into XAF. You can read more about property editors in XAF here.
With the Chat component property editor in place, I had the necessary tool to accelerate my experiments with the Semantic Kernel (learn more about the Semantic Kernel here).
The Current Experiment
A few weeks ago, I wrote an implementation of the Semantic Kernel Memory Store using DevExpress’s XPO as the data storage solution. You can read about that implementation here. The next step was to integrate this Semantic Memory Store into XAF, and that’s now done. Details about that process can be found here.
What We Have So Far
- A Chat component property editor for XAF.
- A Semantic Kernel Memory Store for XPO that’s compatible with XAF.
With these two pieces, we can create an interesting prototype. The goals for this experiment are:
- Saving “memories” into a domain object (via XPO).
- Querying these memories through the Chat component property editor, using Semantic Kernel chat completions (compatible with all OpenAI APIs).
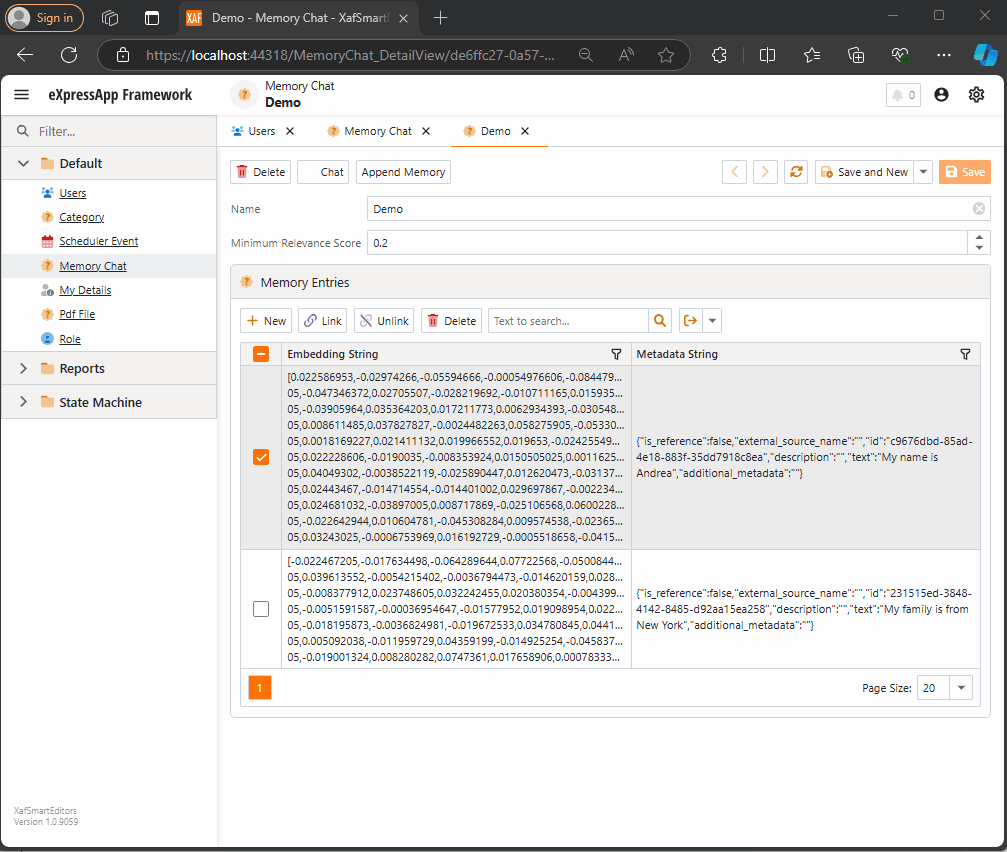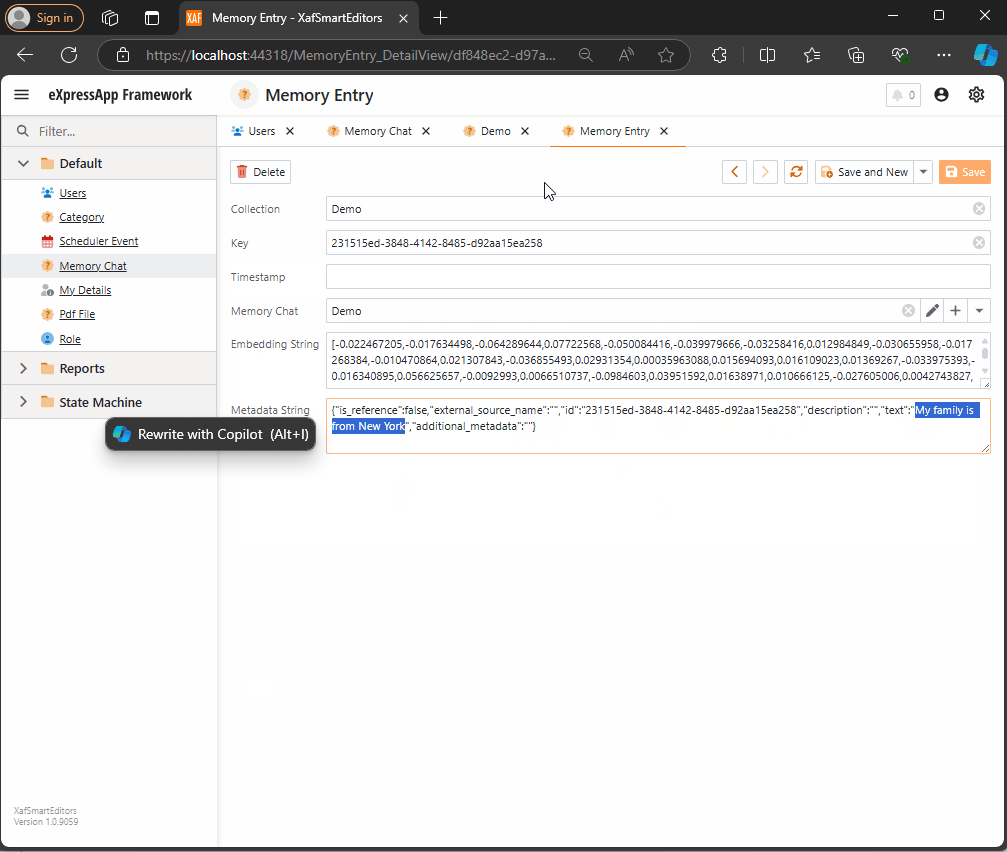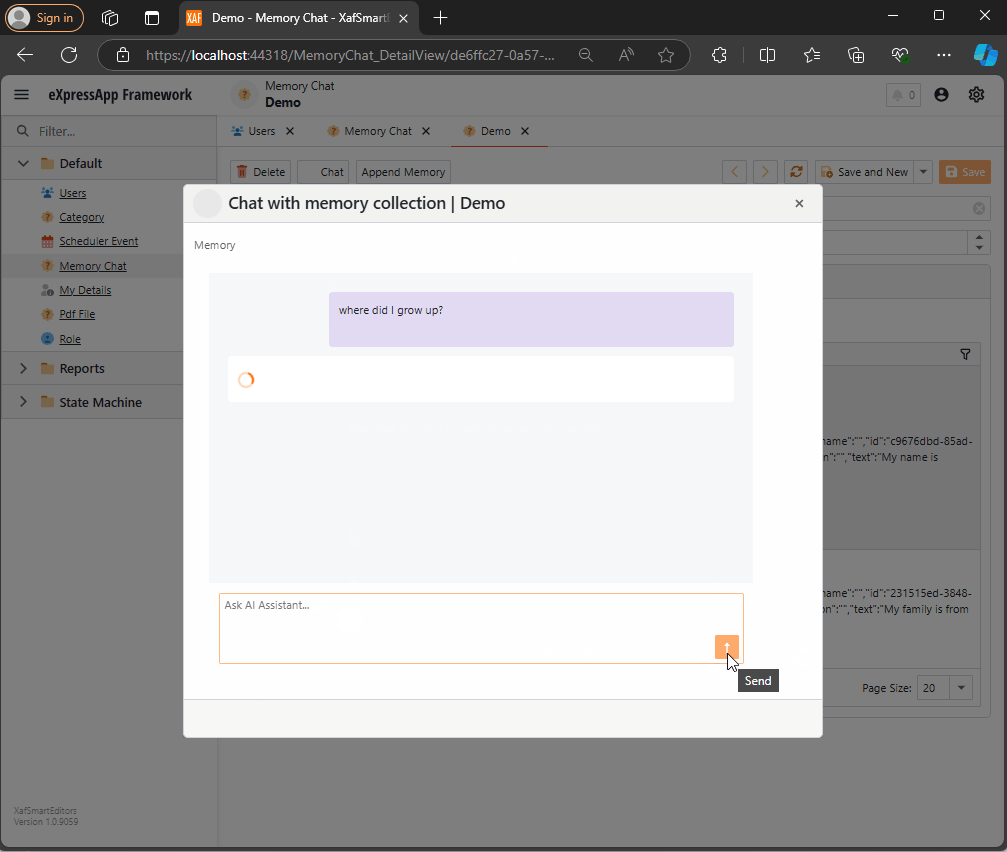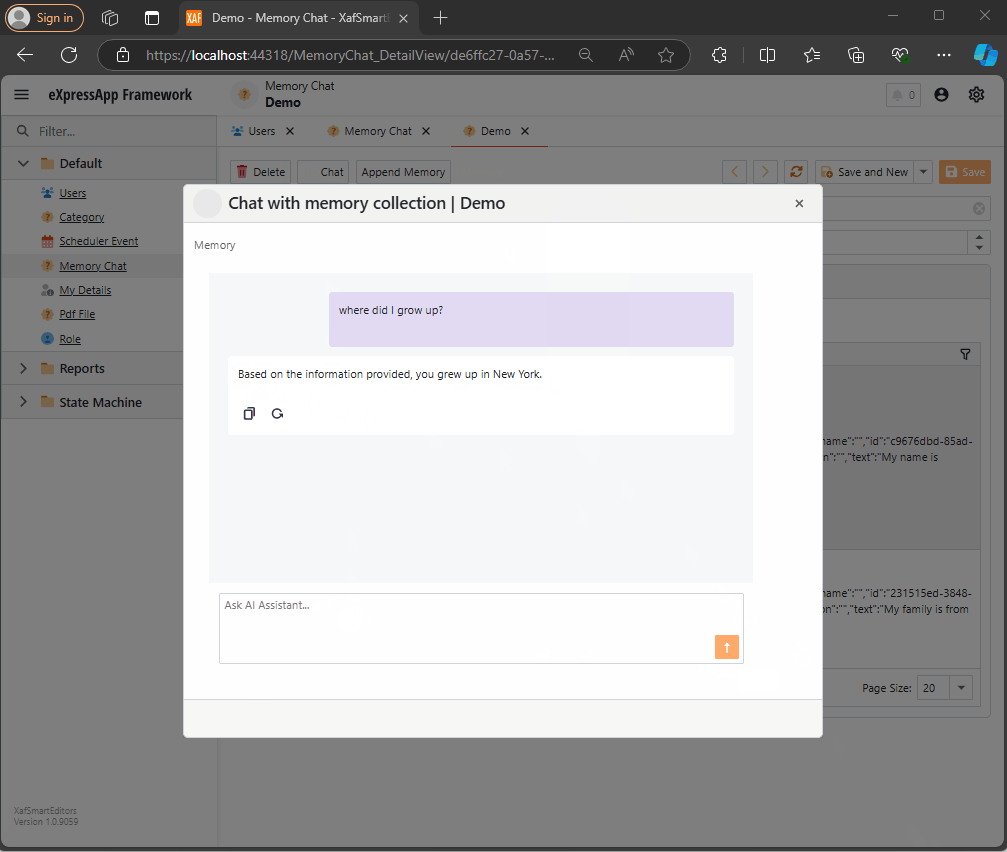
Step 1: Memory Collection Object
The first thing we need is an object that represents a collection of memories. Here’s the implementation:
[DefaultClassOptions]
public class MemoryChat : BaseObject
{
public MemoryChat(Session session) : base(session) {}
public override void AfterConstruction()
{
base.AfterConstruction();
this.MinimumRelevanceScore = 0.20;
}
double minimumRelevanceScore;
string name;
[Size(SizeAttribute.DefaultStringMappingFieldSize)]
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public double MinimumRelevanceScore
{
get => minimumRelevanceScore;
set => SetPropertyValue(nameof(MinimumRelevanceScore), ref minimumRelevanceScore, value);
}
[Association("MemoryChat-MemoryEntries")]
public XPCollection<MemoryEntry> MemoryEntries
{
get => GetCollection<MemoryEntry>(nameof(MemoryEntries));
}
}
This is a simple object. The two main properties are the MinimumRelevanceScore, which is used for similarity searches with embeddings, and the collection of MemoryEntries, where different memories are stored.
Step 2: Adding Memories
The next task is to easily append memories to that collection. I decided to use a non-persistent object displayed in a popup view with a large text area. When the user confirms the action in the dialog, the text gets vectorized and stored as a memory in the collection. You can see the implementation of the view controller here.
Let me highlight the important parts.
