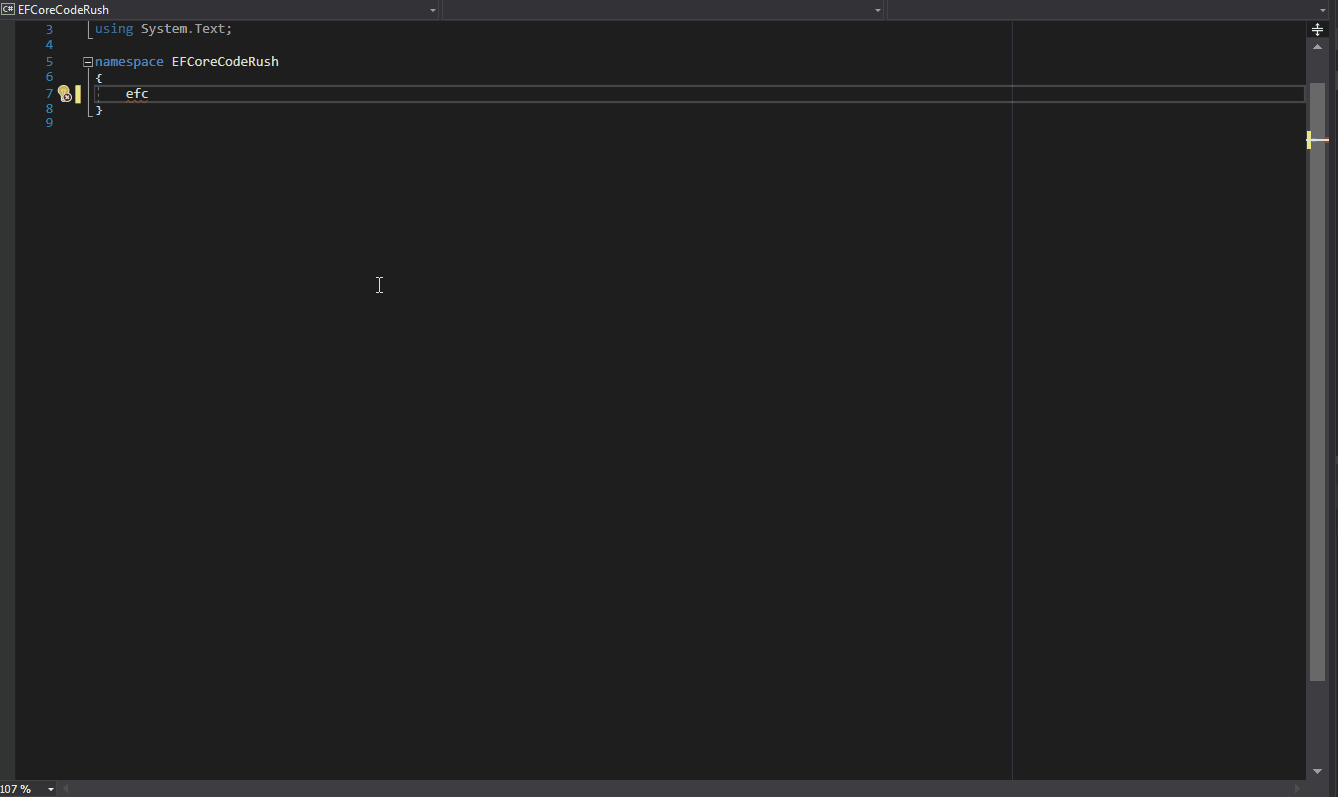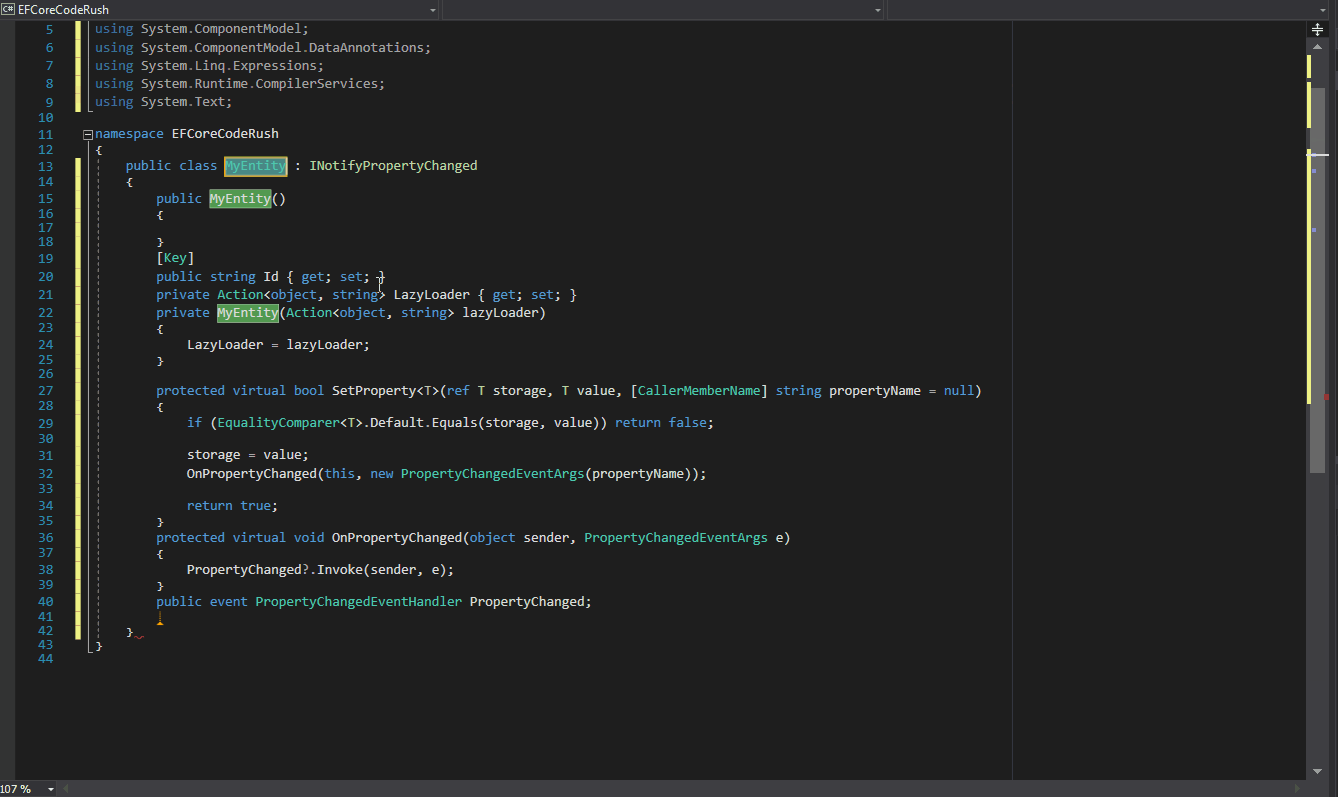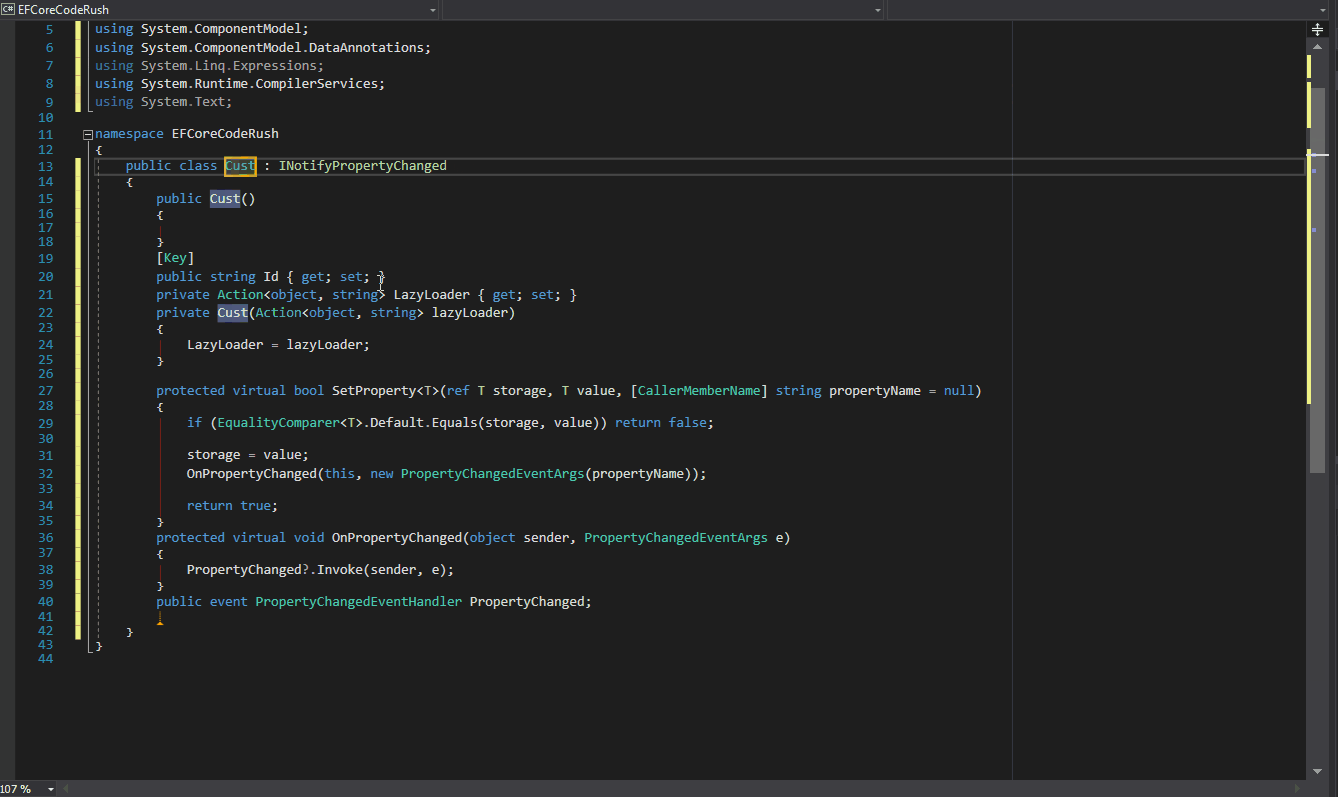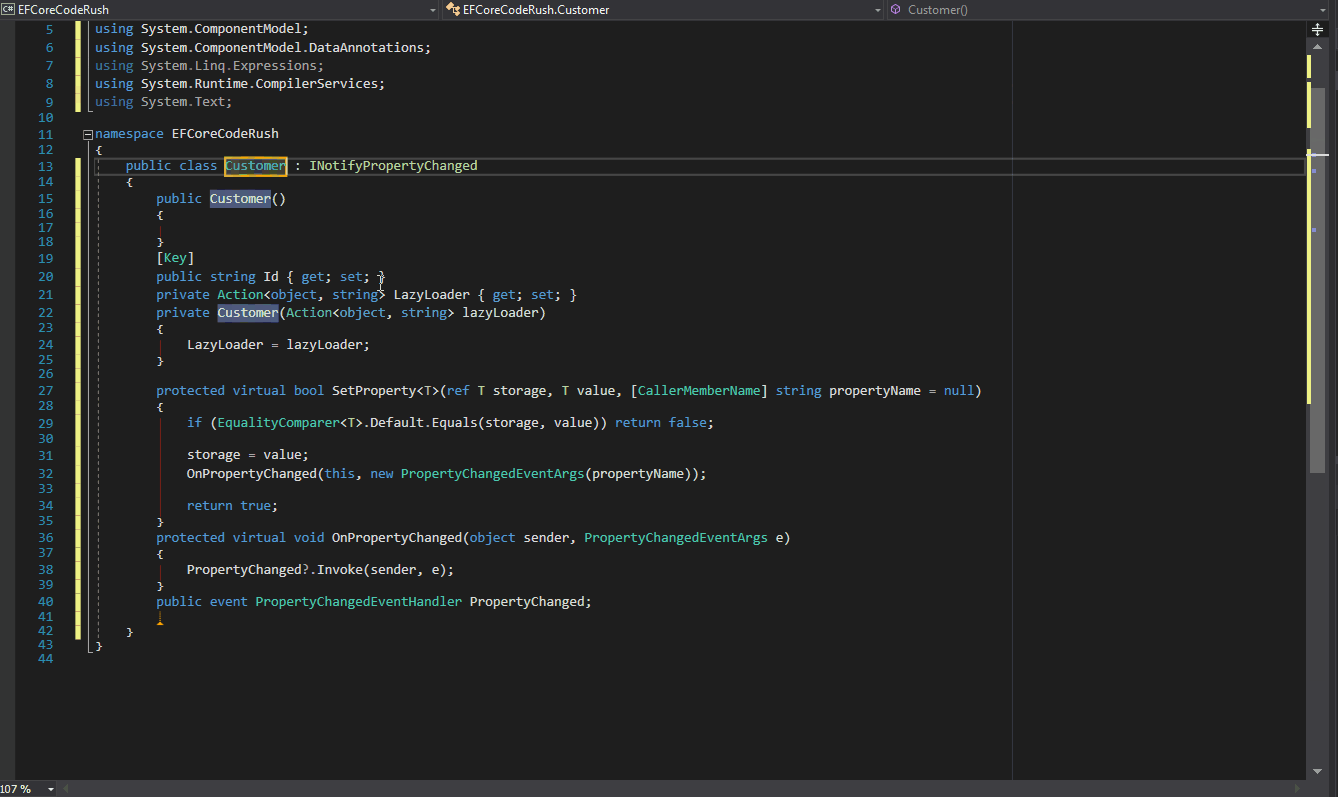
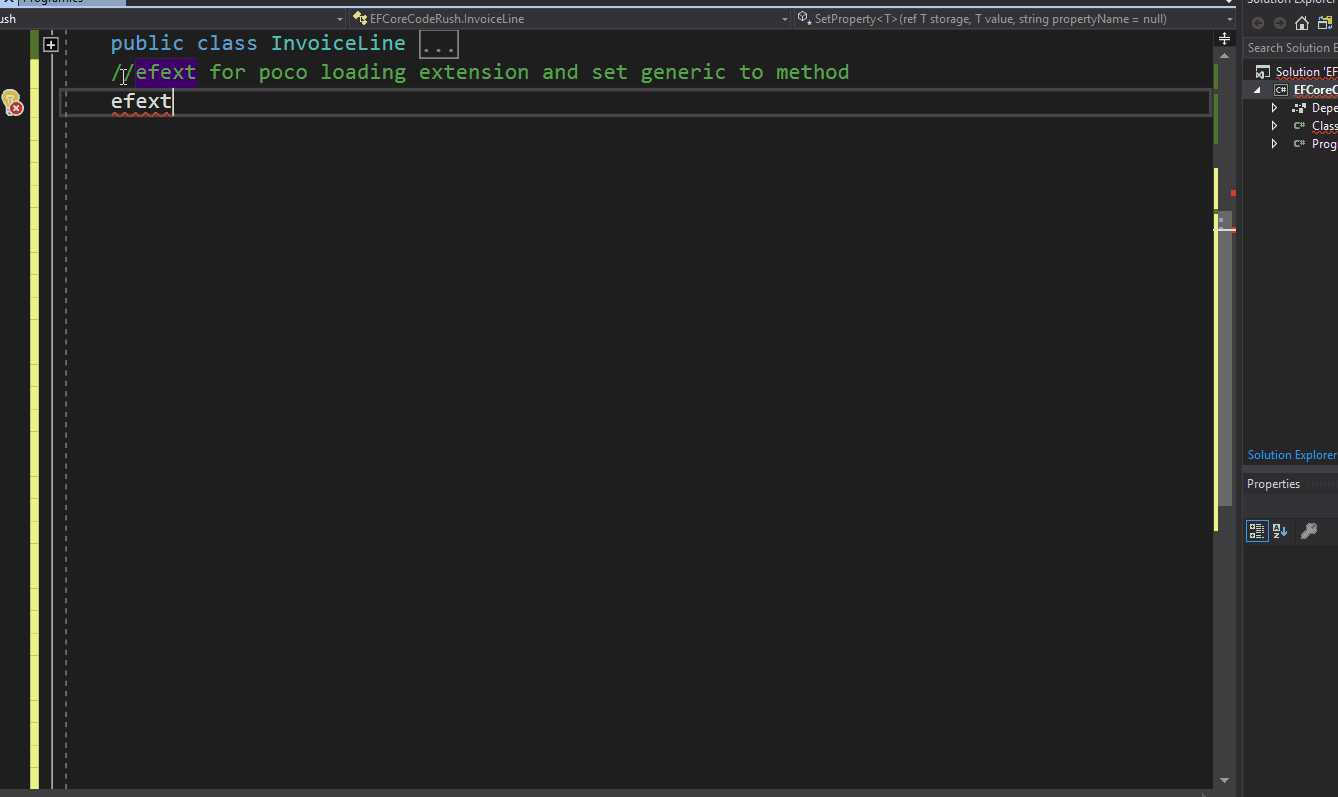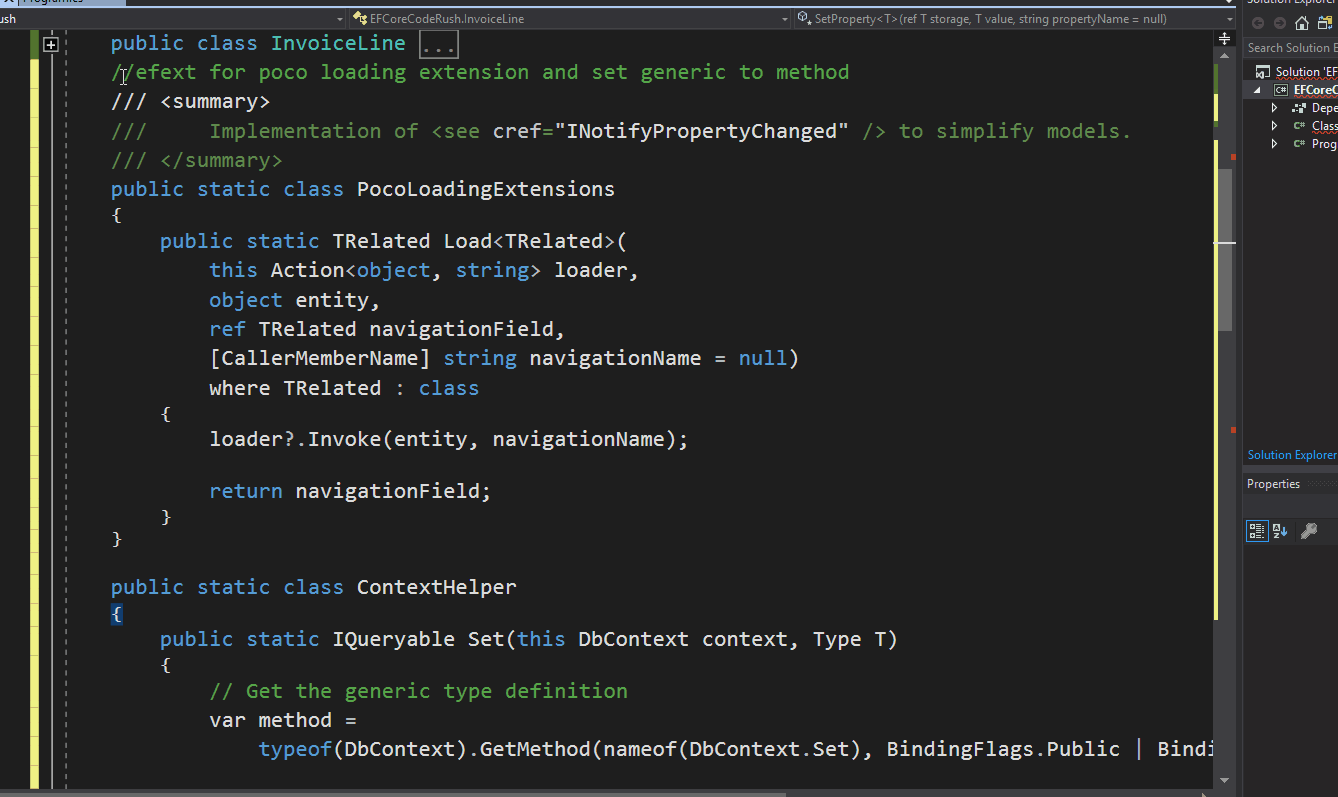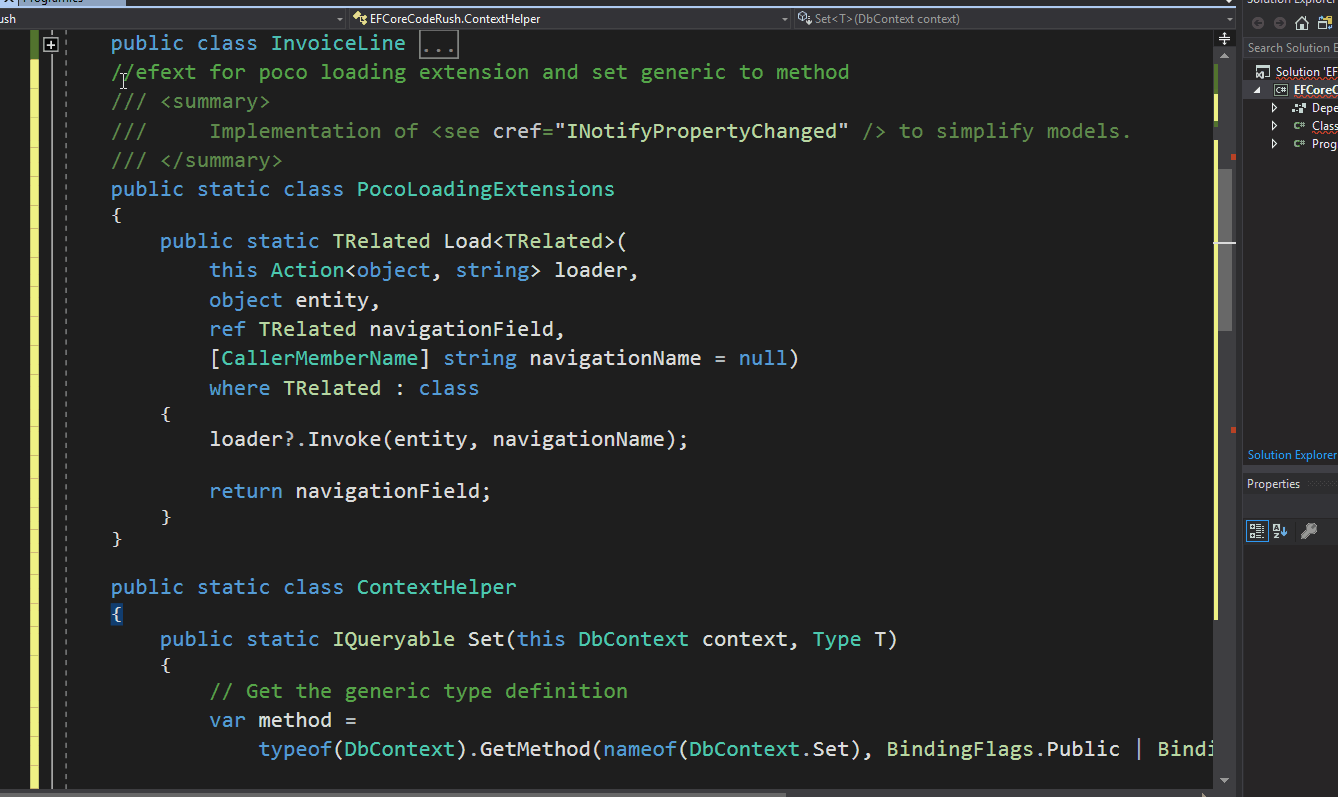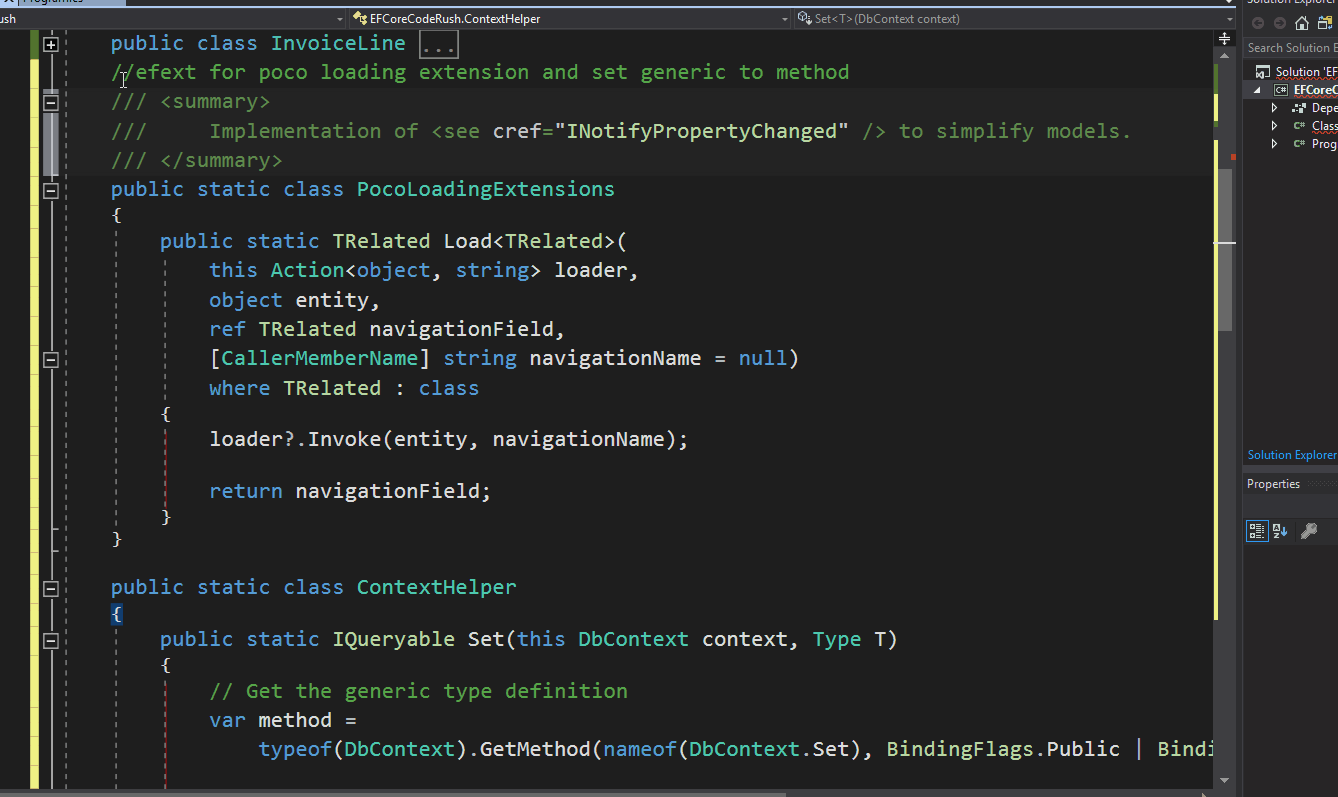
Full-text search in PostgreSQL is implemented using a concept called “text search vectors” (or just “tsvector”). Let’s dive into how it works:
Text Search Vectors (tsvector):
A tsvector is a sorted list of distinct lexemes, which are words that have been normalized to merge different forms of the same word (e.g., “run” and “running”).
