
by Joche Ojeda | Dec 2, 2024 | Blazor
Over time, I transitioned to using the first versions of my beloved framework, XAF. As you might know, XAF generates a polished and functional UI out of the box. Using XAF made me more of a backend developer since most of the development work wasn’t visual—especially in the early versions, where the model designer was rudimentary (it’s much better now).
Eventually, I moved on to developing .NET libraries and NuGet packages, diving deep into SOLID design principles. Fun fact: I actually learned about SOLID from DevExpress TV. Yes, there was a time before YouTube when DevExpress posted videos on technical tasks!
Nowadays, I feel confident creating and publishing my own libraries as NuGet packages. However, my “old monster” was still lurking in the shadows: UI components. I finally decided it was time to conquer it, but first, I needed to choose a platform. Here were my options:
- Windows Forms: A robust and mature platform but limited to desktop applications.
- WPF: A great option with some excellent UI frameworks that I love, but it still feels a bit “Windows Forms-ish” to me.
- Xamarin/Maui: I’m a big fan of Xamarin Forms and Xamarin/Maui XAML, but they’re primarily focused on device-specific applications.
- Blazor: This was the clear winner because it allows me to create desktop applications using Electron, embed components into Windows Forms, or even integrate with MAUI.
Recently, I’ve been helping my brother with a project in Blazor. (He’s not a programmer, but I am.) This gave me an opportunity to experiment with design patterns to get the most out of my components, which started as plain HTML5 pages.
Without further ado, here are the key insights I’ve gained so far.
Building high-quality Blazor components requires attention to both the C# implementation and Razor markup patterns. This guide combines architectural best practices with practical implementation patterns to create robust, reusable components.
1. Component Architecture and Organization
Parameter Organization
Start by organizing parameters into logical groups for better maintainability:
public class CustomForm : ComponentBase
{
// Layout Parameters
[Parameter] public string Width { get; set; }
[Parameter] public string Margin { get; set; }
[Parameter] public string Padding { get; set; }
// Validation Parameters
[Parameter] public bool EnableValidation { get; set; }
[Parameter] public string ValidationMessage { get; set; }
// Event Callbacks
[Parameter] public EventCallback<bool> OnValidationComplete { get; set; }
[Parameter] public EventCallback<string> OnSubmit { get; set; }
}
Corresponding Razor Template
<div class="form-container" style="width: @Width; margin: @Margin; padding: @Padding">
<form @onsubmit="HandleSubmit">
@if (EnableValidation)
{
<div class="validation-message">
@ValidationMessage
</div>
}
@ChildContent
</form>
</div>
2. Smart Default Values and Template Composition
Component Implementation
public class DataTable<T> : ComponentBase
{
[Parameter] public int PageSize { get; set; } = 10;
[Parameter] public bool ShowPagination { get; set; } = true;
[Parameter] public string EmptyMessage { get; set; } = "No data available";
[Parameter] public IEnumerable<T> Items { get; set; } = Array.Empty<T>();
[Parameter] public RenderFragment HeaderTemplate { get; set; }
[Parameter] public RenderFragment<T> RowTemplate { get; set; }
[Parameter] public RenderFragment FooterTemplate { get; set; }
}
Razor Implementation
<div class="table-container">
@if (HeaderTemplate != null)
{
<header class="table-header">
@HeaderTemplate
</header>
}
<div class="table-content">
@if (!Items.Any())
{
<div class="empty-state">@EmptyMessage</div>
}
else
{
@foreach (var item in Items)
{
@RowTemplate(item)
}
}
</div>
@if (ShowPagination)
{
<div class="pagination">
<!-- Pagination implementation -->
</div>
}
</div>
3. Accessibility and Unique IDs
Component Implementation
public class FormField : ComponentBase
{
private string fieldId = $"field-{Guid.NewGuid():N}";
private string labelId = $"label-{Guid.NewGuid():N}";
private string errorId = $"error-{Guid.NewGuid():N}";
[Parameter] public string Label { get; set; }
[Parameter] public string Error { get; set; }
[Parameter] public bool Required { get; set; }
}
Razor Implementation
<div class="form-field">
<label id="@labelId" for="@fieldId">
@Label
@if (Required)
{
<span class="required" aria-label="required">*</span>
}
</label>
<input id="@fieldId"
aria-labelledby="@labelId"
aria-describedby="@errorId"
aria-required="@Required" />
@if (!string.IsNullOrEmpty(Error))
{
<div id="@errorId" class="error-message" role="alert">
@Error
</div>
}
</div>
4. Virtualization and Performance
Component Implementation
public class VirtualizedList<T> : ComponentBase
{
[Parameter] public IEnumerable<T> Items { get; set; }
[Parameter] public RenderFragment<T> ItemTemplate { get; set; }
[Parameter] public int ItemHeight { get; set; } = 50;
[Parameter] public Func<ItemsProviderRequest, ValueTask<ItemsProviderResult<T>>> ItemsProvider { get; set; }
}
Razor Implementation
<div class="virtualized-container" style="height: 500px; overflow-y: auto;">
<Virtualize Items="@Items"
ItemSize="@ItemHeight"
ItemsProvider="@ItemsProvider"
Context="item">
<ItemContent>
<div class="list-item" style="height: @(ItemHeight)px">
@ItemTemplate(item)
</div>
</ItemContent>
<Placeholder>
<div class="loading-placeholder" style="height: @(ItemHeight)px">
<div class="loading-animation"></div>
</div>
</Placeholder>
</Virtualize>
</div>
Best Practices Summary
1. Parameter Organization
- Group related parameters with clear comments
- Provide meaningful default values
- Use parameter validation where appropriate
2. Template Composition
- Use RenderFragment for customizable sections
- Provide default templates when needed
- Enable granular control over component appearance
3. Accessibility
- Generate unique IDs for form elements
- Include proper ARIA attributes
- Support keyboard navigation
4. Performance
- Implement virtualization for large datasets
- Use loading states and placeholders
- Optimize rendering with appropriate conditions
Conclusion
Building effective Blazor components requires attention to both the C# implementation and Razor markup. By following these patterns and practices, you can create components that are:
- Highly reusable
- Performant
- Accessible
- Easy to maintain
- Flexible for different use cases
Remember to adapt these practices to your specific needs while maintaining clean component design principles.