When we create the view for the popup window:
private void AppendMemory_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
var os = this.Application.CreateObjectSpace(typeof(TextMemory));
var textMemory = os.CreateObject<TextMemory>();
e.View = this.Application.CreateDetailView(os, textMemory);
}
The goal is to show a large textbox where the user can type any text. When they confirm, the text is vectorized and stored as a memory.
Next, storing the memory:
private async void AppendMemory_Execute(object sender, PopupWindowShowActionExecuteEventArgs e)
{
var textMemory = e.PopupWindowViewSelectedObjects[0] as TextMemory;
var currentMemoryChat = e.SelectedObjects[0] as MemoryChat;
var store = XpoMemoryStore.ConnectAsync(xafEntryManager).GetAwaiter().GetResult();
var semanticTextMemory = GetSemanticTextMemory(store);
await semanticTextMemory.SaveInformationAsync(currentMemoryChat.Name, id: Guid.NewGuid().ToString(), text: textMemory.Content);
}
Here, the GetSemanticTextMemory method plays a key role:
private static SemanticTextMemory GetSemanticTextMemory(XpoMemoryStore store)
{
var embeddingModelId = "text-embedding-3-small";
var getKey = () => Environment.GetEnvironmentVariable("OpenAiTestKey", EnvironmentVariableTarget.Machine);
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(ChatModelId, getKey.Invoke())
.AddOpenAITextEmbeddingGeneration(embeddingModelId, getKey.Invoke())
.Build();
var embeddingGenerator = new OpenAITextEmbeddingGenerationService(embeddingModelId, getKey.Invoke());
return new SemanticTextMemory(store, embeddingGenerator);
}
This method sets up an embedding generator used to create semantic memories.
Step 3: Querying Memories
To query the stored memories, I created a non-persistent type that interacts with the chat component:
public interface IMemoryData
{
IChatCompletionService ChatCompletionService { get; set; }
SemanticTextMemory SemanticTextMemory { get; set; }
string CollectionName { get; set; }
string Prompt { get; set; }
double MinimumRelevanceScore { get; set; }
}
This interface provides the necessary services to interact with the chat component, including ChatCompletionService and SemanticTextMemory.
Step 4: Handling Messages
Lastly, we handle message-sent callbacks, as explained in this article:
async Task MessageSent(MessageSentEventArgs args)
{
ChatHistory.AddUserMessage(args.Content);
var answers = Value.SemanticTextMemory.SearchAsync(
collection: Value.CollectionName,
query: args.Content,
limit: 1,
minRelevanceScore: Value.MinimumRelevanceScore,
withEmbeddings: true
);
string answerValue = "No answer";
await foreach (var answer in answers)
{
answerValue = answer.Metadata.Text;
}
string messageContent = answerValue == "No answer"
? "There are no memories containing the requested information."
: await Value.ChatCompletionService.GetChatMessageContentAsync($"You are an assistant queried for information. Use this data: {answerValue} to answer the question: {args.Content}.");
ChatHistory.AddAssistantMessage(messageContent);
args.SendMessage(new Message(MessageRole.Assistant, messageContent));
}
Here, we intercept the message, query the SemanticTextMemory, and use the results to generate an answer with the chat completion service.
This was a long post, but I hope it’s useful for you all. Until next time—XAF OUT!
You can find the full implementation on this repo

by Joche Ojeda | Oct 15, 2024 | A.I, Semantic Kernel, XAF, XPO
A few weeks ago, I forked the Semantic Kernel repository to experiment with it. One of my first experiments was to create a memory provider for XPO. The task was not too difficult; basically, I needed to implement the IMemoryStore interface, add some XPO boilerplate code, and just like that, we extended the Semantic Kernel memory store to support 10+ databases. You can check out the code for the XpoMemoryStore here.
My initial goal in creating the XpoMemoryStore was simply to see if XPO would be a good fit for handling embeddings. Spoiler alert: it was! To understand the basic functionality of the plugin, you can take a look at the integration test here.
As you can see, usage is straightforward. You start by connecting to the database that handles embedding collections, and all you need is a valid XPO connection string:
using XpoMemoryStore db = await XpoMemoryStore.ConnectAsync("XPO connection string");
In my original design, everything worked fine, but I faced some challenges when trying to use my new XpoMemoryStore in XAF. Here’s what I encountered:
- The implementation of XpoMemoryStore uses its own data layer, which can lead to issues. This needs to be rewritten to use the same data layer as XAF.
- The XpoEntry implementation cannot be extended. In some use cases, you might want to use a different object to store the embeddings, perhaps one that has an association with another object.