PostgreSQL provides functions to convert plain text into tsvector format, which typically involves:
Parsing the text into tokens.
Converting tokens to lexemes.
Removing stop words (common words like “and” or “the” that are typically ignored in searches).
Example: The text “The quick brown fox” might be represented in tsvector as ‘brown’:3 ‘fox’:4 ‘quick’:2.
Text Search Queries (tsquery):
A tsquery represents a text search query, which includes lexemes and optional operators.
Operators can be used to combine lexemes in different ways (e.g., AND, OR, NOT).
Example: The query “quick & fox” would match any tsvector containing both “quick” and “fox”.
Searching:
PostgreSQL provides the @@ operator to search a tsvector column with a tsquery.
Example: WHERE column @@ to_tsquery(‘english’, ‘quick & fox’).
Ranking:
Once you’ve found matches using the @@ operator, you often want to rank them by relevance.
PostgreSQL provides the ts_rank function to rank results. It returns a number indicating how relevant a tsvector is to a tsquery.
The ranking is based on various factors, including the frequency of lexemes and their proximity to each other in the text.
Indexes:
One of the significant advantages of tsvector is that you can create a GiST or GIN index on it.
These indexes significantly speed up full-text search queries.
GIN indexes, in particular, are optimized for tsvector and provide very fast lookups.
Normalization and Configuration:
PostgreSQL supports multiple configurations (e.g., “english”, “french”) that determine how text is tokenized and which stop words are used.
This allows you to tailor your full-text search to specific languages or requirements.
Highlighting and Snippets:
In addition to just searching, PostgreSQL provides functions like ts_headline to return snippets of the original text with search terms highlighted.