by Joche Ojeda | Nov 2, 2024 | A.I, Semantic Kernel
Today, when I woke up, it was sunny but really cold, and the weather forecast said that snow was expected.
So, I decided to order ramen and do a “Saturday at home” type of project. My tools of choice for this experiment are:
1) DevExpress Chat Component for Blazor
I’m thrilled they have this component. I once wrote my own chat component, and it’s a challenging task, especially given the variety of use cases.
2) Semantic Kernel
I’ve been experimenting with Semantic Kernel for a while now, and let me tell you—it’s a fantastic tool if you’re in the .NET ecosystem. It’s so cool to have native C# code to interact with AI services in a flexible way, making your code mostly agnostic to the AI provider—like a WCF for AIs.
Goal of the Experiment
The goal for today’s experiment is to render a list of products as a carousel within a chat conversation.
Configuration
To accomplish this, I’ll use prompt execution settings in Semantic Kernel to ensure that the response from the LLM is always in JSON format as a string.
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
The key part here is the response format. The chat completion can respond in two ways:
- Text: A simple text answer.
- JSON Object: This format always returns a JSON object, with the structure provided as part of the prompt.
With this approach, we can deserialize the LLM’s response to an object that helps conditionally render the message content within the DevExpress Chat Component.
Structure
Here’s the structure I’m using:
public class MessageData
{
public string Message { get; set; }
