by Joche Ojeda | Oct 21, 2024 | A.I, Semantic Kernel
A few weeks ago, I received the exciting news that DevExpress had released a new chat component (you can read more about it here). This was a big deal for me because I had been experimenting with the Semantic Kernel for almost a year. Most of my experiments fell into three categories:
- NUnit projects with no UI (useful when you need to prove a concept).
- XAF ASP.NET projects using a large textbox (String with unlimited size in XAF) to emulate a chat control.
- XAF applications using a custom chat component that I developed—which, honestly, didn’t look great because I’m more of a backend developer than a UI specialist. Still, the component did the job.
Once I got my hands on the new Chat component, the first thing I did was write a property editor to easily integrate it into XAF. You can read more about property editors in XAF here.
With the Chat component property editor in place, I had the necessary tool to accelerate my experiments with the Semantic Kernel (learn more about the Semantic Kernel here).
The Current Experiment
A few weeks ago, I wrote an implementation of the Semantic Kernel Memory Store using DevExpress’s XPO as the data storage solution. You can read about that implementation here. The next step was to integrate this Semantic Memory Store into XAF, and that’s now done. Details about that process can be found here.
What We Have So Far
- A Chat component property editor for XAF.
- A Semantic Kernel Memory Store for XPO that’s compatible with XAF.
With these two pieces, we can create an interesting prototype. The goals for this experiment are:
- Saving “memories” into a domain object (via XPO).
- Querying these memories through the Chat component property editor, using Semantic Kernel chat completions (compatible with all OpenAI APIs).
Step 1: Memory Collection Object
The first thing we need is an object that represents a collection of memories. Here’s the implementation:
[DefaultClassOptions]
public class MemoryChat : BaseObject
{
public MemoryChat(Session session) : base(session) {}
public override void AfterConstruction()
{
base.AfterConstruction();
this.MinimumRelevanceScore = 0.20;
}
double minimumRelevanceScore;
string name;
[Size(SizeAttribute.DefaultStringMappingFieldSize)]
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public double MinimumRelevanceScore
{
get => minimumRelevanceScore;
set => SetPropertyValue(nameof(MinimumRelevanceScore), ref minimumRelevanceScore, value);
}
[Association("MemoryChat-MemoryEntries")]
public XPCollection<MemoryEntry> MemoryEntries
{
get => GetCollection<MemoryEntry>(nameof(MemoryEntries));
}
}
This is a simple object. The two main properties are the MinimumRelevanceScore, which is used for similarity searches with embeddings, and the collection of MemoryEntries, where different memories are stored.
Step 2: Adding Memories
The next task is to easily append memories to that collection. I decided to use a non-persistent object displayed in a popup view with a large text area. When the user confirms the action in the dialog, the text gets vectorized and stored as a memory in the collection. You can see the implementation of the view controller here.
Let me highlight the important parts.
When we create the view for the popup window:
private void AppendMemory_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
var os = this.Application.CreateObjectSpace(typeof(TextMemory));
var textMemory = os.CreateObject<TextMemory>();
e.View = this.Application.CreateDetailView(os, textMemory);
}
The goal is to show a large textbox where the user can type any text. When they confirm, the text is vectorized and stored as a memory.
Next, storing the memory:
private async void AppendMemory_Execute(object sender, PopupWindowShowActionExecuteEventArgs e)
{
var textMemory = e.PopupWindowViewSelectedObjects[0] as TextMemory;
var currentMemoryChat = e.SelectedObjects[0] as MemoryChat;
var store = XpoMemoryStore.ConnectAsync(xafEntryManager).GetAwaiter().GetResult();
var semanticTextMemory = GetSemanticTextMemory(store);
await semanticTextMemory.SaveInformationAsync(currentMemoryChat.Name, id: Guid.NewGuid().ToString(), text: textMemory.Content);
}
Here, the GetSemanticTextMemory method plays a key role:
private static SemanticTextMemory GetSemanticTextMemory(XpoMemoryStore store)
{
var embeddingModelId = "text-embedding-3-small";
var getKey = () => Environment.GetEnvironmentVariable("OpenAiTestKey", EnvironmentVariableTarget.Machine);
var kernel = Kernel.CreateBuilder()
.AddOpenAIChatCompletion(ChatModelId, getKey.Invoke())
.AddOpenAITextEmbeddingGeneration(embeddingModelId, getKey.Invoke())
.Build();
var embeddingGenerator = new OpenAITextEmbeddingGenerationService(embeddingModelId, getKey.Invoke());
return new SemanticTextMemory(store, embeddingGenerator);
}
This method sets up an embedding generator used to create semantic memories.