In summary, PostgreSQL’s full-text search works by converting regular text into a normalized format (tsvector) that is optimized for searching. This combined with powerful query capabilities (tsquery) and indexing options makes it a robust solution for many full-text search needs.
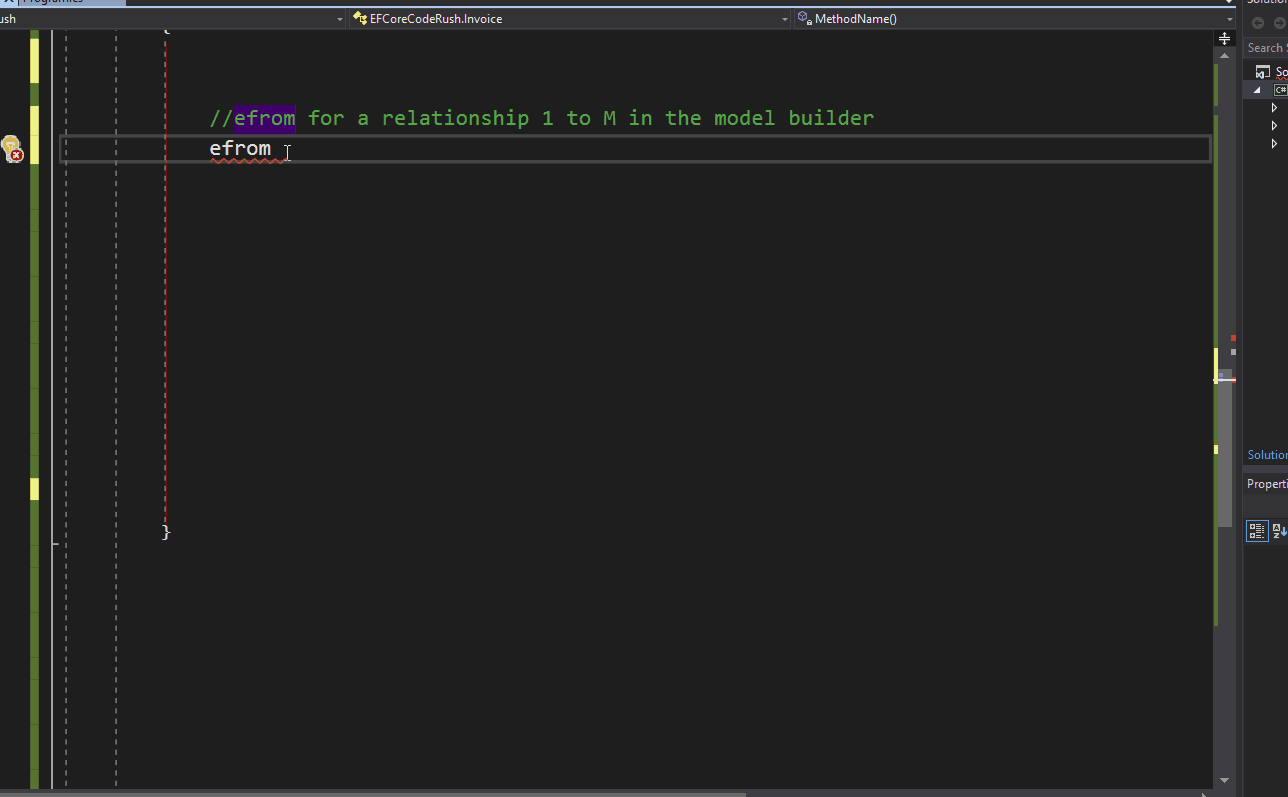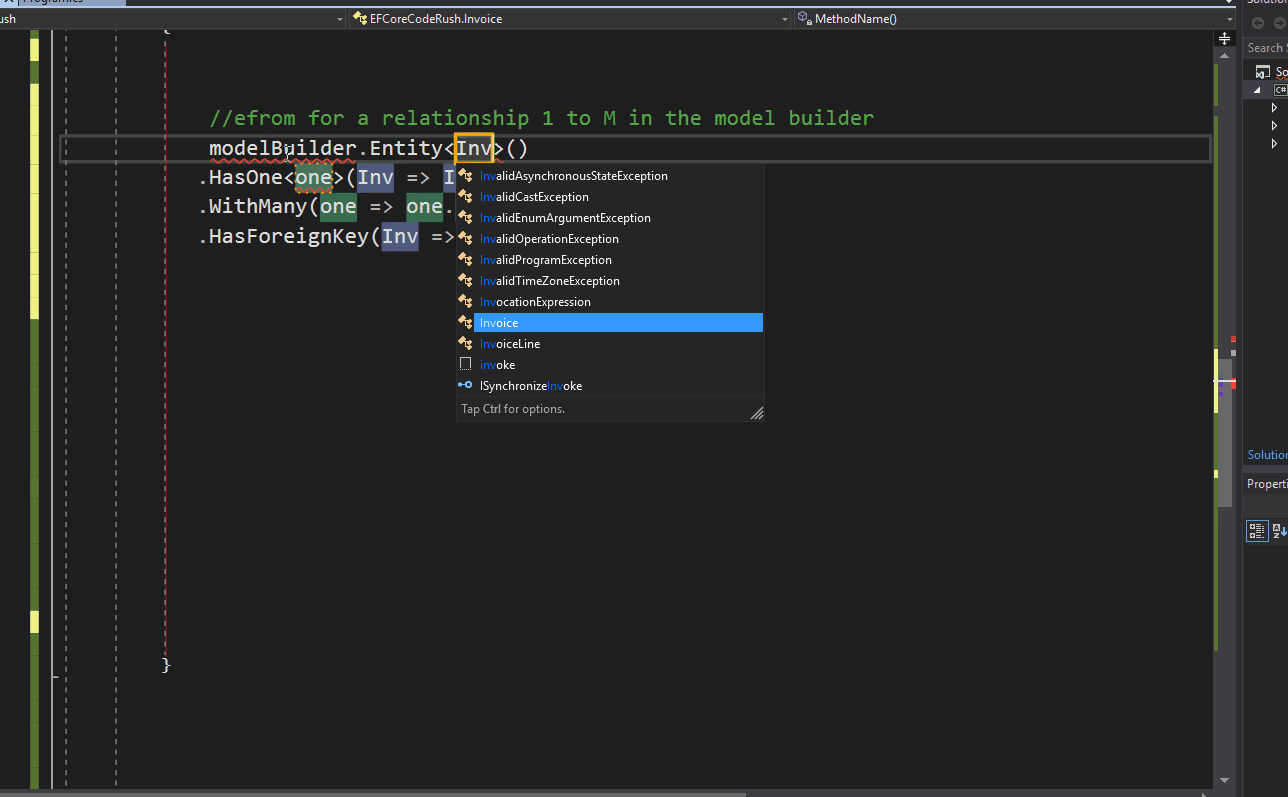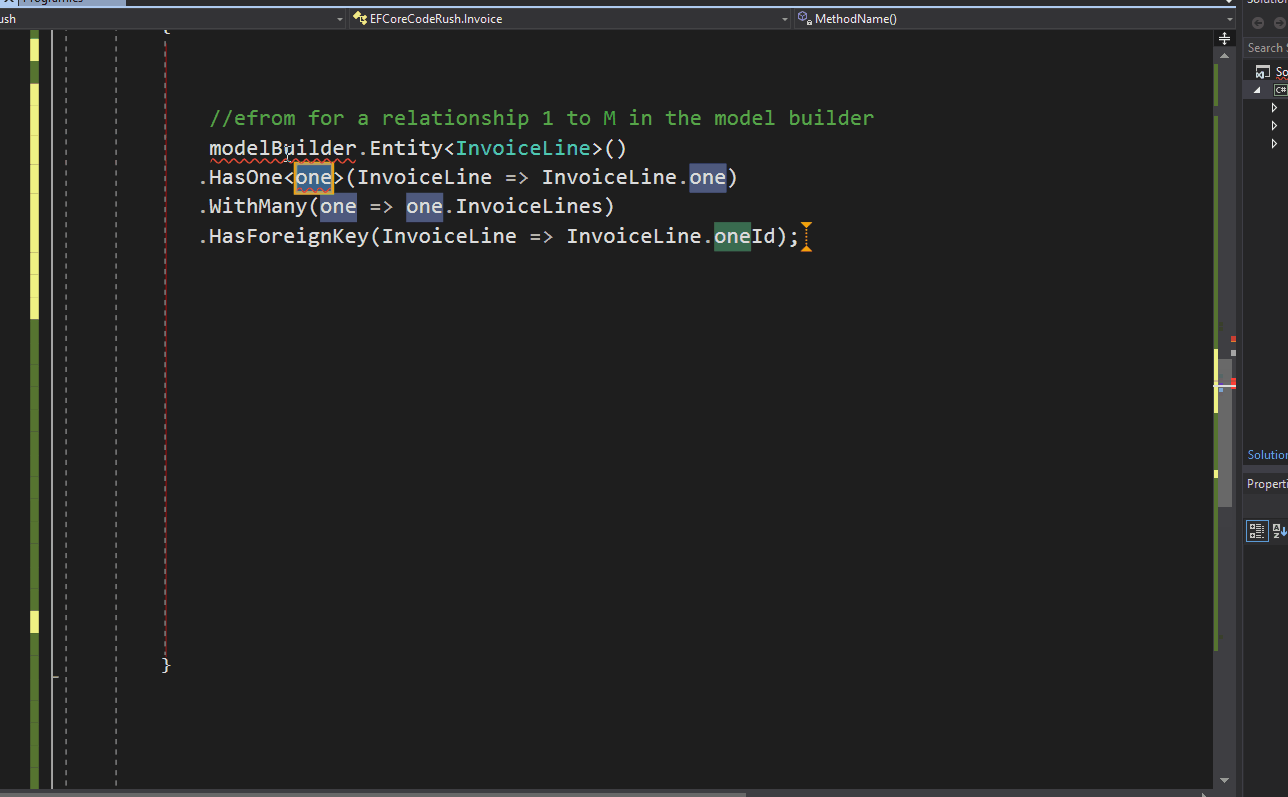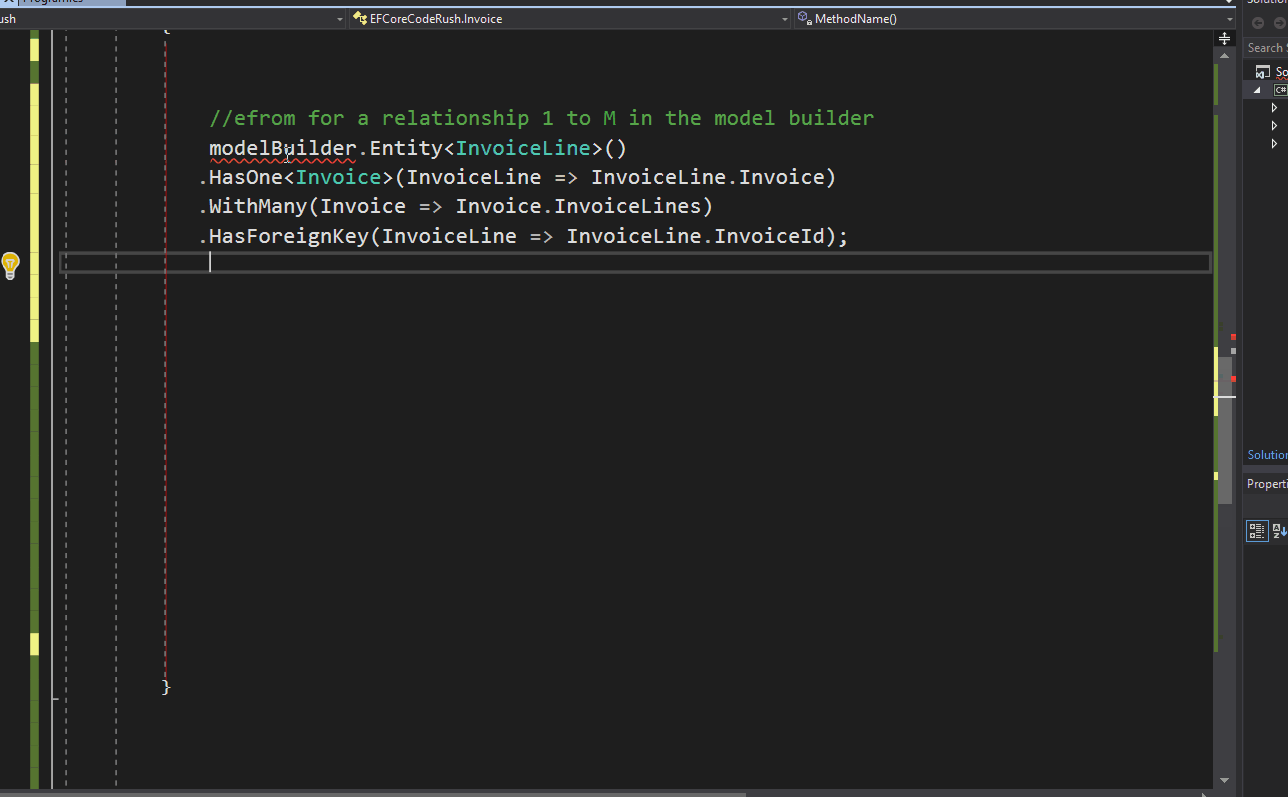
Implementing vector search using E.F Core and Postgres SQL
here are the steps to implement vector search in your dot net project:
in this case you are calculating the vector using the value of the title column of the blogs table, you can calculate the vector using a single column or a combination of columns
Now you are ready to use vector search in your queries, please check the example below
var searchTerm = "Jungle"; // Example search term
var searchVector = NpgsqlTsVector.Parse(searchTerm);
var blogs = context.Blogs
.Where(p => p.SearchVector.Matches(searchTerm))
.OrderByDescending(td => td.SearchVector.Rank(EF.Functions.ToTsQuery(searchTerm))).ToList();
In real world scenarios its better to create a vector by joining the values of several columns and weight them according to the relevance for your business case, you can check the test project I have created here : https://github.com/egarim/PostgresVectorSearch
and that’s it for this post, until next time, happy coding ))
Last Friday, I received a message from a dear friend and colleague, Pedro Hernandez. He asked me if I had the latest compiled version of the XPO import framework we created in our office. As it turned out, I did not have it readily available and had to search extensively for it.
While conducting this search across my computers, repositories, and virtual machines, I was inspired to create another import framework — yes, another piece of code to maintain.