public List Options { get; set; }
public string MessageTemplateName { get; set; }
}
public class OptionSet
{
public string Name { get; set; }
public string Description { get; set; }
public List Options { get; set; }
}
public class Option
{
public string Image { get; set; }
public string Url { get; set; }
public string Description { get; set; }
};
- MessageData: This structure will always be returned by our LLM.
- Option: A list of options for a message, which also serves as data for possible responses.
- OptionSet: A list of possible responses to feed into the prompt execution settings.
Prompt Execution Settings
One more step on the Semantic Kernel side is configuring the prompt execution settings:
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
Settings.ChatSystemPrompt = $"You need to answer using this JSON format with this structure {Structure} " +
$"Before giving an answer, check if it exists within this list of option sets {OptionSets}. " +
$"If your answer does not include options, the message template value should be 'Message'; otherwise, it should be 'Options'.";
In the prompt, we specify the structure {Structure} we want as a response, provide a list of possible options for the message in the {OptionSets} variable, and add a final line to guide the LLM on which template type to use.
Example Requests and Responses
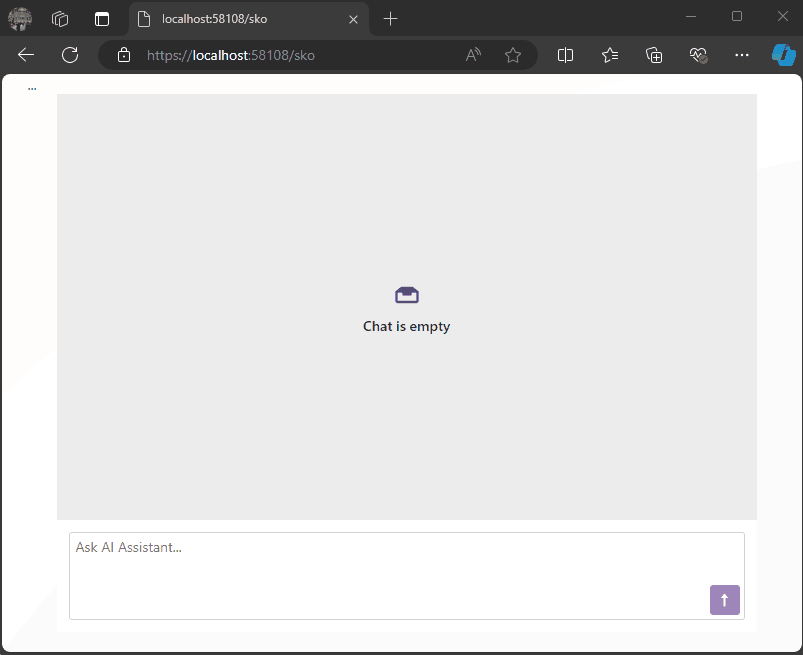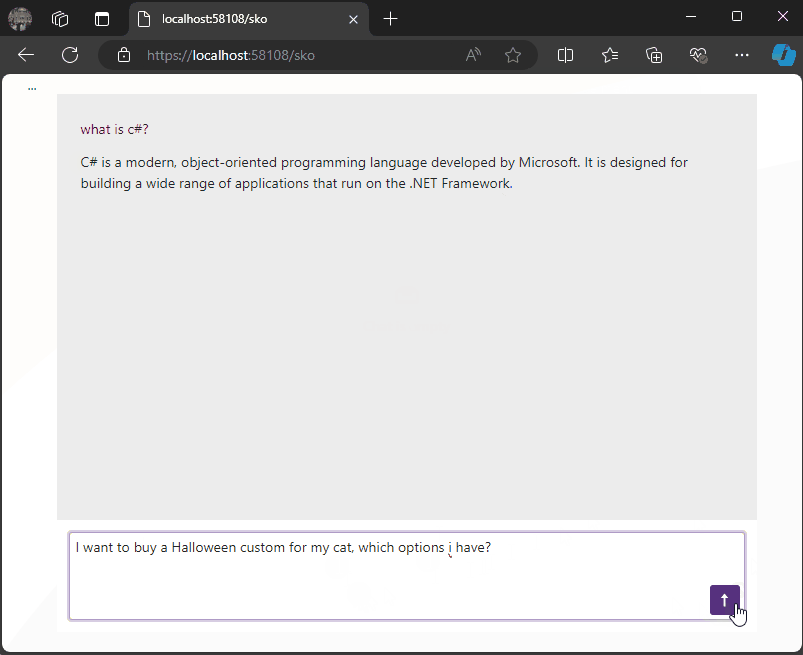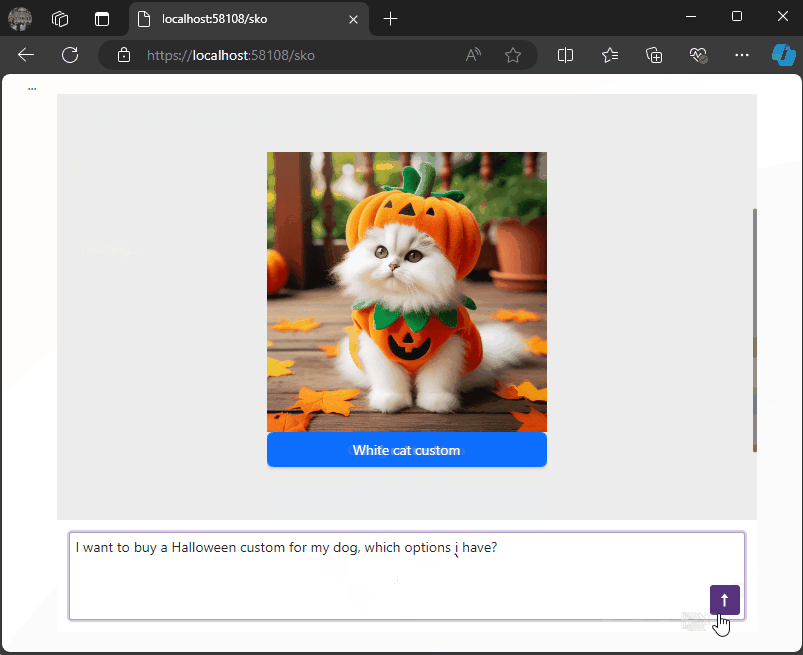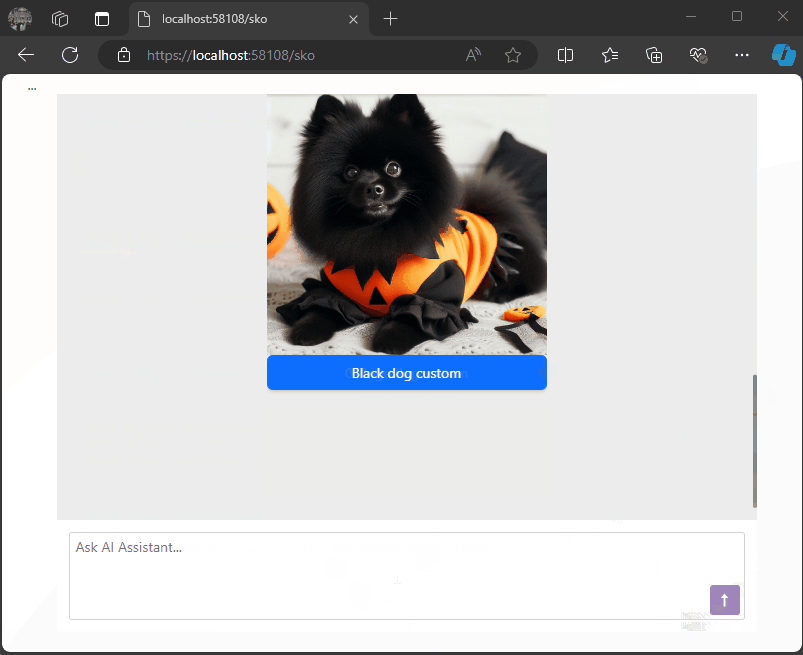
For example, when executing the following request:
- Prompt: “Show me a list of Halloween costumes for cats.”