Step 3: Querying Memories
To query the stored memories, I created a non-persistent type that interacts with the chat component:
public interface IMemoryData
{
IChatCompletionService ChatCompletionService { get; set; }
SemanticTextMemory SemanticTextMemory { get; set; }
string CollectionName { get; set; }
string Prompt { get; set; }
double MinimumRelevanceScore { get; set; }
}
This interface provides the necessary services to interact with the chat component, including ChatCompletionService and SemanticTextMemory.
Step 4: Handling Messages
Lastly, we handle message-sent callbacks, as explained in this article:
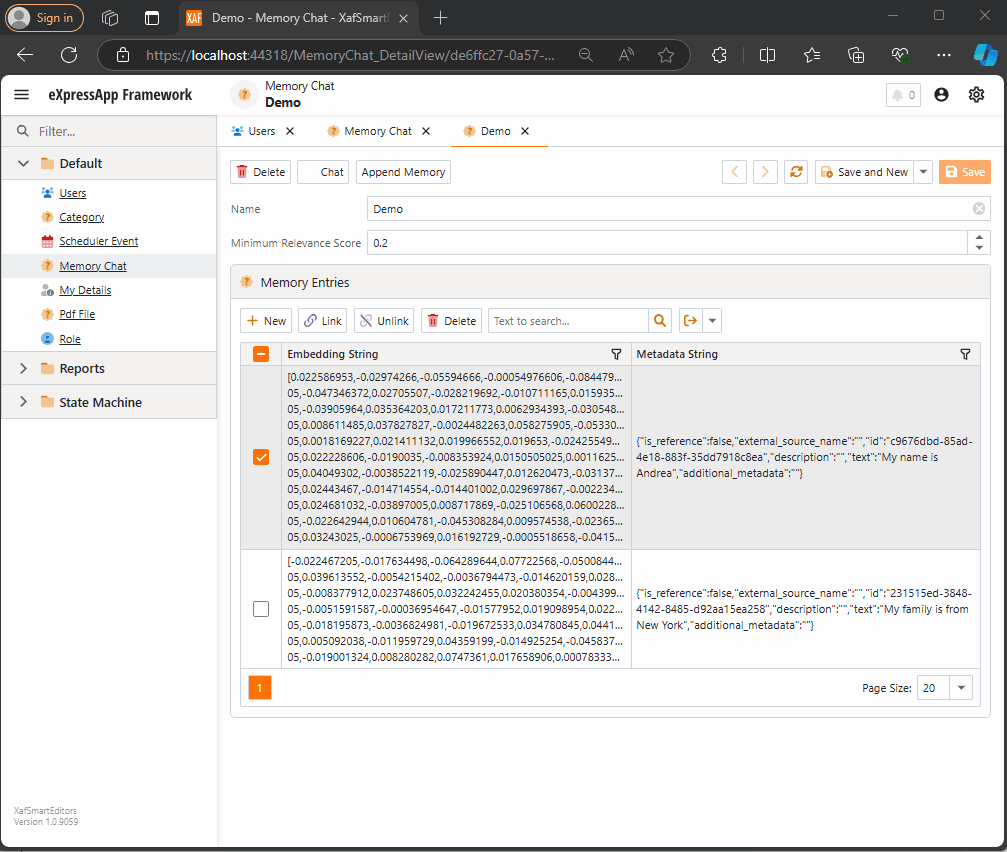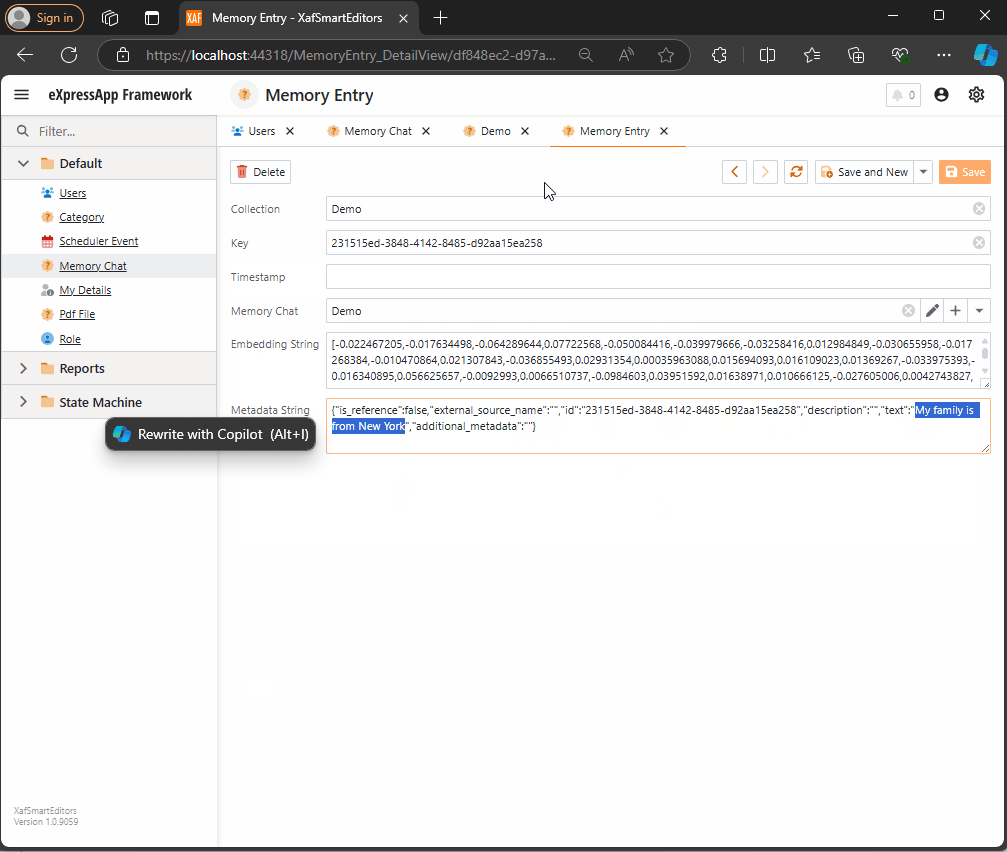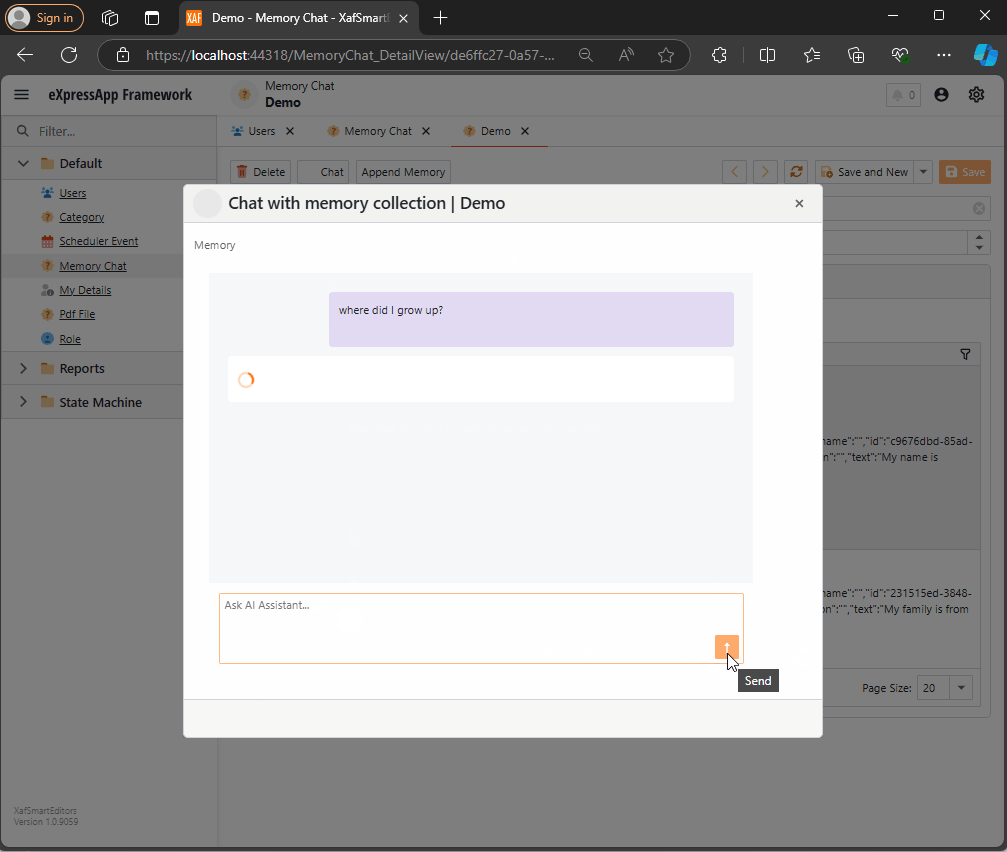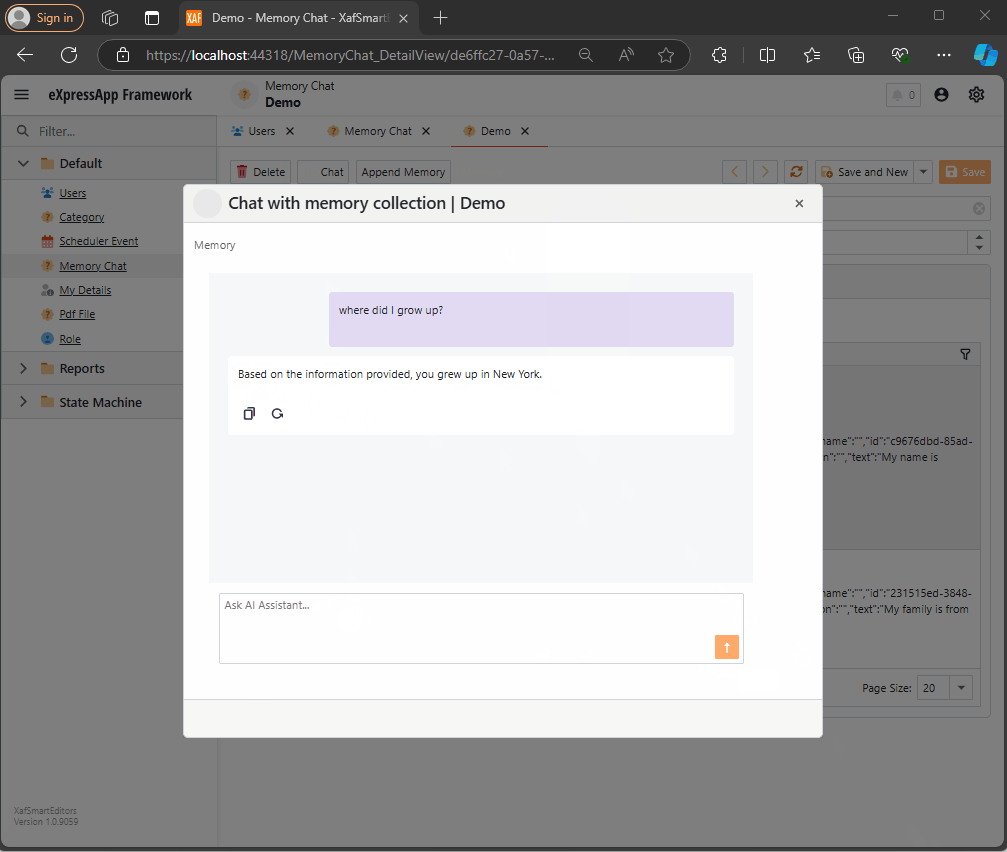
async Task MessageSent(MessageSentEventArgs args)
{
ChatHistory.AddUserMessage(args.Content);
var answers = Value.SemanticTextMemory.SearchAsync(
collection: Value.CollectionName,
query: args.Content,
limit: 1,
minRelevanceScore: Value.MinimumRelevanceScore,
withEmbeddings: true
);
string answerValue = "No answer";
await foreach (var answer in answers)
{
answerValue = answer.Metadata.Text;
}
string messageContent = answerValue == "No answer"
? "There are no memories containing the requested information."