Most of the time, my research projects begin in the same manner, typically after a conversation with my close friend Jose Javier Columbie. As always, he would say something like this: “Jose, do you think this can be possible? Why don’t you give it a try? If we succeed, that will be el batazo (like hitting a home run).”
In this specific case, that conversation didn’t happen. However, I could hear his words echoing in my mind.
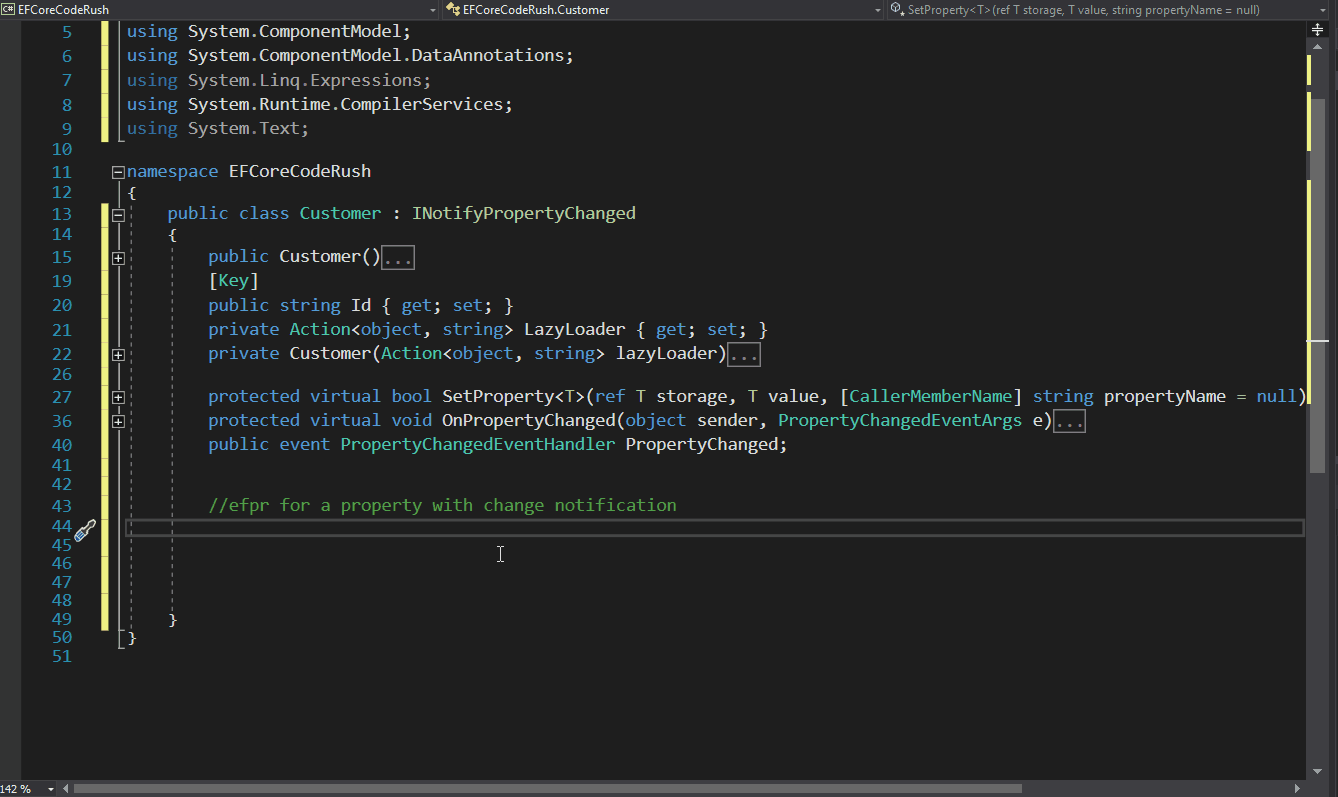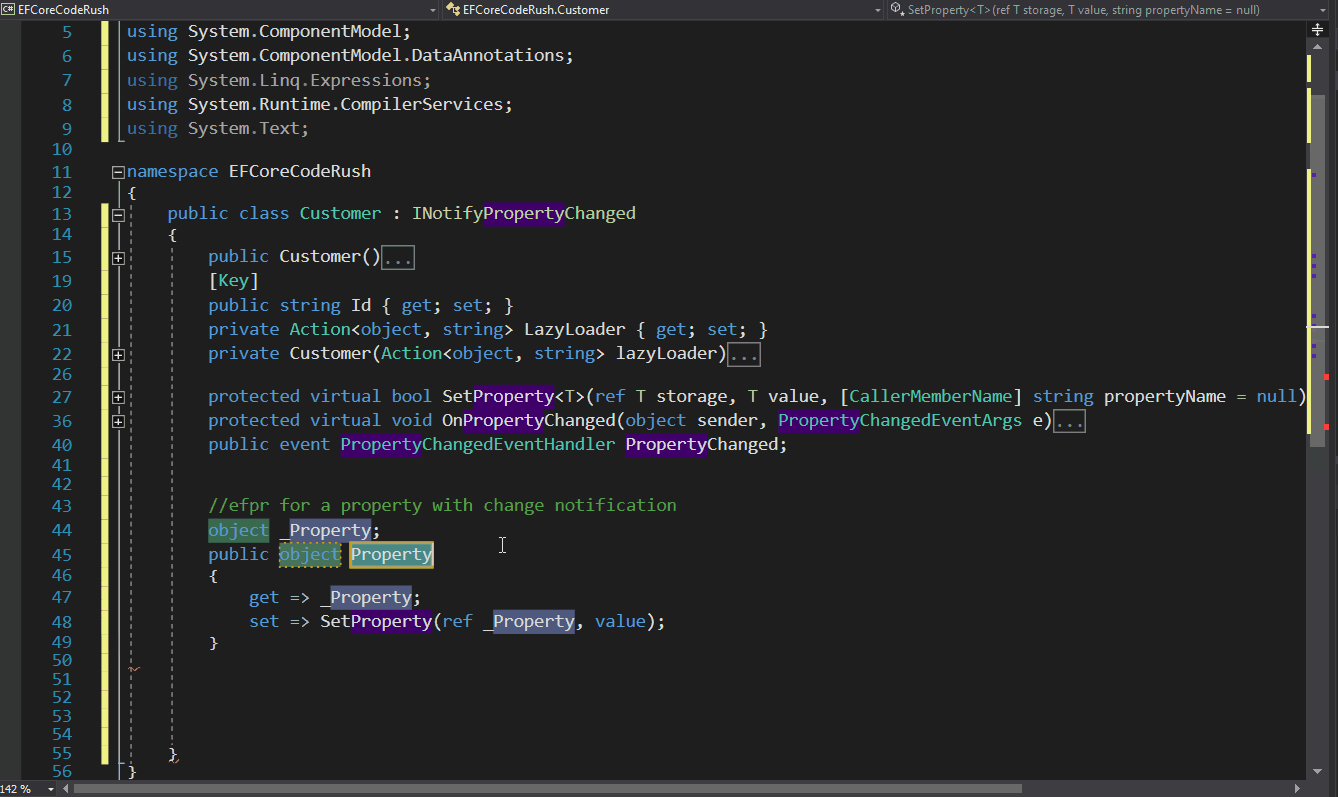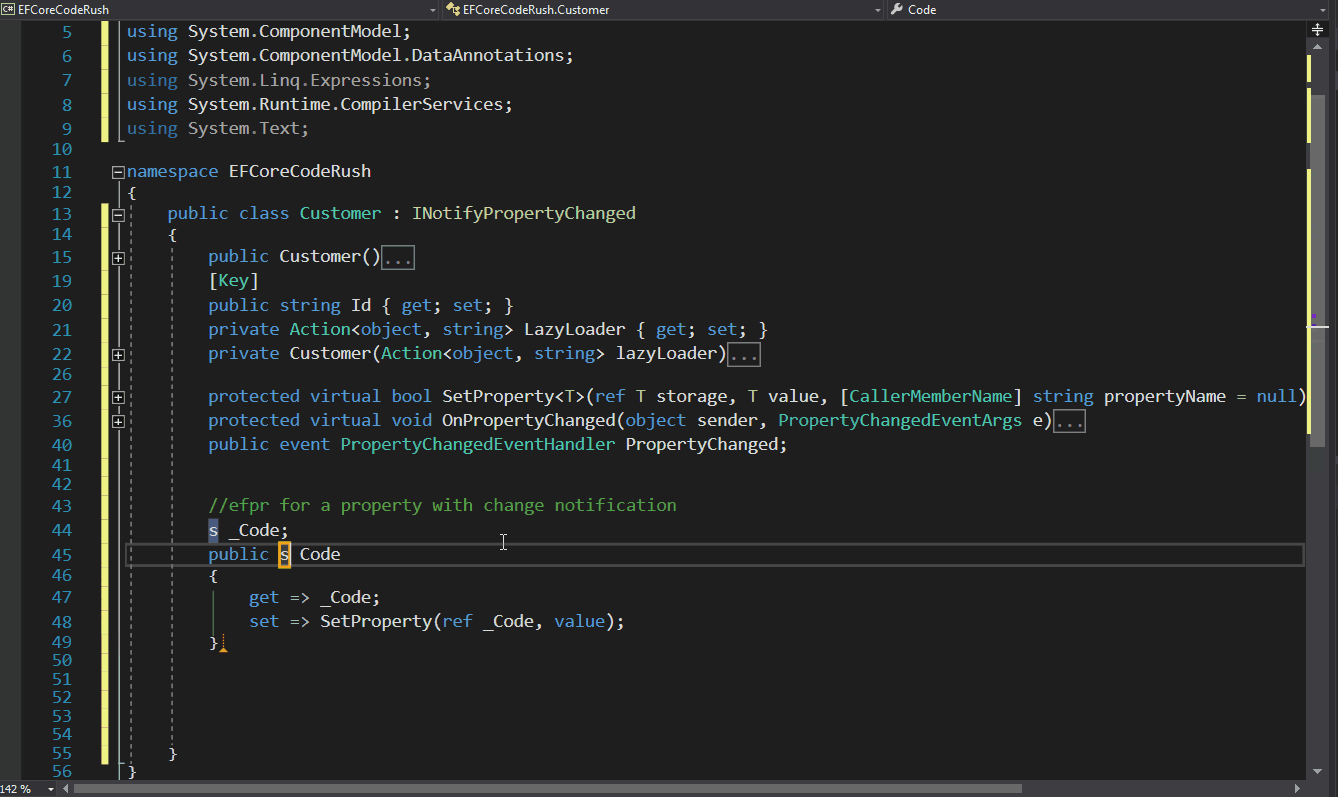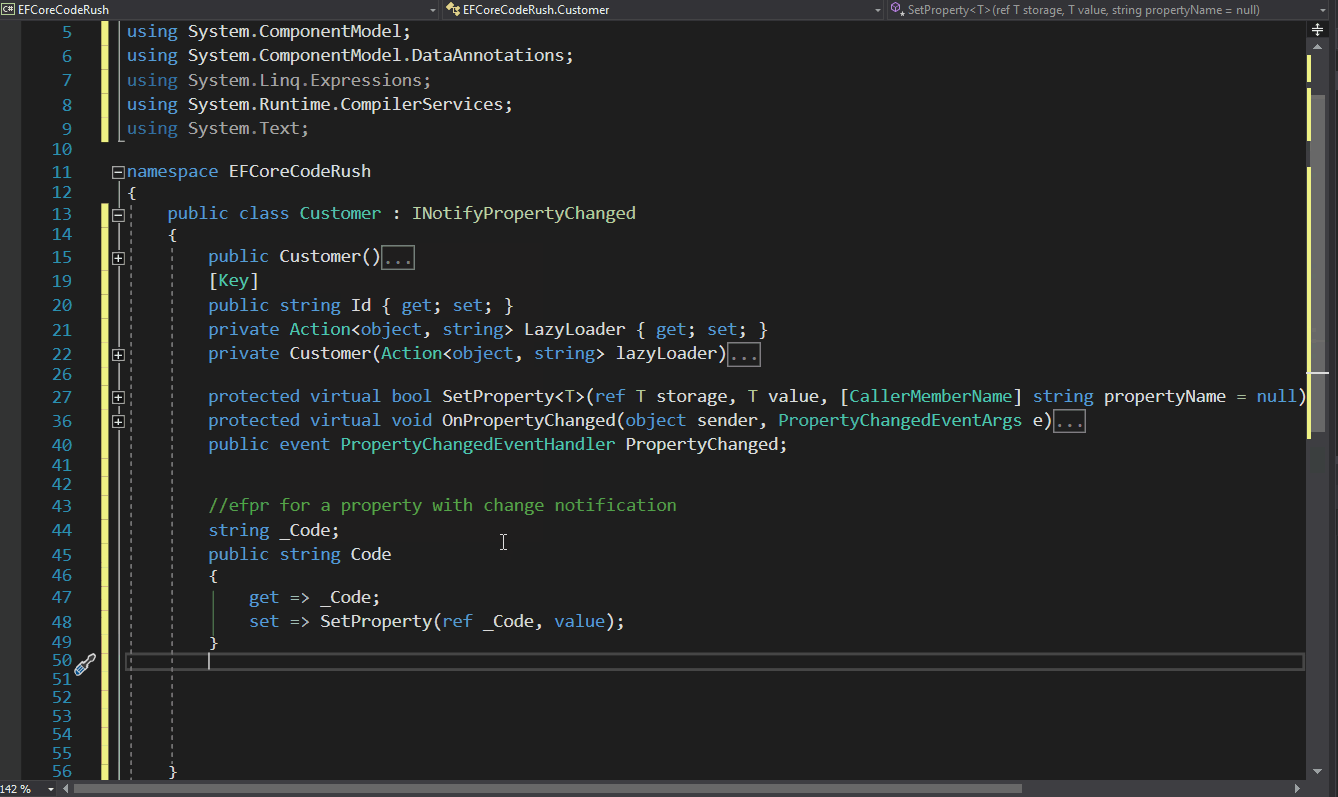
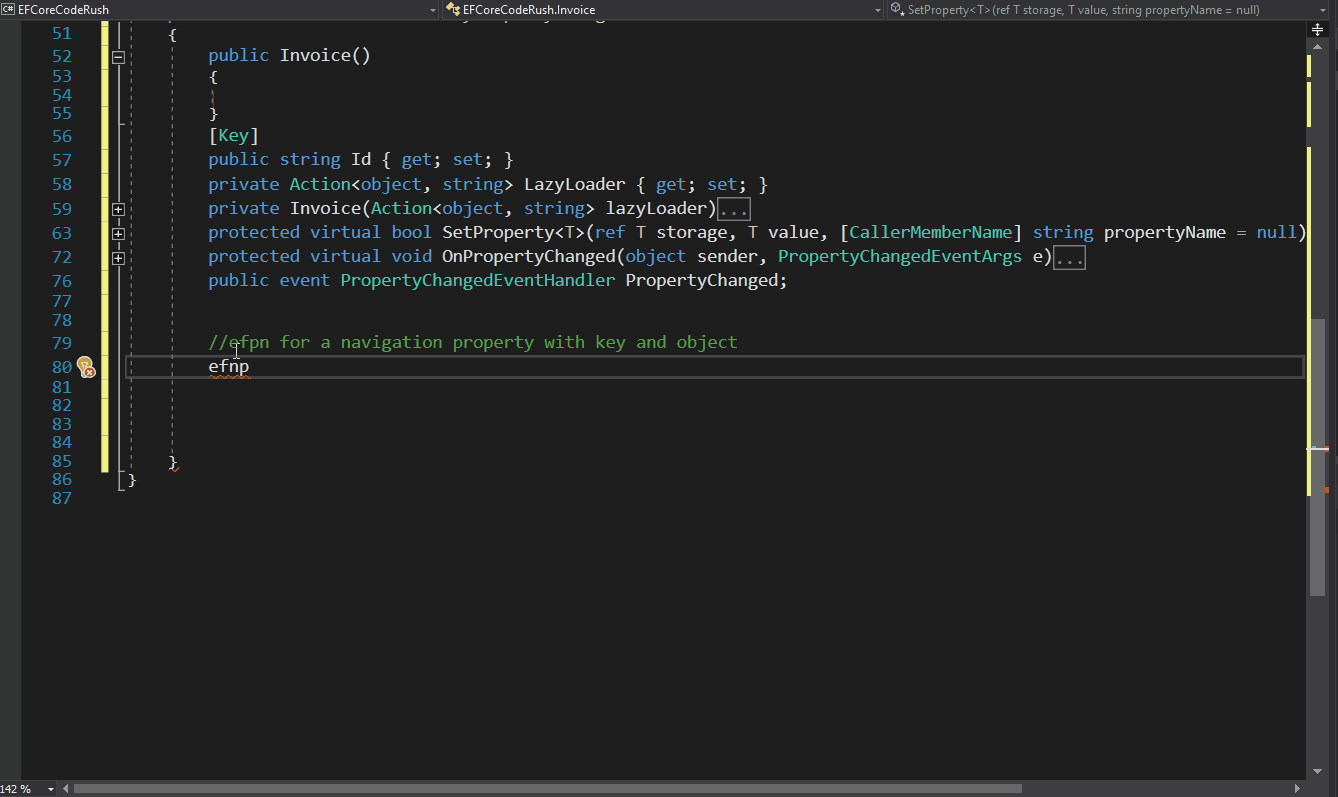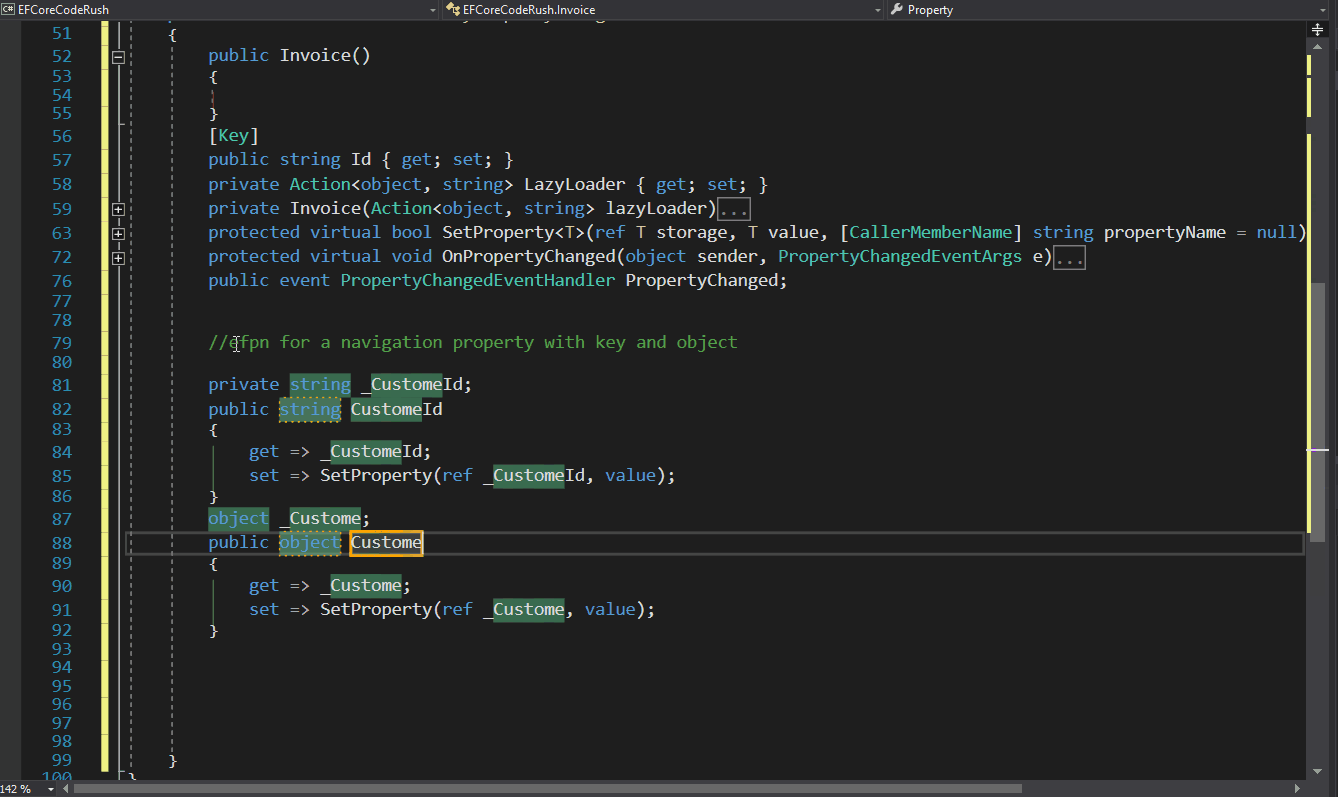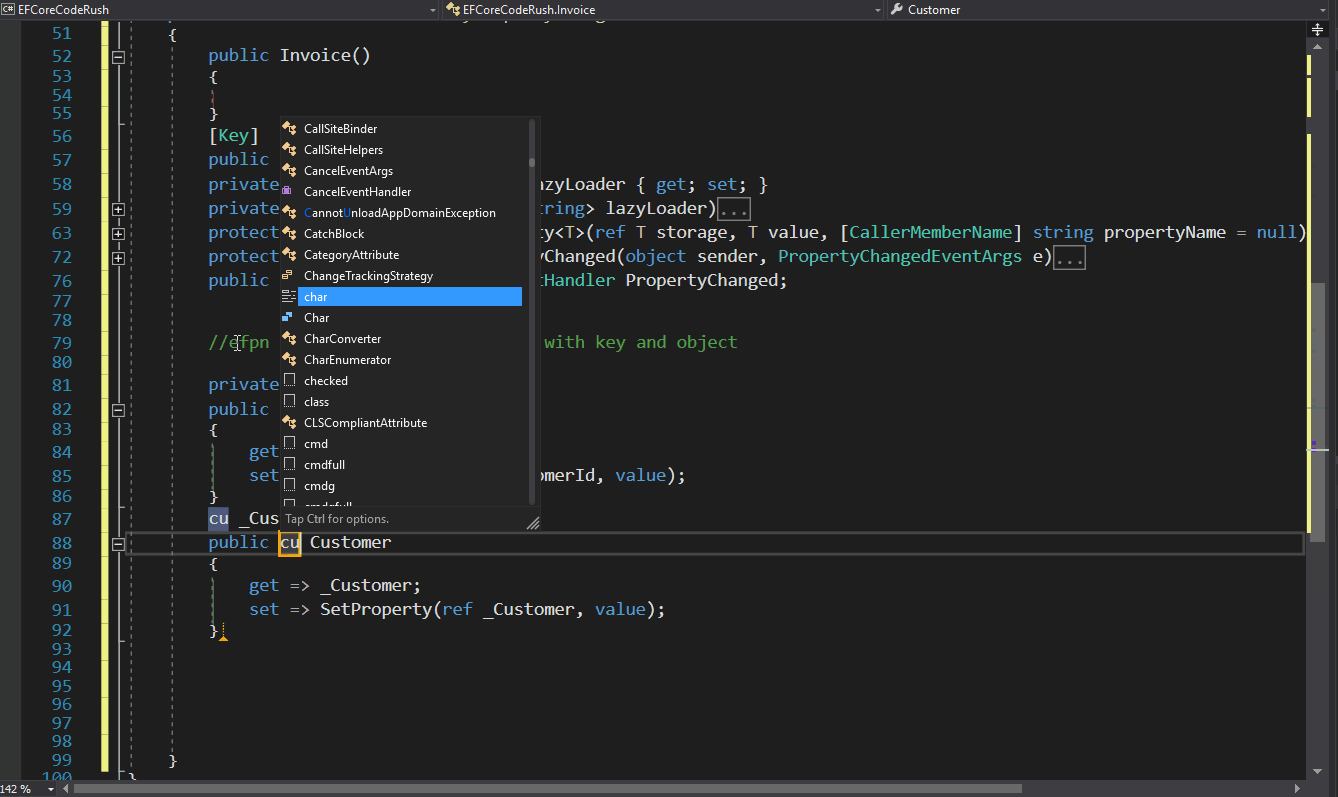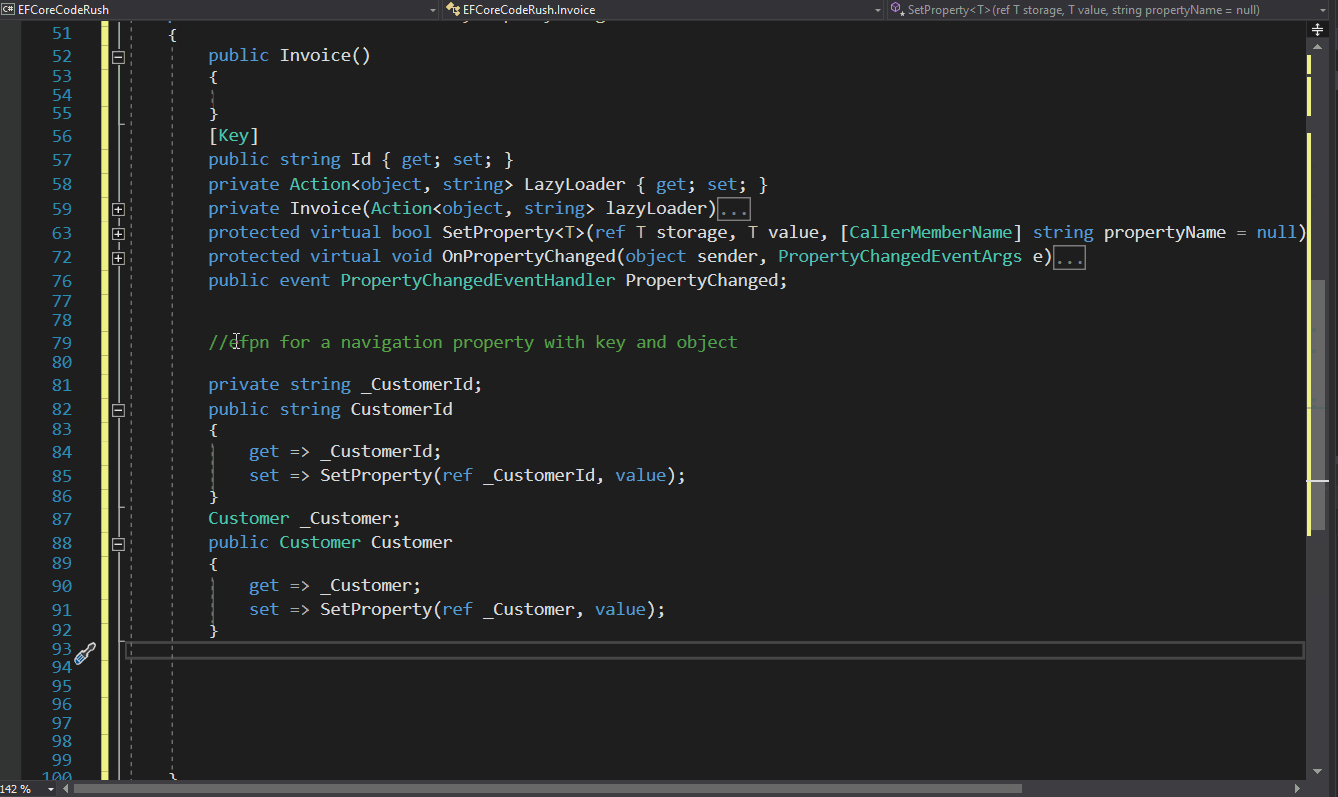
Furthermore, I want this project to be community-driven, not just a technical experiment I have to maintain alone. I truly believe in the power of a community.
First Step
So, let’s begin. I’ll start with my favorite part: naming the project. I spent all weekend pondering this, attempting to condense the concept and associate it with a literary term or a Latin word (these are my preferred methods for naming a project).
Let’s define what the ultimate goal is. In an import process, the aim is to take information from a source ‘A’, translate or transform the information, and then store it in a target ‘B’.
Growing up, I was an avid reader – and I mean, I read a lot. (Now, I’ve switched to audiobooks.) Therefore, after defining what this project is about, naming it became incredibly easy.
noun
noun: alchemy
the medieval forerunner of chemistry, concerned with the transmutation of matter, in particular with attempts to convert base metals into gold or find a universal elixir.