To address these problems, I introduced the IXpoEntryManager interface. The goal of this interface is to handle object creation and queries.
public interface IXpoEntryManager
{
T CreateObject();
public event EventHandler ObjectCreatedEvent;
void Commit();
IQueryable GetQuery(bool inTransaction = true);
void Delete(object instance);
void Dispose();
}
Now, object creation is handled through the CreateObject<T> method, allowing the underlying implementation to be changed to use a UnitOfWork or ObjectSpace. There’s also the ObjectCreatedEvent event, which lets you access the newly created object in case you need to associate it with another object. Lastly, the GetQuery<T> method enables redirecting the search for records to a different type.
I’ll keep updating the code as needed. If you’d like to discuss AI, XAF, or .NET, feel free to schedule a meeting: Schedule a Meeting with us.
Until next time, XAF out!
Related Article
https://www.jocheojeda.com/2024/09/04/using-the-imemorystore-interface-and-devexpress-xpo-orm-to-implement-a-custom-memory-store-for-semantic-kernel/
by Joche Ojeda | Oct 10, 2024 | A.I, PropertyEditors, XAF
The New Era of Smart Editors: Developer Express and AI Integration
The new era of smart editors is already here. Developer Express has introduced AI functionality in many of their controls for .NET (Windows Forms, Blazor, WPF, MAUI).
This advancement will eventually come to XAF, but in the meantime, here at XARI, we are experimenting with XAF integrations to add value to our customers.
In this article, we are going to integrate the new chat component into an XAF application, and our first use case will be RAG (Retrieval-Augmented Generation). RAG is a system that combines external data sources with AI-generated responses, improving accuracy and relevance in answers by retrieving information from a document set or knowledge base and using it in conjunction with AI predictions.
To achieve this integration, we will follow the steps outlined in this tutorial:
Implement a Property Editor Based on Custom Components (Blazor)
Implementing the Property Editor
When I implement my own property editor, I usually avoid doing so for primitive types because, in most cases, my property editor will need more information than a simple primitive value. For this implementation, I want to handle a custom value in my property editor. I typically create an interface to represent the type, ensuring compatibility with both XPO and EF Core.
namespace XafSmartEditors.Razor.RagChat
{
public interface IRagData
{
Stream FileContent { get; set; }
string Prompt { get; set; }
string FileName { get; set; }
}
}
Non-Persistent Implementation
After defining the type for my editor, I need to create a non-persistent implementation:
namespace XafSmartEditors.Razor.RagChat
{
[DomainComponent]
public class IRagDataImp : IRagData, IXafEntityObject, INotifyPropertyChanged
{
private void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
public IRagDataImp()
{
Oid = Guid.NewGuid();
}
[DevExpress.ExpressApp.Data.Key]
[Browsable(false)]
public Guid Oid { get; set; }
private string prompt;
private string fileName;
private Stream fileContent;
public Stream FileContent
{
get => fileContent;
set
{
if (fileContent == value) return;
fileContent = value;
OnPropertyChanged();
}
}
public string FileName
{
get => fileName;
set
{
if (fileName == value) return;
fileName = value;
OnPropertyChanged();
}
}
public string Prompt
{
get => prompt;
set
{
if (prompt == value) return;
prompt = value;
OnPropertyChanged();
}
}
// IXafEntityObject members
void IXafEntityObject.OnCreated() { }
void IXafEntityObject.OnLoaded() { }
void IXafEntityObject.OnSaving() { }
public event PropertyChangedEventHandler PropertyChanged;
}
}
Creating the Blazor Chat Component
Now, it’s time to create our Blazor component and add the new DevExpress chat component for Blazor:
<DxAIChat CssClass="my-chat" Initialized="Initialized"
RenderMode="AnswerRenderMode.Markdown"
UseStreaming="true"
SizeMode="SizeMode.Medium">
<EmptyMessageAreaTemplate>
<div class="my-chat-ui-description">
<span style="font-weight: bold; color: #008000;">Rag Chat</span> Assistant is ready to answer your questions.
</div>
</EmptyMessageAreaTemplate>
<MessageContentTemplate>
<div class="my-chat-content">
@ToHtml(context.Content)
</div>
</MessageContentTemplate>
</DxAIChat>
@code {
IRagData _value;
[Parameter]
public IRagData Value
{
get => _value;
set => _value = value;
}
async Task Initialized(IAIChat chat)
{
await chat.UseAssistantAsync(new OpenAIAssistantOptions(
this.Value.FileName,
this.Value.FileContent,
this.Value.Prompt
));
}
MarkupString ToHtml(string text)
{
return (MarkupString)Markdown.ToHtml(text);
}
}
The main takeaway from this component is that it receives a parameter named Value of type IRagData, and we use this value to initialize the IAIChat service in the Initialized method.