: await Value.ChatCompletionService.GetChatMessageContentAsync($"You are an assistant queried for information. Use this data: {answerValue} to answer the question: {args.Content}.");
ChatHistory.AddAssistantMessage(messageContent);
args.SendMessage(new Message(MessageRole.Assistant, messageContent));
}
Here, we intercept the message, query the SemanticTextMemory, and use the results to generate an answer with the chat completion service.
This was a long post, but I hope it’s useful for you all. Until next time—XAF OUT!
You can find the full implementation on this repo

by Joche Ojeda | Oct 15, 2024 | A.I, Semantic Kernel, XAF, XPO
A few weeks ago, I forked the Semantic Kernel repository to experiment with it. One of my first experiments was to create a memory provider for XPO. The task was not too difficult; basically, I needed to implement the IMemoryStore interface, add some XPO boilerplate code, and just like that, we extended the Semantic Kernel memory store to support 10+ databases. You can check out the code for the XpoMemoryStore here.
My initial goal in creating the XpoMemoryStore was simply to see if XPO would be a good fit for handling embeddings. Spoiler alert: it was! To understand the basic functionality of the plugin, you can take a look at the integration test here.
As you can see, usage is straightforward. You start by connecting to the database that handles embedding collections, and all you need is a valid XPO connection string:
using XpoMemoryStore db = await XpoMemoryStore.ConnectAsync("XPO connection string");
In my original design, everything worked fine, but I faced some challenges when trying to use my new XpoMemoryStore in XAF. Here’s what I encountered:
- The implementation of XpoMemoryStore uses its own data layer, which can lead to issues. This needs to be rewritten to use the same data layer as XAF.
- The XpoEntry implementation cannot be extended. In some use cases, you might want to use a different object to store the embeddings, perhaps one that has an association with another object.
To address these problems, I introduced the IXpoEntryManager interface. The goal of this interface is to handle object creation and queries.
public interface IXpoEntryManager
{
T CreateObject();
public event EventHandler ObjectCreatedEvent;
void Commit();
IQueryable GetQuery(bool inTransaction = true);
void Delete(object instance);
void Dispose();
}
Now, object creation is handled through the CreateObject<T> method, allowing the underlying implementation to be changed to use a UnitOfWork or ObjectSpace. There’s also the ObjectCreatedEvent event, which lets you access the newly created object in case you need to associate it with another object. Lastly, the GetQuery<T> method enables redirecting the search for records to a different type.
I’ll keep updating the code as needed. If you’d like to discuss AI, XAF, or .NET, feel free to schedule a meeting: Schedule a Meeting with us.
Until next time, XAF out!
Related Article
https://www.jocheojeda.com/2024/09/04/using-the-imemorystore-interface-and-devexpress-xpo-orm-to-implement-a-custom-memory-store-for-semantic-kernel/
by Joche Ojeda | Oct 11, 2024 | A.I, DevExpress, XAF
Today is Friday, so I decided to take it easy with my integration research. When I woke up, I decided that I just wanted to read the source code of DevExpress AI integrations to get inspired. I began by reading the official blog post about AI and reporting (DevExpress Blog Post). Then, as usual, I proceeded to fork the repository to make my own modifications.
After completing the typical cloning procedure in Visual Studio, I realized that to use the AI functionalities of XtraReport, you don’t need any special version of the report viewer.
The only requirement is to have the NuGet reference as shown below:
<ItemGroup>
<PackageReference Include="DevExpress.AIIntegration.Blazor.Reporting.Viewer" Version="24.2.1-alpha-24260" />
</ItemGroup>
Then, add the report integration as shown below:
config.AddBlazorReportingAIIntegration(config =>
{
config.SummarizeBehavior = SummarizeBehavior.Abstractive;
config.AvailableLanguages = new List<LanguageItem>
{
new LanguageItem { Key = "de", Text = "German" },
new LanguageItem { Key = "es", Text = "Spanish" },
new LanguageItem { Key = "en", Text = "English" },
new LanguageItem { Key = "ru", Text = "Russian" },
new LanguageItem { Key = "it", Text = "Italian" }
};
});
After completing these steps, your report viewer will display a little star in the options menu, where you can invoke the AI operations.