We’ll get this response from the LLM:
{
"Message": "Please select one of the Halloween costumes for cats",
"Options": [
{"Image": "./images/catblack.png", "Url": "https://cat.com/black", "Description": "Black cat costume"},
{"Image": "./images/catwhite.png", "Url": "https://cat.com/white", "Description": "White cat costume"},
{"Image": "./images/catorange.png", "Url": "https://cat.com/orange", "Description": "Orange cat costume"}
],
"MessageTemplateName": "Options"
}
With this JSON structure, we can conditionally render messages in the chat component as follows:
<DxAIChat CssClass="my-chat" MessageSent="MessageSent">
<MessageTemplate>
<div>
@{
if (@context.Typing)
{
<span>Loading...</span>
}
else
{
MessageData md = null;
try
{
md = JsonSerializer.Deserialize<MessageData>(context.Content);
}
catch
{
md = null;
}
if (md == null)
{
<div class="my-chat-content">
@context.Content
</div>
}
else
{
if (md.MessageTemplateName == "Options")
{
<div class="centered-carousel">
<Carousel class="carousel-container" Width="280" IsFade="true">
@foreach (var option in md.Options)
{
<CarouselItem>
<ChildContent>
<div>
<img src="@option.Image" alt="demo-image" />
<Button Color="Color.Primary" class="carousel-button">@option.Description</Button>
</div>
</ChildContent>
</CarouselItem>
}
</Carousel>
</div>
}
else if (md.MessageTemplateName == "Message")
{
<div class="my-chat-content">
@md.Message
</div>
}
}
}
}
</div>
</MessageTemplate>
</DxAIChat>
End Solution Example
Here’s an example of the final solution:
You can find the full source code here: https://github.com/egarim/devexpress-ai-chat-samples and a short video here https://youtu.be/dxMnOWbe3KA
by Joche Ojeda | Oct 30, 2024 | Uncategorized
Lately, I’ve been working extensively on interacting with LLMs using the Semantic Kernel framework. My experiments usually start as NUnit test projects, where I prototype my ideas.
Once an experiment is successful, I move it to XAF. Recently, I faced challenges with executing asynchronous code and updating the XAF UI. This process is tricky because some solutions might appear to work but fail under certain conditions.
Goals
Here’s what I aim to achieve:
- Execute asynchronous code within the execute handler of an action.
- Notify the UI and access the current view, object, and object space.
- Run multiple operations on a background thread.
For more background, check out these links on async executions within XAF actions:
WebForms
Blazor
Complete source code for this test can be found on GitHub.
Common Cases
1. Blocking the UI Thread (this will not work)
If you don’t make your action async, attempting to get the awaiter will block the UI thread, freezing your application.
ActionBlockUIThread = new SimpleAction(this, nameof(ActionBlockUIThread), "View");
ActionBlockUIThread.Execute += ActionBlockUIThread_Execute;
protected virtual void ActionBlockUIThread_Execute(object sender, SimpleActionExecuteEventArgs e) {
var Tasks = GetTaskList();
StringBuilder Results = new StringBuilder();
foreach (var item in Tasks) {
Results.AppendLine(item.Invoke().GetAwaiter().GetResult().ToString());
}
MessageOptions options = new MessageOptions { Duration = 2000, Message = Results.ToString(), Type = InformationType.Success };
Application.ShowViewStrategy.ShowMessage(options);
}
2. Using Async Modifier (somehow works)
Marking your handler as async prevents blocking but keeps the UI responsive, which can allow the user to modify or navigate away from the current view, causing exceptions.
protected virtual async void ActionWithAsyncModifier_Execute(object sender, SimpleActionExecuteEventArgs e) {
var Tasks = GetTaskList();
StringBuilder Results = new StringBuilder();
foreach (var item in Tasks) {
var CurrentResult = await item.Invoke();
Results.AppendLine(CurrentResult.ToString());
}
MessageOptions options = new MessageOptions { Duration = 2000, Message = Results.ToString(), Type = InformationType.Success };
Application.ShowViewStrategy.ShowMessage(options);
}
A slightly modified Blazor version of this code also illustrates similar issues.
Executing Object Space Operations Inside Async Action, things that can happen
This approach still leaves the UI responsive, risking disposal of object space if the user navigates away, if that happens you will end up with an exception
protected virtual async void ActionWithAsyncModifierAndOsOperations_Execute(object sender, SimpleActionExecuteEventArgs e) {
var Instance = GetInstance();
var Tasks = GetTaskList();
StringBuilder Results = new StringBuilder();
foreach (var item in Tasks) {
var CurrentResult = await item.Invoke();
Results.AppendLine(CurrentResult.ToString());
}
Instance.Result = Results.ToString();
ViewCommit();
MessageOptions options = new MessageOptions { Duration = 3000, Message = Instance.Result, Type = InformationType.Success };
Application.ShowViewStrategy.ShowMessage(options);
}
Proposed Solution
My solution utilizes a background worker to handle async operations while locking the UI thread with a loading indicator. This allows us to react to progress on the UI thread.