Creating the Component Model
With the interface and domain component in place, we can now create the component model to communicate the value of our domain object with the Blazor component:
namespace XafSmartEditors.Razor.RagChat
{
public class RagDataComponentModel : ComponentModelBase
{
public IRagData Value
{
get => GetPropertyValue<IRagData>();
set => SetPropertyValue(value);
}
public EventCallback<IRagData> ValueChanged
{
get => GetPropertyValue<EventCallback<IRagData>>();
set => SetPropertyValue(value);
}
public override Type ComponentType => typeof(RagChat);
}
}
Creating the Property Editor
Finally, let’s create the property editor class that serves as a bridge between XAF and the new component:
namespace XafSmartEditors.Blazor.Server.Editors
{
[PropertyEditor(typeof(IRagData), true)]
public class IRagDataPropertyEditor : BlazorPropertyEditorBase, IComplexViewItem
{
private IObjectSpace _objectSpace;
private XafApplication _application;
public IRagDataPropertyEditor(Type objectType, IModelMemberViewItem model) : base(objectType, model) { }
public void Setup(IObjectSpace objectSpace, XafApplication application)
{
_objectSpace = objectSpace;
_application = application;
}
public override RagDataComponentModel ComponentModel => (RagDataComponentModel)base.ComponentModel;
protected override IComponentModel CreateComponentModel()
{
var model = new RagDataComponentModel();
model.ValueChanged = EventCallback.Factory.Create<IRagData>(this, value =>
{
model.Value = value;
OnControlValueChanged();
WriteValue();
});
return model;
}
protected override void ReadValueCore()
{
base.ReadValueCore();
ComponentModel.Value = (IRagData)PropertyValue;
}
protected override object GetControlValueCore() => ComponentModel.Value;
protected override void ApplyReadOnly()
{
base.ApplyReadOnly();
ComponentModel?.SetAttribute("readonly", !AllowEdit);
}
}
}
Bringing It All Together
Now, let’s create a domain object that can feed the content of a file to our chat component:
namespace XafSmartEditors.Module.BusinessObjects
{
[DefaultClassOptions]
public class PdfFile : BaseObject
{
public PdfFile(Session session) : base(session) { }
string prompt;
string name;
FileData file;
public FileData File
{
get => file;
set => SetPropertyValue(nameof(File), ref file, value);
}
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public string Prompt
{
get => prompt;
set => SetPropertyValue(nameof(Prompt), ref prompt, value);
}
}
}
Creating the Controller
We are almost done! Now, we need to create a controller with a popup action:
namespace XafSmartEditors.Module.Controllers
{
public class OpenChatController : ViewController
{
Popup
WindowShowAction Chat;
public OpenChatController()
{
this.TargetObjectType = typeof(PdfFile);
Chat = new PopupWindowShowAction(this, "ChatAction", "View");
Chat.Caption = "Chat";
Chat.ImageName = "artificial_intelligence";
Chat.Execute += Chat_Execute;
Chat.CustomizePopupWindowParams += Chat_CustomizePopupWindowParams;
}
private void Chat_Execute(object sender, PopupWindowShowActionExecuteEventArgs e) { }
private void Chat_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
PdfFile pdfFile = this.View.CurrentObject as PdfFile;
var os = this.Application.CreateObjectSpace(typeof(ChatView));
var chatView = os.CreateObject<ChatView>();
MemoryStream memoryStream = new MemoryStream();
pdfFile.File.SaveToStream(memoryStream);
memoryStream.Seek(0, SeekOrigin.Begin);
chatView.RagData = os.CreateObject<IRagDataImp>();
chatView.RagData.FileName = pdfFile.File.FileName;
chatView.RagData.Prompt = !string.IsNullOrEmpty(pdfFile.Prompt) ? pdfFile.Prompt : DefaultPrompt;
chatView.RagData.FileContent = memoryStream;
DetailView detailView = this.Application.CreateDetailView(os, chatView);
detailView.Caption = $"Chat with Document | {pdfFile.File.FileName.Trim()}";
e.View = detailView;
}
}
}
Conclusion
That’s everything we need to create a RAG system using XAF and the new DevExpress Chat component. You can find the complete source code here: GitHub Repository.