You can find the source code for this example in my GitHub repository: https://github.com/egarim/XafSmartEditors
Till next time, XAF out!!!
by Joche Ojeda | Oct 10, 2024 | A.I, PropertyEditors, XAF
The New Era of Smart Editors: Developer Express and AI Integration
The new era of smart editors is already here. Developer Express has introduced AI functionality in many of their controls for .NET (Windows Forms, Blazor, WPF, MAUI).
This advancement will eventually come to XAF, but in the meantime, here at XARI, we are experimenting with XAF integrations to add value to our customers.
In this article, we are going to integrate the new chat component into an XAF application, and our first use case will be RAG (Retrieval-Augmented Generation). RAG is a system that combines external data sources with AI-generated responses, improving accuracy and relevance in answers by retrieving information from a document set or knowledge base and using it in conjunction with AI predictions.
To achieve this integration, we will follow the steps outlined in this tutorial:
Implement a Property Editor Based on Custom Components (Blazor)
Implementing the Property Editor
When I implement my own property editor, I usually avoid doing so for primitive types because, in most cases, my property editor will need more information than a simple primitive value. For this implementation, I want to handle a custom value in my property editor. I typically create an interface to represent the type, ensuring compatibility with both XPO and EF Core.
namespace XafSmartEditors.Razor.RagChat
{
public interface IRagData
{
Stream FileContent { get; set; }
string Prompt { get; set; }
string FileName { get; set; }
}
}
Non-Persistent Implementation
After defining the type for my editor, I need to create a non-persistent implementation:
namespace XafSmartEditors.Razor.RagChat
{
[DomainComponent]
public class IRagDataImp : IRagData, IXafEntityObject, INotifyPropertyChanged
{
private void OnPropertyChanged([CallerMemberName] string propertyName = null)
{
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(propertyName));
}
public IRagDataImp()
{
Oid = Guid.NewGuid();
}
[DevExpress.ExpressApp.Data.Key]
[Browsable(false)]
public Guid Oid { get; set; }
private string prompt;
private string fileName;
private Stream fileContent;
public Stream FileContent
{
get => fileContent;
set
{
if (fileContent == value) return;
fileContent = value;
OnPropertyChanged();
}
}
public string FileName
{
get => fileName;
set
{
if (fileName == value) return;
fileName = value;
OnPropertyChanged();
}
}
public string Prompt
{
get => prompt;
set
{
if (prompt == value) return;
prompt = value;
OnPropertyChanged();
}
}
// IXafEntityObject members
void IXafEntityObject.OnCreated() { }
void IXafEntityObject.OnLoaded() { }
void IXafEntityObject.OnSaving() { }
public event PropertyChangedEventHandler PropertyChanged;
}
}
Creating the Blazor Chat Component
Now, it’s time to create our Blazor component and add the new DevExpress chat component for Blazor:
<DxAIChat CssClass="my-chat" Initialized="Initialized"
RenderMode="AnswerRenderMode.Markdown"
UseStreaming="true"
SizeMode="SizeMode.Medium">
<EmptyMessageAreaTemplate>
<div class="my-chat-ui-description">
<span style="font-weight: bold; color: #008000;">Rag Chat</span> Assistant is ready to answer your questions.
</div>
</EmptyMessageAreaTemplate>
<MessageContentTemplate>
<div class="my-chat-content">
@ToHtml(context.Content)
</div>
</MessageContentTemplate>
</DxAIChat>
@code {
IRagData _value;
[Parameter]
public IRagData Value
{
get => _value;
set => _value = value;
}
async Task Initialized(IAIChat chat)
{
await chat.UseAssistantAsync(new OpenAIAssistantOptions(
this.Value.FileName,
this.Value.FileContent,
this.Value.Prompt
));
}
MarkupString ToHtml(string text)
{
return (MarkupString)Markdown.ToHtml(text);
}
}
The main takeaway from this component is that it receives a parameter named Value of type IRagData, and we use this value to initialize the IAIChat service in the Initialized method.