Async Background Worker Example
Here’s how the AsyncBackgroundWorker is set up and used:
protected virtual void AsyncActionWithAsyncBackgroundWorker_Execute(object sender, SimpleActionExecuteEventArgs e) {
var tasks = GetTaskList();
var worker = new AsyncBackgroundWorker
Handling Background Worker Events
protected virtual void ProcessingDone(Dictionary<int, object> results) {
// Interact with UI and object space
}
protected virtual void OnReportProgress(int progress, string status, object result) {
MessageOptions options = new MessageOptions { Duration = 2000, Message = status, Type = InformationType.Success };
Application.ShowViewStrategy.ShowMessage(options);
}
Blazor Implementation
The Blazor version manages UI locking by showing a loading indicator and reporting progress through the UI thread:
source here: https://github.com/egarim/XafAsyncActions/blob/master/XafAsyncActions.Blazor.Server/Controllers/MyViewControllerBlazor.cs
protected async override void AsyncActionWithAsyncBackgroundWorker_Execute(object sender, SimpleActionExecuteEventArgs e) {
loading.Hold("Loading");
base.AsyncActionWithAsyncBackgroundWorker_Execute(sender, e);
}
protected async override void ProcessingDone(Dictionary<int, object> results) {
base.ProcessingDone(results);
loading.Release("Loading");
}
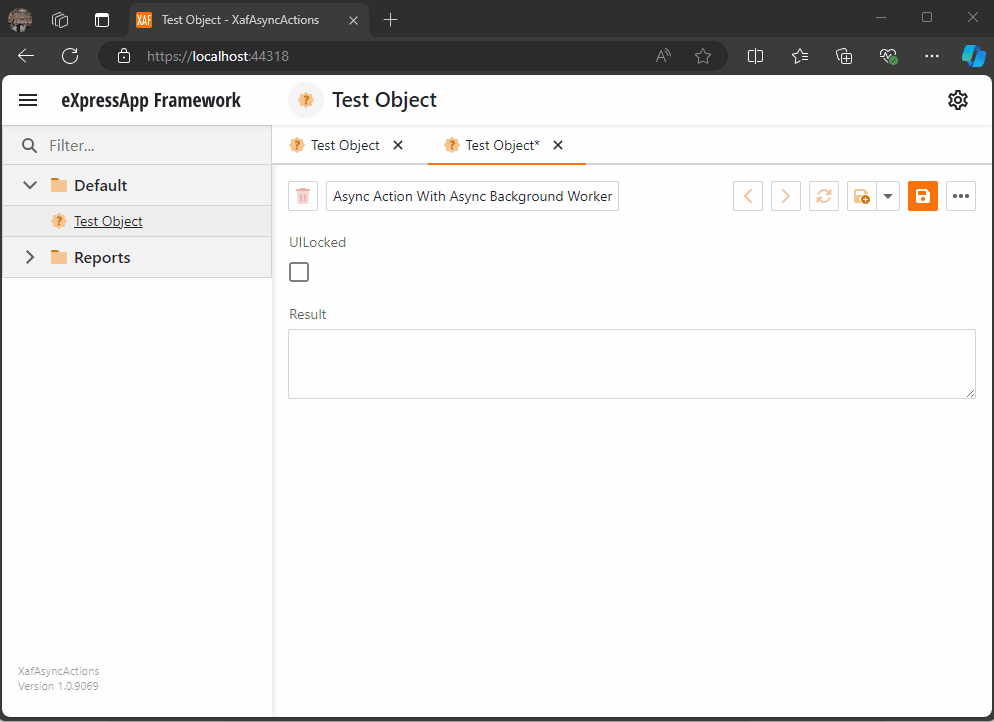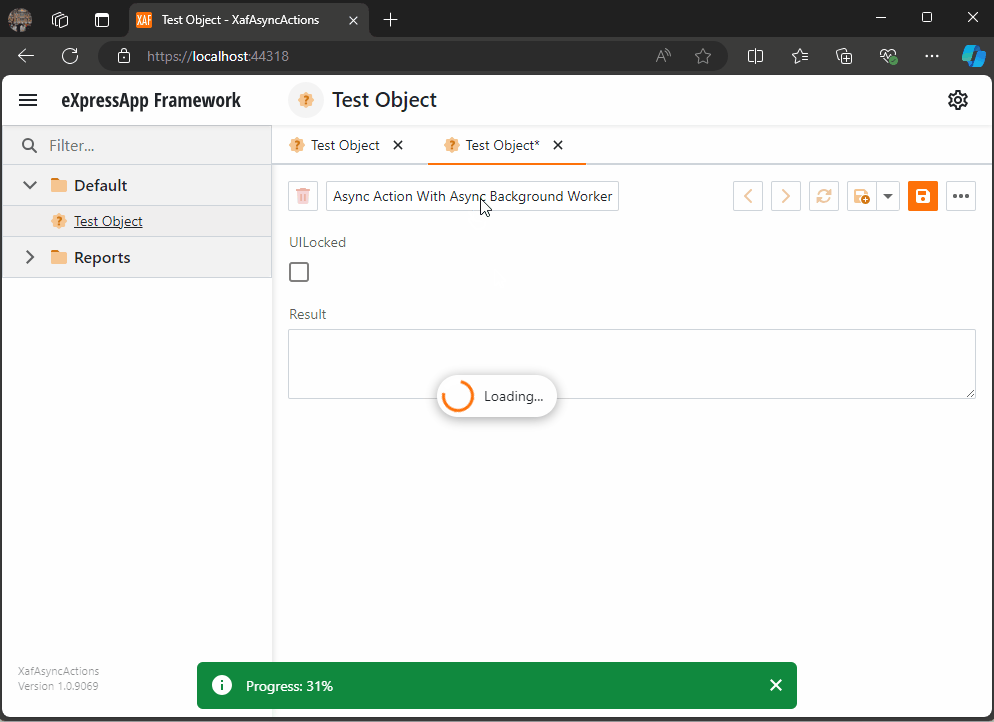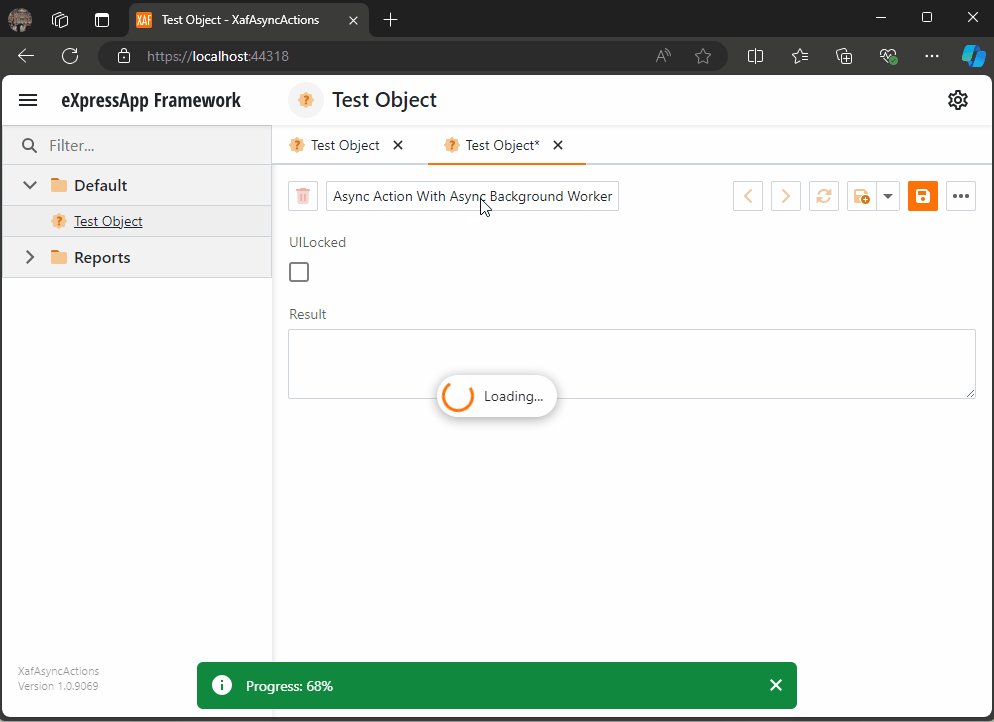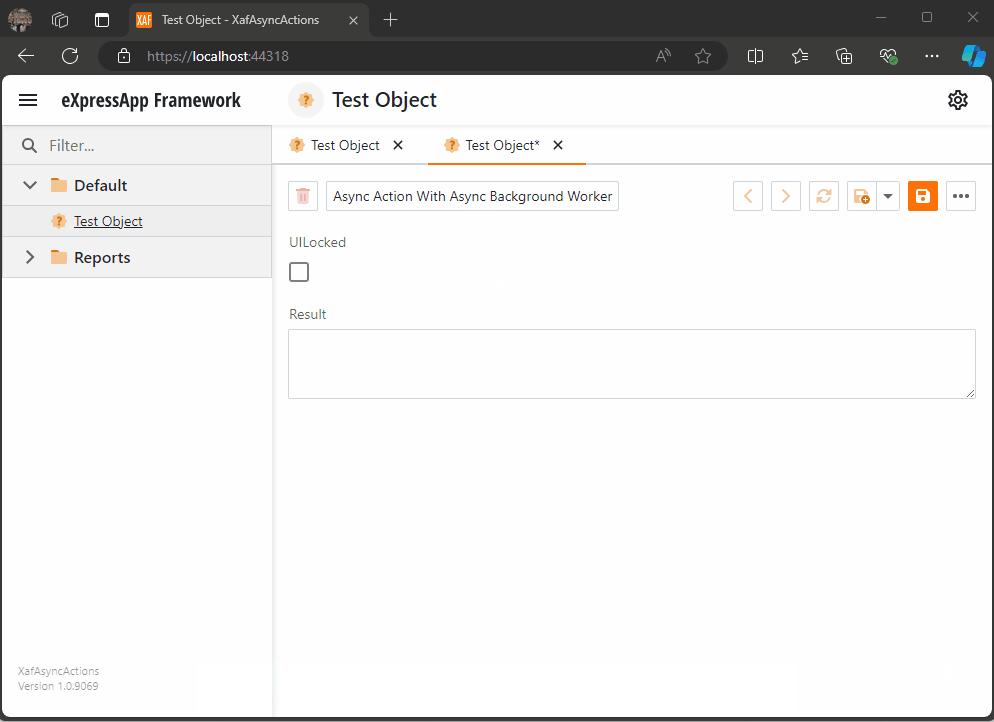
When you run this implementation, it will look like this
As you can see the task are being run on the background worker and every time a task is finish is reported back to the U.I thread where we can execute a notification (this is actually optional)
When all the tasks are finished, I hide the loading indicator, and the user can interact with the view again
I hope this article clarifies async execution in XAF. I will update the repository as new scenarios arise.