If you want to meet and discuss AI, XAF, and .NET, feel free to schedule a meeting: Schedule a Meeting.
Until next time, XAF out!

by Joche Ojeda | Jun 21, 2024 | Database, ORM
Why Compound Keys in Database Tables Are No Longer Valid
Introduction
In the realm of database design, compound keys were once a staple, largely driven by the need to adhere to normalization forms. However, the evolving landscape of technology and data management calls into question the continued relevance of these multi-attribute keys. This article explores the reasons why compound keys may no longer be the best choice and suggests a shift towards simpler, more maintainable alternatives like object identifiers (OIDs).
The Case Against Compound Keys
Complexity in Database Design
- Normalization Overhead: Historically, compound keys were used to satisfy normalization requirements, ensuring minimal redundancy and dependency. While normalization is still important, the rigidity it imposes can lead to overly complex database schemas.
- Business Logic Encapsulation: When compound keys include business logic, they can create dependencies that complicate data integrity and maintenance. Changes in business rules often necessitate schema alterations, which can be cumbersome.
Maintenance Challenges
- Data Integrity Issues: Compound keys can introduce challenges in maintaining data integrity, especially in large and complex databases. Ensuring the uniqueness and consistency of multi-attribute keys can be error-prone.
- Performance Concerns: Queries involving compound keys can become less efficient, as indexing and searching across multiple columns can be more resource-intensive compared to single-column keys.
The Shift Towards Object Identifiers (OIDs)
Simplified Design
- Single Attribute Keys: Using OIDs as primary keys simplifies the schema. Each row can be uniquely identified by a single attribute, making the design more straightforward and easier to understand.
- Decoupling Business Logic: OIDs help in decoupling the business logic from the database schema. Changes in business rules do not necessitate changes in the primary key structure, enhancing flexibility.
Easier Maintenance
- Improved Data Integrity: With a single attribute as the primary key, maintaining data integrity becomes more manageable. The likelihood of key conflicts is reduced, simplifying the validation process.
- Performance Optimization: OIDs allow for more efficient indexing and query performance. Searching and sorting operations are faster and less resource-intensive, improving overall database performance.
Revisiting Normalization
Historical Context
- Storage Constraints: Normalization rules were developed when data storage was expensive and limited. Reducing redundancy and optimizing storage was paramount.
- Modern Storage Solutions: Today, storage is relatively cheap and abundant. The strict adherence to normalization may not be as critical as it once was.
Balancing Act
- De-normalization for Performance: In modern databases, a balance between normalization and de-normalization can be beneficial. De-normalization can improve performance and simplify query design without significantly increasing storage costs.
- Practical Normalization: Applying normalization principles should be driven by practical needs rather than strict adherence to theoretical models. The goal is to achieve a design that is both efficient and maintainable.
ORM Design Preferences
Object-Relational Mappers (ORMs)
- Design with OIDs in Mind: Many ORMs, such as XPO from DevExpress, were originally designed to work with OIDs rather than compound keys. This preference simplifies database interaction and enhances compatibility with object-oriented programming paradigms.
- Support for Compound Keys: Although these ORMs support compound keys, their architecture and default behavior often favor the use of single-column OIDs, highlighting the practical advantages of simpler key structures in modern application development.
Conclusion
The use of compound keys in database tables, driven by the need to fulfill normalization forms, may no longer be the best practice in modern database design. Simplifying schemas with object identifiers can enhance maintainability, improve performance, and decouple business logic from the database structure. As storage becomes less of a constraint, a pragmatic approach to normalization, balancing performance and data integrity, becomes increasingly important. Embracing these changes, along with leveraging ORM tools designed with OIDs in mind, can lead to more robust, flexible, and efficient database systems.

by Joche Ojeda | May 29, 2023 | Uncategorized
SOLID is an acronym that stands for five fundamental principles of object-oriented programming and design. These principles were first introduced by Robert C. Martin (also known as Uncle Bob) and have since become a cornerstone of software development best practices. Each letter in SOLID represents a principle that, when applied correctly, leads to more maintainable and modular code.
Let’s dive into each of the SOLID principles and understand how they contribute to building high-quality software systems:
Single Responsibility Principle (SRP):
The SRP states that a class should have only one reason to change. In other words, a class should have a single responsibility or a single job. This principle encourages developers to break down complex systems into smaller, cohesive modules. By ensuring that each class has a focused responsibility, it becomes easier to understand, test, and modify the code without affecting other parts of the system.