Creating the Component Model
With the interface and domain component in place, we can now create the component model to communicate the value of our domain object with the Blazor component:
namespace XafSmartEditors.Razor.RagChat
{
public class RagDataComponentModel : ComponentModelBase
{
public IRagData Value
{
get => GetPropertyValue<IRagData>();
set => SetPropertyValue(value);
}
public EventCallback<IRagData> ValueChanged
{
get => GetPropertyValue<EventCallback<IRagData>>();
set => SetPropertyValue(value);
}
public override Type ComponentType => typeof(RagChat);
}
}
Creating the Property Editor
Finally, let’s create the property editor class that serves as a bridge between XAF and the new component:
namespace XafSmartEditors.Blazor.Server.Editors
{
[PropertyEditor(typeof(IRagData), true)]
public class IRagDataPropertyEditor : BlazorPropertyEditorBase, IComplexViewItem
{
private IObjectSpace _objectSpace;
private XafApplication _application;
public IRagDataPropertyEditor(Type objectType, IModelMemberViewItem model) : base(objectType, model) { }
public void Setup(IObjectSpace objectSpace, XafApplication application)
{
_objectSpace = objectSpace;
_application = application;
}
public override RagDataComponentModel ComponentModel => (RagDataComponentModel)base.ComponentModel;
protected override IComponentModel CreateComponentModel()
{
var model = new RagDataComponentModel();
model.ValueChanged = EventCallback.Factory.Create<IRagData>(this, value =>
{
model.Value = value;
OnControlValueChanged();
WriteValue();
});
return model;
}
protected override void ReadValueCore()
{
base.ReadValueCore();
ComponentModel.Value = (IRagData)PropertyValue;
}
protected override object GetControlValueCore() => ComponentModel.Value;
protected override void ApplyReadOnly()
{
base.ApplyReadOnly();
ComponentModel?.SetAttribute("readonly", !AllowEdit);
}
}
}
Bringing It All Together
Now, let’s create a domain object that can feed the content of a file to our chat component:
namespace XafSmartEditors.Module.BusinessObjects
{
[DefaultClassOptions]
public class PdfFile : BaseObject
{
public PdfFile(Session session) : base(session) { }
string prompt;
string name;
FileData file;
public FileData File
{
get => file;
set => SetPropertyValue(nameof(File), ref file, value);
}
public string Name
{
get => name;
set => SetPropertyValue(nameof(Name), ref name, value);
}
public string Prompt
{
get => prompt;
set => SetPropertyValue(nameof(Prompt), ref prompt, value);
}
}
}
Creating the Controller
We are almost done! Now, we need to create a controller with a popup action:
namespace XafSmartEditors.Module.Controllers
{
public class OpenChatController : ViewController
{
Popup
WindowShowAction Chat;
public OpenChatController()
{
this.TargetObjectType = typeof(PdfFile);
Chat = new PopupWindowShowAction(this, "ChatAction", "View");
Chat.Caption = "Chat";
Chat.ImageName = "artificial_intelligence";
Chat.Execute += Chat_Execute;
Chat.CustomizePopupWindowParams += Chat_CustomizePopupWindowParams;
}
private void Chat_Execute(object sender, PopupWindowShowActionExecuteEventArgs e) { }
private void Chat_CustomizePopupWindowParams(object sender, CustomizePopupWindowParamsEventArgs e)
{
PdfFile pdfFile = this.View.CurrentObject as PdfFile;
var os = this.Application.CreateObjectSpace(typeof(ChatView));
var chatView = os.CreateObject<ChatView>();
MemoryStream memoryStream = new MemoryStream();
pdfFile.File.SaveToStream(memoryStream);
memoryStream.Seek(0, SeekOrigin.Begin);
chatView.RagData = os.CreateObject<IRagDataImp>();
chatView.RagData.FileName = pdfFile.File.FileName;
chatView.RagData.Prompt = !string.IsNullOrEmpty(pdfFile.Prompt) ? pdfFile.Prompt : DefaultPrompt;
chatView.RagData.FileContent = memoryStream;
DetailView detailView = this.Application.CreateDetailView(os, chatView);
detailView.Caption = $"Chat with Document | {pdfFile.File.FileName.Trim()}";
e.View = detailView;
}
}
}
Conclusion
That’s everything we need to create a RAG system using XAF and the new DevExpress Chat component. You can find the complete source code here: GitHub Repository.
If you want to meet and discuss AI, XAF, and .NET, feel free to schedule a meeting: Schedule a Meeting.