“occult sciences, such as alchemy and astrology”
Origin
late Middle English: via Old French and medieval Latin from Arabic al-kīmiyā’, from al ‘the’ + kīmiyā’ (from Greek khēmia, khēmeia ‘art of transmuting metals’).
The alchemy Framework
Alchemy is a framework created for DotNet, designed to import data from a data source to a data target. These sources and targets can be anything from a text file, CSV file, a database, ORMs, and so on.
The framework consists of a set of contracts, interfaces, and base classes. When implemented, these allow you to import and transform data between various sources and targets.
The requirement in a few words
As stated in the framework’s description, the requirement is only to define the contracts that represent the sources and targets, as well as a job configuration that describes how the information flows from one source to a target. The concrete implementations are not important at this point and should be discussed individually for each case.
The design patterns.
For this project, we will use the SOLID design principles and dependency injection. This will enable us to easily replace small functionalities, allowing us to mix and match different implementations depending on the data source and data target.
I will explain what XAF is just for the sake of the consistency of this article, XAF is a low code application framework for line of business applications that runs on NET framework (windows forms and web forms) and in dotnet (windows forms, Blazor and Web API)
XAF is laser focus on productivity, DevExpress team has created several modules that encapsulate design patterns and common tasks needed on L.O.B apps.
The starting point in XAF is to provide a domain model using an ORMs like XPO or Entity framework and then XAF will create an application for you using the target platform of choice.