Open-Closed Principle (OCP):
The OCP promotes the idea that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. This principle emphasizes the importance of designing systems that can be easily extended with new functionality without modifying existing code. By relying on abstractions, interfaces, and inheritance, developers can add new features by writing new code rather than changing the existing one. This approach reduces the risk of introducing bugs or unintended side effects.
Liskov Substitution Principle (LSP):
The LSP states that objects of a superclass should be replaceable with objects of its subclasses without affecting the correctness of the program. In simpler terms, if a class is a subtype of another class, it should be able to be used interchangeably with its parent class without causing any issues. This principle ensures that inheritance hierarchies are well-designed, avoiding situations where subclass behavior contradicts or breaks the functionality defined by the superclass. Adhering to the LSP leads to more flexible and reusable code.
Interface Segregation Principle (ISP):
The ISP advises developers to design interfaces that are specific to the needs of the clients that use them. It suggests that clients should not be forced to depend on interfaces they don’t use. By creating small and focused interfaces, rather than large and monolithic ones, the ISP enables clients to be decoupled from unnecessary dependencies. This principle enhances modularity, testability, and maintainability, as changes to one part of the system are less likely to impact other parts.
Dependency Inversion Principle (DIP):
The DIP encourages high-level modules to depend on abstractions rather than concrete implementations. It states that high-level modules should not depend on low-level modules; both should depend on abstractions. This principle promotes loose coupling between components, making it easier to substitute or modify dependencies without affecting the overall system. By relying on interfaces or abstract classes, the DIP facilitates extensibility, testability, and the ability to adapt to changing requirements.
By applying the SOLID principles, software engineers can create codebases that are modular, flexible, and easy to maintain. These principles provide a roadmap for designing systems that are resilient to change, promote code reusability, and improve collaboration among development teams. SOLID principles are not strict rules but rather guidelines that help developers make informed design decisions and create high-quality software systems.
It’s worth mentioning that the SOLID principles should not be applied blindly in all situations. Context matters, and there may be scenarios where strict adherence to one principle might not be the best approach. However, understanding and incorporating these principles into the software design process can significantly improve the overall quality of the codebase.
SOLID and XPO
XPO is designed with SOLID design principles in mind. Here’s how XPO applies each of the SOLID principles:
Single Responsibility Principle (SRP)
XPO uses separate classes for each major concern such as mapping, persistence, connection providers, and data access. Each class has a clearly defined purpose and responsibility.
Open-Closed Principle (OCP)
XPO is extensible and customizable, allowing you to create your own classes and derive them from the XPO base classes. XPO also provides a range of extension points and hooks to allow for customization and extension without modifying the core XPO code.
Liskov Substitution Principle (LSP)
XPO follows this principle by providing a uniform API that works with all persistent objects, regardless of their concrete implementation. This allows you to write code that works with any persistent object, without having to worry about the specific implementation details.
Interface Segregation Principle (ISP)
XPO provides a number of interfaces that define specific aspects of its behavior, allowing clients to use only the interfaces they need. This reduces the coupling between the clients and the XPO library.
Dependency Inversion Principle (DIP)
XPO was developed prior to the widespread popularity of Dependency Injection (DI) patterns and frameworks.
As a result, XPO does not incorporate DI as a built-in feature. However, this does not mean that XPO cannot be used in conjunction with DI. While XPO itself does not provide direct support for DI, you can still integrate it with popular DI containers or frameworks, such as the .NET Core DI container or any other one.
By integrating XPO with a DI container, you can leverage the benefits of DI principles in your application while utilizing XPO’s capabilities for database access and mapping. The DI container can handle the creation and management of XPO-related objects, facilitating loose coupling, improved modularity, and simplified testing.
A clear example is the XPO Extensions for ASP.NET Core DI:
using DevExpress.Xpo.DB;
Using Microsoft.Extensions.DependencyInjection; // ...
var builder = WebApplication.CreateBuilder(args); builder.Services.AddXpoDefaultUnitOfWork(true, options => options.UseConnectionString(builder.Configuration.GetConnectionString("MSSqlServer")) .UseAutoCreationOption(AutoCreateOption.DatabaseAndSchema) .UseEntityTypes(new Type[] { typeof(User) }));
More information about XPO and DI here: https://docs.devexpress.com/XPO/403009/connect-to-a-data-store/xpo-extensions-for-aspnet-core-di
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
What is an O.R.M (Object-Relational Mapping)
ADO The origin of data access in .NET
Relational database systems: the holy grail of data