by Joche Ojeda | Oct 15, 2024 | A.I, Semantic Kernel, XAF, XPO
A few weeks ago, I forked the Semantic Kernel repository to experiment with it. One of my first experiments was to create a memory provider for XPO. The task was not too difficult; basically, I needed to implement the IMemoryStore interface, add some XPO boilerplate code, and just like that, we extended the Semantic Kernel memory store to support 10+ databases. You can check out the code for the XpoMemoryStore here.
My initial goal in creating the XpoMemoryStore was simply to see if XPO would be a good fit for handling embeddings. Spoiler alert: it was! To understand the basic functionality of the plugin, you can take a look at the integration test here.
As you can see, usage is straightforward. You start by connecting to the database that handles embedding collections, and all you need is a valid XPO connection string:
using XpoMemoryStore db = await XpoMemoryStore.ConnectAsync("XPO connection string");
In my original design, everything worked fine, but I faced some challenges when trying to use my new XpoMemoryStore in XAF. Here’s what I encountered:
- The implementation of XpoMemoryStore uses its own data layer, which can lead to issues. This needs to be rewritten to use the same data layer as XAF.
- The XpoEntry implementation cannot be extended. In some use cases, you might want to use a different object to store the embeddings, perhaps one that has an association with another object.
To address these problems, I introduced the IXpoEntryManager interface. The goal of this interface is to handle object creation and queries.
public interface IXpoEntryManager
{
T CreateObject();
public event EventHandler ObjectCreatedEvent;
void Commit();
IQueryable GetQuery(bool inTransaction = true);
void Delete(object instance);
void Dispose();
}
Now, object creation is handled through the CreateObject<T> method, allowing the underlying implementation to be changed to use a UnitOfWork or ObjectSpace. There’s also the ObjectCreatedEvent event, which lets you access the newly created object in case you need to associate it with another object. Lastly, the GetQuery<T> method enables redirecting the search for records to a different type.
I’ll keep updating the code as needed. If you’d like to discuss AI, XAF, or .NET, feel free to schedule a meeting: Schedule a Meeting with us.
Until next time, XAF out!
Related Article
https://www.jocheojeda.com/2024/09/04/using-the-imemorystore-interface-and-devexpress-xpo-orm-to-implement-a-custom-memory-store-for-semantic-kernel/
by Joche Ojeda | Oct 10, 2024 | A.I, PropertyEditors, XAF
The New Era of Smart Editors: Developer Express and AI Integration
The new era of smart editors is already here. Developer Express has introduced AI functionality in many of their controls for .NET (Windows Forms, Blazor, WPF, MAUI).
This advancement will eventually come to XAF, but in the meantime, here at XARI, we are experimenting with XAF integrations to add value to our customers.
In this article, we are going to integrate the new chat component into an XAF application, and our first use case will be RAG (Retrieval-Augmented Generation). RAG is a system that combines external data sources with AI-generated responses, improving accuracy and relevance in answers by retrieving information from a document set or knowledge base and using it in conjunction with AI predictions.
To achieve this integration, we will follow the steps outlined in this tutorial:
Implement a Property Editor Based on Custom Components (Blazor)
Implementing the Property Editor
When I implement my own property editor, I usually avoid doing so for primitive types because, in most cases, my property editor will need more information than a simple primitive value. For this implementation, I want to handle a custom value in my property editor. I typically create an interface to represent the type, ensuring compatibility with both XPO and EF Core.
namespace XafSmartEditors.Razor.RagChat
{
public interface IRagData
{
Stream FileContent { get; set; }
string Prompt { get; set; }
string FileName { get; set; }
}
}
Non-Persistent Implementation
After defining the type for my editor, I need to create a non-persistent implementation:
namespace XafSmartEditors.Razor.RagChat
{
[DomainComponent]
public class IRagDataImp : IRagData, IXafEntityObject, INotifyPropertyChanged
{
private void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
public IRagDataImp()
{
Oid = Guid.NewGuid();
}
[DevExpress.ExpressApp.Data.Key]
[Browsable(false)]
public Guid Oid { get; set; }
private string prompt;
private string fileName;
private Stream fileContent;
public Stream FileContent
{
get => fileContent;
set
{
if (fileContent == value) return;
fileContent = value;
OnPropertyChanged();
}
}
public string FileName
{
get => fileName;
set
{
if (fileName == value) return;
fileName = value;
OnPropertyChanged();
}
}
public string Prompt
{
get => prompt;
set
{
if (prompt == value) return;
prompt = value;
OnPropertyChanged();
}
}
// IXafEntityObject members
void IXafEntityObject.OnCreated() { }
void IXafEntityObject.OnLoaded() { }
void IXafEntityObject.OnSaving() { }
public event PropertyChangedEventHandler PropertyChanged;
}
}
Creating the Blazor Chat Component
Now, it’s time to create our Blazor component and add the new DevExpress chat component for Blazor:
<DxAIChat CssClass="my-chat" Initialized="Initialized"
RenderMode="AnswerRenderMode.Markdown"
UseStreaming="true"
SizeMode="SizeMode.Medium">
<EmptyMessageAreaTemplate>
<div class="my-chat-ui-description">
<span style="font-weight: bold; color: #008000;">Rag Chat</span> Assistant is ready to answer your questions.