Until next time, XAF out!

by Joche Ojeda | Oct 8, 2024 | A.I, Blazor, Semantic Kernel
Are you excited to bring powerful AI chat completions to your web application? I sure am! In this post, we’ll walk through how to integrate the DevExpress Chat component with the Semantic Kernel using OpenAI. This combination can make your app more interactive and intelligent, and it’s surprisingly simple to set up. Let’s dive in!
Step 1: Adding NuGet Packages
First, let’s ensure we have all the necessary packages. Open your DevExpress.AI.Samples.Blazor.csproj file and add the following NuGet references:
<ItemGroup>
<PackageReference Include="Microsoft.KernelMemory.Abstractions" Version="0.78.241007.1" />
<PackageReference Include="Microsoft.KernelMemory.Core" Version="0.78.241007.1" />
<PackageReference Include="Microsoft.SemanticKernel" Version="1.21.1" />
</ItemGroup>
This will bring in the core components of Semantic Kernel to power your chat completions.
Step 2: Setting Up Your Kernel in Program.cs
Next, we’ll configure the Semantic Kernel and OpenAI integration. Add the following code in your Program.cs to create the kernel and set up the chat completion service:
//Create your OpenAI client
string OpenAiKey = Environment.GetEnvironmentVariable("OpenAiTestKey");
var client = new OpenAIClient(new System.ClientModel.ApiKeyCredential(OpenAiKey));
//Adding semantic kernel
var KernelBuilder = Kernel.CreateBuilder();
KernelBuilder.AddOpenAIChatCompletion("gpt-4o", client);
var sk = KernelBuilder.Build();
var ChatService = sk.GetRequiredService<IChatCompletionService>();
builder.Services.AddSingleton<IChatCompletionService>(ChatService);
This step is crucial because it connects your app to OpenAI via the Semantic Kernel and sets up the chat completion service that will drive the AI responses in your chat.
Step 3: Creating the Chat Component
Now that we’ve got our services ready, it’s time to set up the chat component. We’ll define the chat interface in our Razor page. Here’s how you can do that:
Razor Section:
@page "/sk"
@using DevExpress.AIIntegration.Blazor.Chat
@using AIIntegration.Services.Chat;
@using Microsoft.SemanticKernel.ChatCompletion
@using System.Diagnostics
@using System.Text.Json
@using System.Text
@inject IChatCompletionService chatCompletionsService;
@inject IJSRuntime JSRuntime;
This UI will render a clean chat interface using DevExpress’s DxAIChat component, which is connected to our Semantic Kernel chat completion service.
Code Section:
Now, let’s handle the interaction logic. Here’s the code that powers the chat backend:
@code {
ChatHistory ChatHistory = new ChatHistory();
async Task MessageSent(MessageSentEventArgs args)
{
// Add the user's message to the chat history
ChatHistory.AddUserMessage(args.Content);
// Get a response from the chat completion service
var Result = await chatCompletionsService.GetChatMessageContentAsync(ChatHistory);
// Extract the response content
string MessageContent = Result.InnerContent.ToString();
Debug.WriteLine("Message from chat completion service:" + MessageContent);
// Add the assistant's message to the history
ChatHistory.AddAssistantMessage(MessageContent);
// Send the response to the UI
var message = new Message(MessageRole.Assistant, MessageContent);
args.SendMessage(message);
}
}
With this in place, every time the user sends a message, the chat completion service will process the conversation history and generate a response from OpenAI. The result is then displayed in the chat window.
Step 4: Run Your Project
Before running the project, ensure that the correct environment variable for the OpenAI key is set (OpenAiTestKey). This key is necessary for the integration to communicate with OpenAI’s API.
Now, you’re ready to test! Simply run your project and navigate to https://localhost:58108/sk. Voilà! You’ll see a beautiful, AI-powered chat interface waiting for your input. 🎉
Conclusion
And that’s it! You’ve successfully integrated the DevExpress Chat component with the Semantic Kernel for AI-powered chat completions. Now, you can take your user interaction to the next level with intelligent, context-aware responses. The possibilities are endless with this integration—whether you’re building a customer support chatbot, a productivity assistant, or something entirely new.
Let me know how your integration goes, and feel free to share what cool things you build with this!
here is the full implementation GitHub