It’s a common misunderstanding that you need to use and ORM in order to provide a domain model to XAF
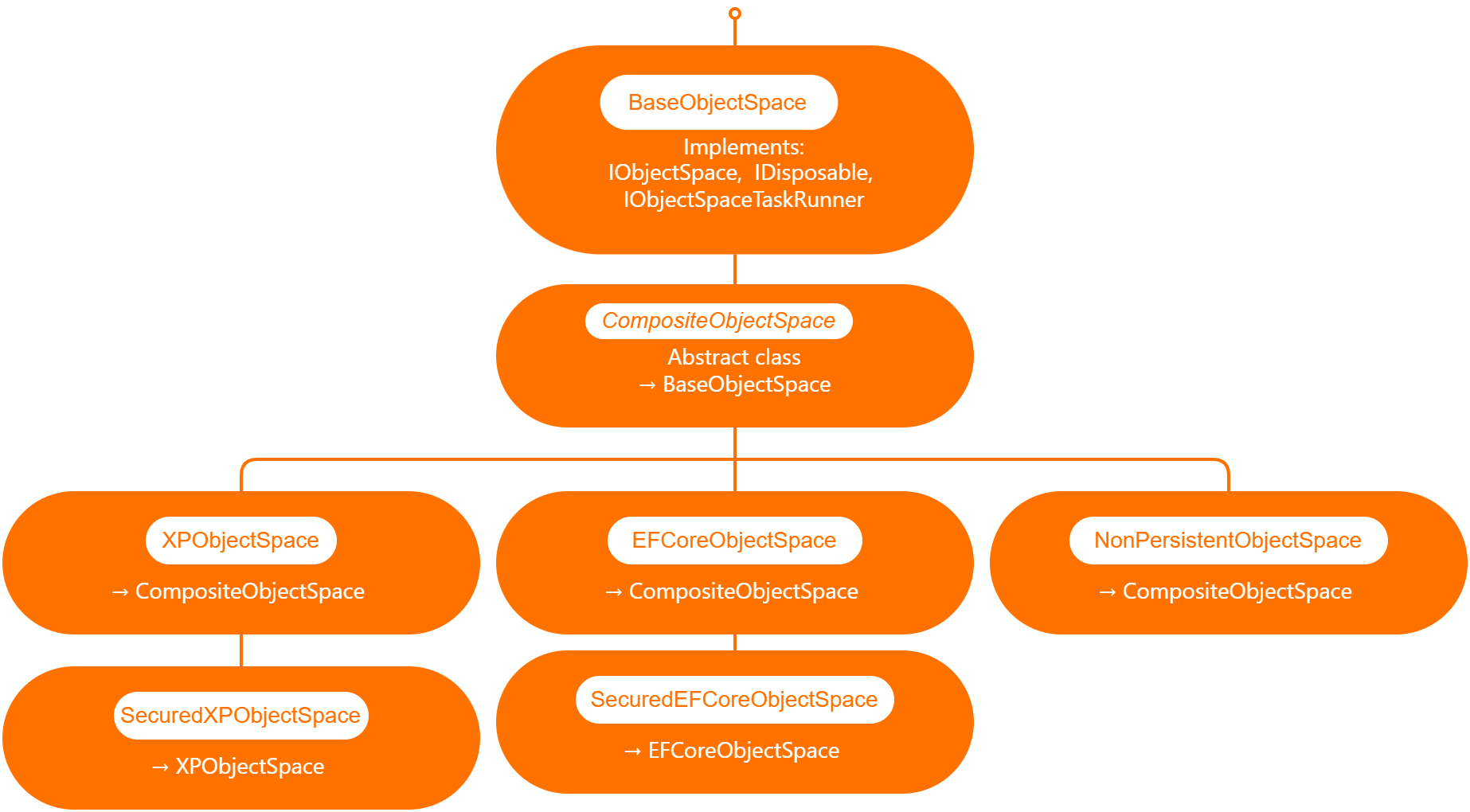
Out of the box XAF provide 3 branches of object spaces as show is the graph below.
XPObjectSpace: this is the object space that allows you to use XPO as a data access technology.
EfCoreObjectSpace: this is the object space that allows you to use Microsoft Entity Framework as a data access technology.
NonPersistenObjectSpace: this object space is interesting as it provides the domain model needed for XAF to generate the views and interact with the data is not attached to an ORM technology so it’s up to us to provide the data, also this type of object space can be used in combination with XPObjectSpace and EfCoreObjectSpace
When querying external data sources, you also need to solve the problem of filtering and sorting data in order to provide a full solution, for that reason DevExpress team provide us with the DynamicCollection class, that is a proxy collection that allows you to filter and sort an original collection without changing it.
Now that we know the parts involved in presenting data in a XAF application, we can define the required flow.
public override void Setup(XafApplication application) {
base.Setup(application);
// Manage various aspects of the application UI and behavior at the module level.
application.SetupComplete += Application_SetupComplete;
}
Wire the application object space created event.
private void Application_SetupComplete(object sender, EventArgs e) {
Application.ObjectSpaceCreated += Application_ObjectSpaceCreated;
}
private void Application_ObjectSpaceCreated(object sender, ObjectSpaceCreatedEventArgs e) {
var npos = e.ObjectSpace as NonPersistentObjectSpace;
if (npos != null) {
new ArticleAdapter(npos);
new ContactAdapter(npos);
}
}
In conclusion the ObjectSpace abstraction ensures that different data access technologies can be employed, while the DynamicCollection class allows for seamless filtering and sorting of data from external sources. By following the outlined steps, developers can create robust, adaptable, and efficient applications with XAF, ultimately saving time and effort while maximizing application performance.
Ok, so far, our synchronization framework is only implemented for an in-memory database that we use for testing purposes.
Now let’s implement a different use case, lets add synchronization functionality to an entity framework core DbContext.
As I explained before, the key part of synchronizing data using delta encoding is to be able to track the differences that happen to a data object, in this case, a relational database.
these are the task that we need to do to accomplish our goal
Find out how entity framework converts the changes that happen to the objects to SQL commands
Decide what information we need to track and save as a delta
Create the infrastructure to save deltas (IDeltaStore)
Create the infrastructure to process deltas (IDeltaProcessor)
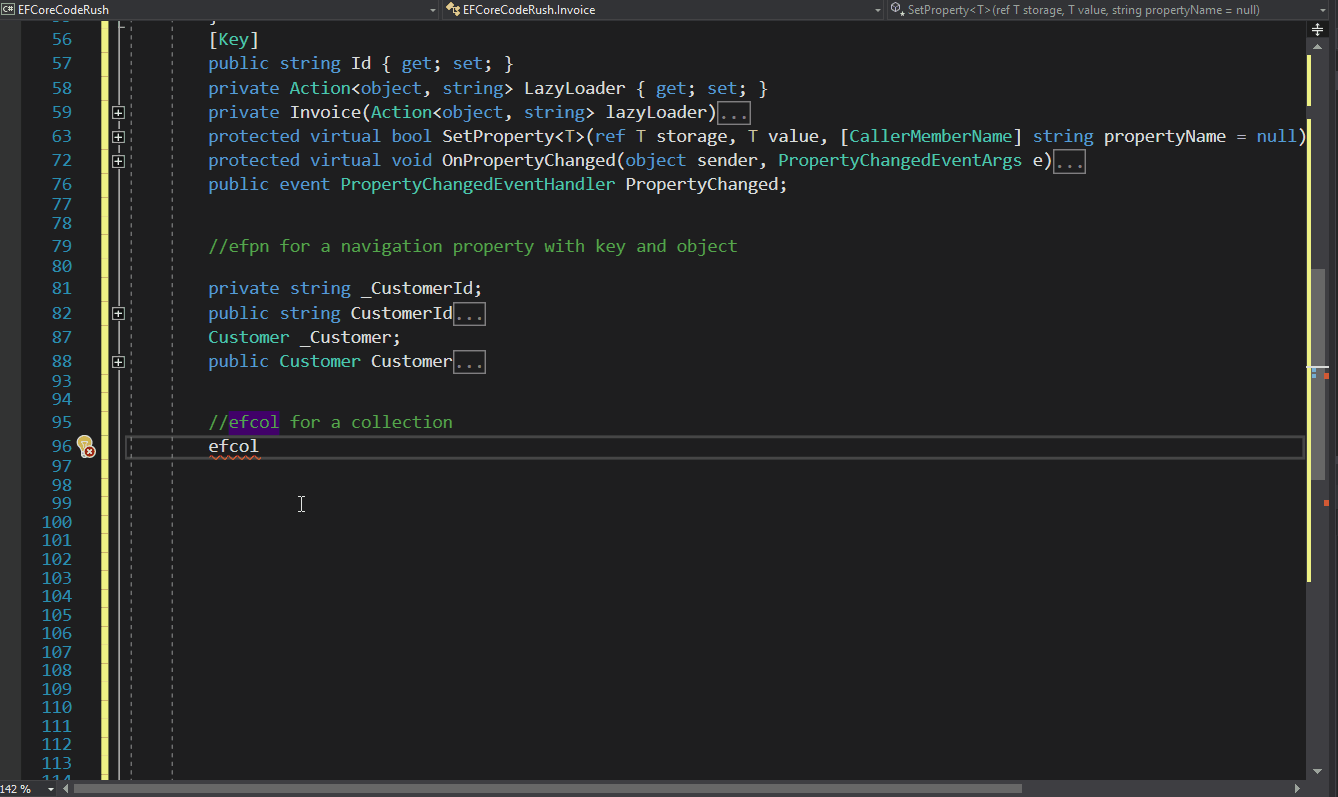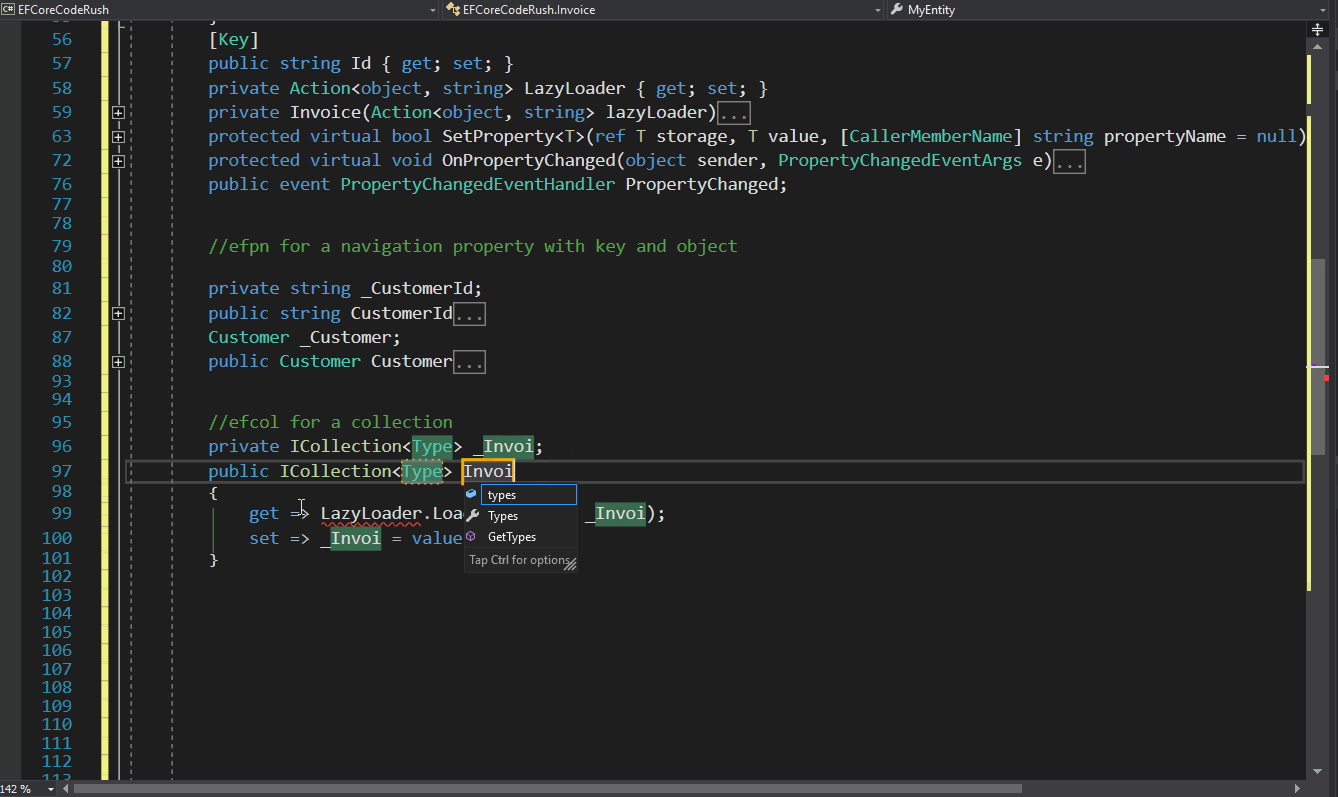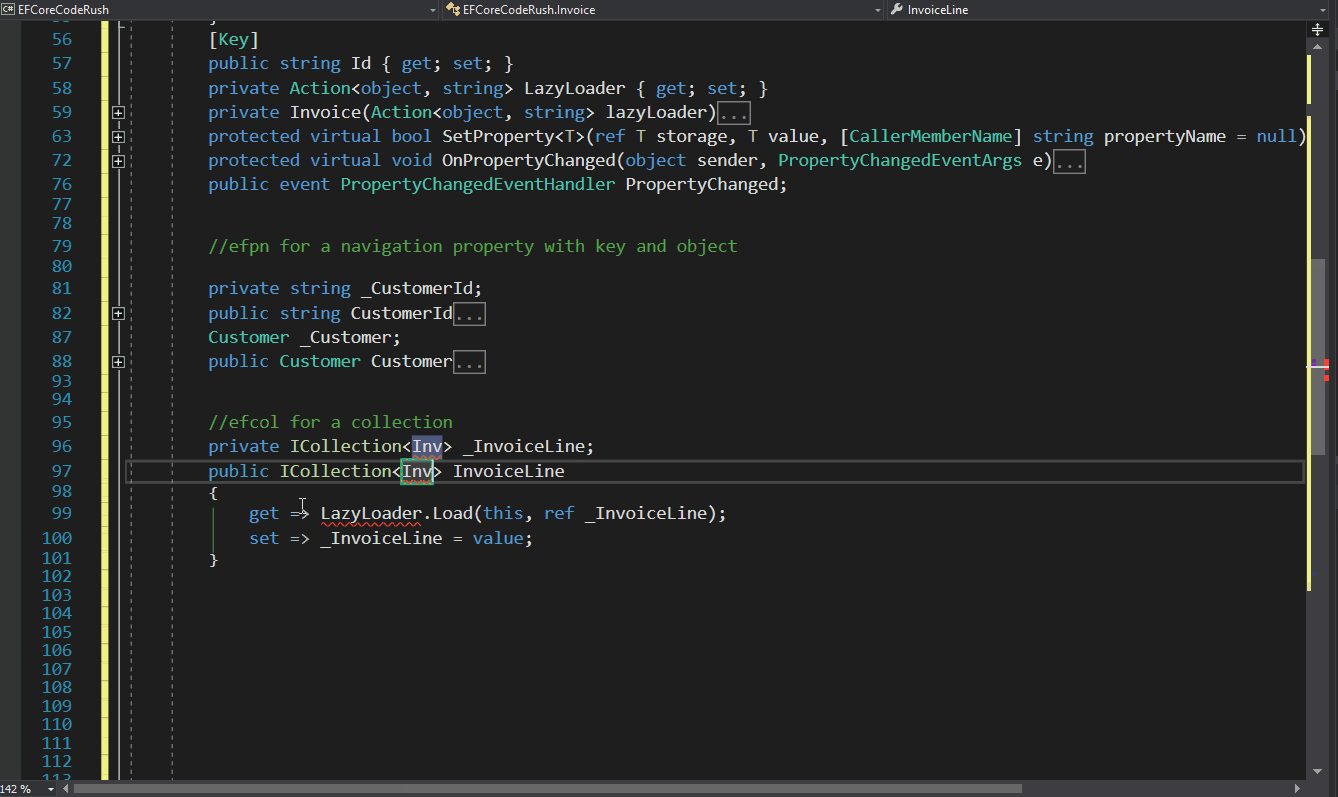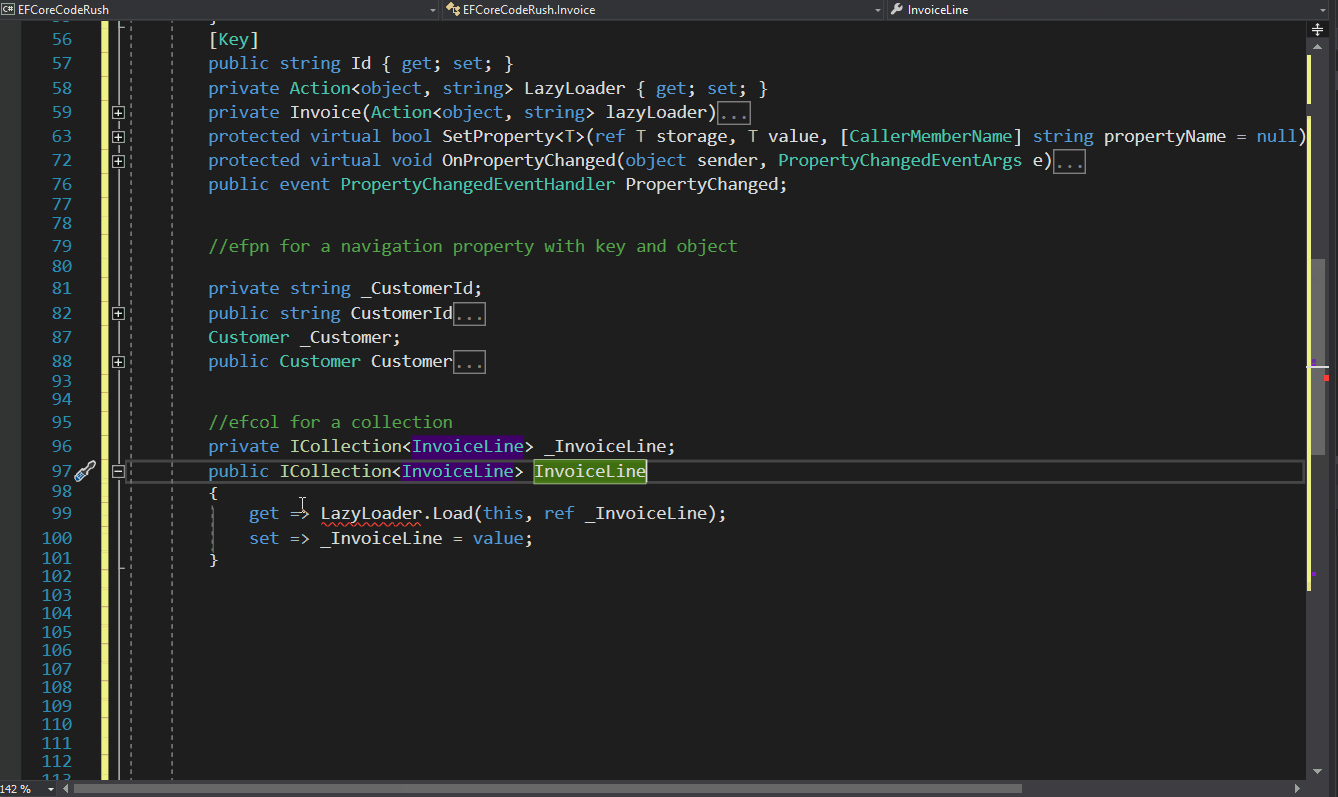
Implement the synchronization node functionality in an Entity Framework DbContext(ISyncClientNode)
Create a test scenario
1 Find out how entity framework converts the changes that happen to the objects to SQL commands
In our companies (BitFrameworks & Xari) we have been working in data synchronization for a while, but all this work has been done in the XPO realm.
public abstract class ModificationCommandBatch
{
/// <summary>
/// The list of conceptual insert/update/delete <see cref="ModificationCommands" />s in the batch.
/// </summary>
public abstract IReadOnlyList<IReadOnlyModificationCommand> ModificationCommands { get; }
now let’s take look into the ModificationCommand https://github.com/dotnet/efcore/blob/main/src/EFCore.Relational/Update/ModificationCommand.cs this class provides all the information about the changes that will be converted into SQL commands, which means that if we serialize this object and save it as a delta we can then send it to another node and replicate the changes…VOILA!!!
So now we know where the changes that we need to keep track of are, now let’s try to understand how those changes are converted into SQL commands and then executed into the database.
2 Decide what information we need to track and save as a delta
Entity framework core uses dependency injection to be able to handle different database engines so the idea here is that there are a lot of small services that can be replaced in other to create a different implementation, for example, SQLite, SqlServer, Postgres, etc …
After a lot of digging, I found that the service that is in charge of generating the update commands (insert, update and delete) UpdateSqlGenerator
this class implements IUpdateSqlGenerator https://github.com/dotnet/efcore/blob/main/src/EFCore.Relational/Update/IUpdateSqlGenerator.cs and as you can see all methods receive a string builder and a ModificationCommand so this is the service in charge of translating the ModificationCommand into SQL commands and SQL commands are easy to serialize because they are just text, so this is what we are going to serialize and save as a delta
public interface IUpdateSqlGenerator
{
/// <summary>
/// Generates SQL that will obtain the next value in the given sequence.
/// </summary>
/// <param name="name">The name of the sequence.</param>