</div>
</EmptyMessageAreaTemplate>
<MessageContentTemplate>
<div class="my-chat-content">
@ToHtml(context.Content)
</div>
</MessageContentTemplate>
</DxAIChat>
@code {
IRagData _value;
[Parameter]
public IRagData Value
{
get => _value;
set => _value = value;
}
async Task Initialized(IAIChat chat)
{
await chat.UseAssistantAsync(new OpenAIAssistantOptions(
this.Value.FileName,
this.Value.FileContent,
this.Value.Prompt
));
}
MarkupString ToHtml(string text)
{
return (MarkupString)Markdown.ToHtml(text);
}
}
The main takeaway from this component is that it receives a parameter named Value of type IRagData, and we use this value to initialize the IAIChat service in the Initialized method.
Creating the Component Model
With the interface and domain component in place, we can now create the component model to communicate the value of our domain object with the Blazor component:
namespace XafSmartEditors.Razor.RagChat
{
public class RagDataComponentModel : ComponentModelBase
{
public IRagData Value
{
get => GetPropertyValue<IRagData>();
set => SetPropertyValue(value);
}
public EventCallback<IRagData> ValueChanged
{
get => GetPropertyValue<EventCallback<IRagData>>();
set => SetPropertyValue(value);
}
public override Type ComponentType => typeof(RagChat);
}
}
Creating the Property Editor
Finally, let’s create the property editor class that serves as a bridge between XAF and the new component:
namespace XafSmartEditors.Blazor.Server.Editors
{
[PropertyEditor(typeof(IRagData), true)]
public class IRagDataPropertyEditor : BlazorPropertyEditorBase, IComplexViewItem
{
private IObjectSpace _objectSpace;
private XafApplication _application;
public IRagDataPropertyEditor(Type objectType, IModelMemberViewItem model) : base(objectType, model) { }
public void Setup(IObjectSpace objectSpace, XafApplication application)
{
_objectSpace = objectSpace;
_application = application;
}
public override RagDataComponentModel ComponentModel => (RagDataComponentModel)base.ComponentModel;
protected override IComponentModel CreateComponentModel()
{
var model = new RagDataComponentModel();
model.ValueChanged = EventCallback.Factory.Create<IRagData>(this, value =>
{
model.Value = value;
OnControlValueChanged();
WriteValue();
});
return model;
}
protected override void ReadValueCore()
{
base.ReadValueCore();
ComponentModel.Value = (IRagData)PropertyValue;
}
protected override object GetControlValueCore() => ComponentModel.Value;
protected override void ApplyReadOnly()
{
base.ApplyReadOnly();
ComponentModel?.SetAttribute("readonly", !AllowEdit);
}
}
}
Bringing It All Together
Now, let’s create a domain object that can feed the content of a file to our chat component:
namespace XafSmartEditors.Module.BusinessObjects
{
[DefaultClassOptions]
public class PdfFile : BaseObject
{
public PdfFile(Session session) : base(session) { }
string prompt;
string name;
FileData file;
public FileData File
{
get => file;
set => SetPropertyValue(nameof(File), ref file, value);
}
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public string Prompt
{
get => prompt;
set => SetPropertyValue(nameof(Prompt), ref prompt, value);
}
}
}
Creating the Controller
We are almost done! Now, we need to create a controller with a popup action:
namespace XafSmartEditors.Module.Controllers
{
public class OpenChatController : ViewController
{
Popup
WindowShowAction Chat;
public OpenChatController()
{
this.TargetObjectType = typeof(PdfFile);
Chat = new PopupWindowShowAction(this, "ChatAction", "View");
Chat.Caption = "Chat";
Chat.ImageName = "artificial_intelligence";
Chat.Execute += Chat_Execute;
Chat.CustomizePopupWindowParams += Chat_CustomizePopupWindowParams;
}
private void Chat_Execute(object sender, PopupWindowShowActionExecuteEventArgs e) { }
private void Chat_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
PdfFile pdfFile = this.View.CurrentObject as PdfFile;
var os = this.Application.CreateObjectSpace(typeof(ChatView));
var chatView = os.CreateObject<ChatView>();
MemoryStream memoryStream = new MemoryStream();
pdfFile.File.SaveToStream(memoryStream);
memoryStream.Seek(0, SeekOrigin.Begin);
chatView.RagData = os.CreateObject<IRagDataImp>();
chatView.RagData.FileName = pdfFile.File.FileName;
chatView.RagData.Prompt = !string.IsNullOrEmpty(pdfFile.Prompt) ? pdfFile.Prompt : DefaultPrompt;
chatView.RagData.FileContent = memoryStream;
DetailView detailView = this.Application.CreateDetailView(os, chatView);
detailView.Caption = $"Chat with Document | {pdfFile.File.FileName.Trim()}";
e.View = detailView;
}
}
}
Conclusion
That’s everything we need to create a RAG system using XAF and the new DevExpress Chat component. You can find the complete source code here: GitHub Repository.
If you want to meet and discuss AI, XAF, and .NET, feel free to schedule a meeting: Schedule a Meeting.
Until next time, XAF out!