/// <param name="schema">The schema that contains the sequence, or <see langword="null" /> to use the default schema.</param>
/// <returns>The SQL.</returns>
string GenerateNextSequenceValueOperation(string name, string? schema);
/// <summary>
/// Generates a SQL fragment that will get the next value from the given sequence and appends it to
/// the full command being built by the given <see cref="StringBuilder" />.
/// </summary>
/// <param name="commandStringBuilder">The builder to which the SQL fragment should be appended.</param>
/// <param name="name">The name of the sequence.</param>
/// <param name="schema">The schema that contains the sequence, or <see langword="null" /> to use the default schema.</param>
void AppendNextSequenceValueOperation(
StringBuilder commandStringBuilder,
string name,
string? schema);
/// <summary>
/// Appends a SQL fragment for the start of a batch to
/// the full command being built by the given <see cref="StringBuilder" />.
/// </summary>
/// <param name="commandStringBuilder">The builder to which the SQL fragment should be appended.</param>
void AppendBatchHeader(StringBuilder commandStringBuilder);
/// <summary>
/// Appends a SQL command for deleting a row to the commands being built.
/// </summary>
/// <param name="commandStringBuilder">The builder to which the SQL should be appended.</param>
/// <param name="command">The command that represents the delete operation.</param>
/// <param name="commandPosition">The ordinal of this command in the batch.</param>
/// <returns>The <see cref="ResultSetMapping" /> for the command.</returns>
ResultSetMapping AppendDeleteOperation(
StringBuilder commandStringBuilder,
IReadOnlyModificationCommand command,
int commandPosition);
/// <summary>
/// Appends a SQL command for inserting a row to the commands being built.
/// </summary>
/// <param name="commandStringBuilder">The builder to which the SQL should be appended.</param>
/// <param name="command">The command that represents the delete operation.</param>
/// <param name="commandPosition">The ordinal of this command in the batch.</param>
/// <returns>The <see cref="ResultSetMapping" /> for the command.</returns>
ResultSetMapping AppendInsertOperation(
StringBuilder commandStringBuilder,
IReadOnlyModificationCommand command,
int commandPosition);
/// <summary>
/// Appends a SQL command for updating a row to the commands being built.
/// </summary>
/// <param name="commandStringBuilder">The builder to which the SQL should be appended.</param>
/// <param name="command">The command that represents the delete operation.</param>
/// <param name="commandPosition">The ordinal of this command in the batch.</param>
/// <returns>The <see cref="ResultSetMapping" /> for the command.</returns>
ResultSetMapping AppendUpdateOperation(
StringBuilder commandStringBuilder,
IReadOnlyModificationCommand command,
int commandPosition);
}
3 Create the infrastructure to save deltas (Implementing IDeltaStore)
Now is time to create a delta store, this is an easy one since we only need to inherit from our delta store base and save the information in an entity framework DbContext, so here is the implementation
4 Create the infrastructure to process deltas (implementing IDeltaProcessor)
So far, we know what we need to store in the deltas which basically is SQL commands and their parameters so it means to process those SQL Commands our delta processor needs to create a database connection and execute SQL commands
public EFDeltaProcessor(DbContext dBContext)
{
_dBContext = dBContext;
}
public EFDeltaProcessor(string connectionstring, string DbEngineAlias, string ProviderInvariantName)
{
this.CurrentDbEngine = DbEngineAlias;
this.connectionString = connectionstring;
try
{
factory = DbProviderFactories.GetFactory(ProviderInvariantName);
}
catch (Exception ex)
{
Debug.WriteLine(ex.Message);
throw new Exception("There was a problem creating the database connection using DbProviderFactories.GetFactory. Please your make sure the DbProviderFactory for your database is registered https://docs.microsoft.com/en-us/dotnet/api/system.data.common.dbproviderfactories.registerfactory?view=net-5.0", ex);
}
//TODO check provider registration later
//DbProviderFactories.RegisterFactory("Microsoft.Data.SqlClient", SqlClientFactory.Instance);
}
there are a few things to notice in that class, first, it has 2 constructors because we need 2 different ways to create the connection to the database, one using the entity framework DbContext and one using ADO.NET DbProviderFactory
All the magic happens in the ProcessDeltas method, this method is in charge of, extract the content of the deltas and transforming them into SQL commands and parameters, and then executing the command.
please notice that the content of each delta is an instance of ModificationCommandData
which is a class that allows us to store multiple SQL commands (for different database engines) and their parameters
5 Implement the synchronization node functionality in an Entity Framework DbContext(ISyncClientNode)
At the moment we are able to produce and process deltas for entity framework relational, so the next step is to implement the functionality of synchronization client node by implementing the following interface
I’m not going to show the implementation of the server since that implementation is generic and uses the same delta store and delta processor that we created at the beginning of this article. for more information check the following links