by Joche Ojeda | Nov 2, 2024 | A.I, Semantic Kernel
Today, when I woke up, it was sunny but really cold, and the weather forecast said that snow was expected.
So, I decided to order ramen and do a “Saturday at home” type of project. My tools of choice for this experiment are:
1) DevExpress Chat Component for Blazor
I’m thrilled they have this component. I once wrote my own chat component, and it’s a challenging task, especially given the variety of use cases.
2) Semantic Kernel
I’ve been experimenting with Semantic Kernel for a while now, and let me tell you—it’s a fantastic tool if you’re in the .NET ecosystem. It’s so cool to have native C# code to interact with AI services in a flexible way, making your code mostly agnostic to the AI provider—like a WCF for AIs.
Goal of the Experiment
The goal for today’s experiment is to render a list of products as a carousel within a chat conversation.
Configuration
To accomplish this, I’ll use prompt execution settings in Semantic Kernel to ensure that the response from the LLM is always in JSON format as a string.
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
The key part here is the response format. The chat completion can respond in two ways:
- Text: A simple text answer.
- JSON Object: This format always returns a JSON object, with the structure provided as part of the prompt.
With this approach, we can deserialize the LLM’s response to an object that helps conditionally render the message content within the DevExpress Chat Component.
Structure
Here’s the structure I’m using:
public class MessageData
{
public string Message { get; set; }
public List Options { get; set; }
public string MessageTemplateName { get; set; }
}
public class OptionSet
{
public string Name { get; set; }
public string Description { get; set; }
public List Options { get; set; }
}
public class Option
{
public string Image { get; set; }
public string Url { get; set; }
public string Description { get; set; }
};
- MessageData: This structure will always be returned by our LLM.
- Option: A list of options for a message, which also serves as data for possible responses.
- OptionSet: A list of possible responses to feed into the prompt execution settings.
Prompt Execution Settings
One more step on the Semantic Kernel side is configuring the prompt execution settings:
var Settings = new OpenAIPromptExecutionSettings
{
MaxTokens = 500,
Temperature = 0.5,
ResponseFormat = "json_object"
};
Settings.ChatSystemPrompt = $"You need to answer using this JSON format with this structure {Structure} " +
$"Before giving an answer, check if it exists within this list of option sets {OptionSets}. " +
$"If your answer does not include options, the message template value should be 'Message'; otherwise, it should be 'Options'.";
In the prompt, we specify the structure {Structure} we want as a response, provide a list of possible options for the message in the {OptionSets} variable, and add a final line to guide the LLM on which template type to use.
Example Requests and Responses
For example, when executing the following request:
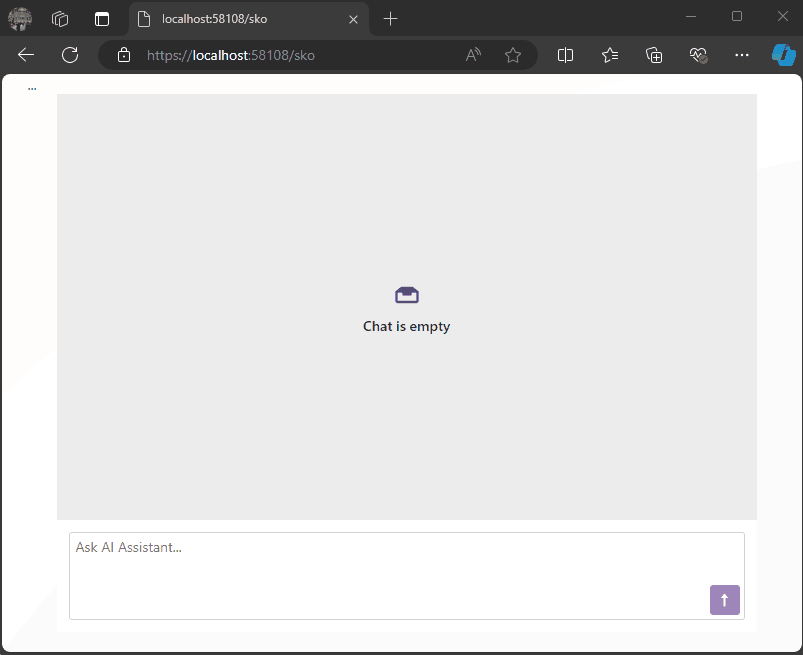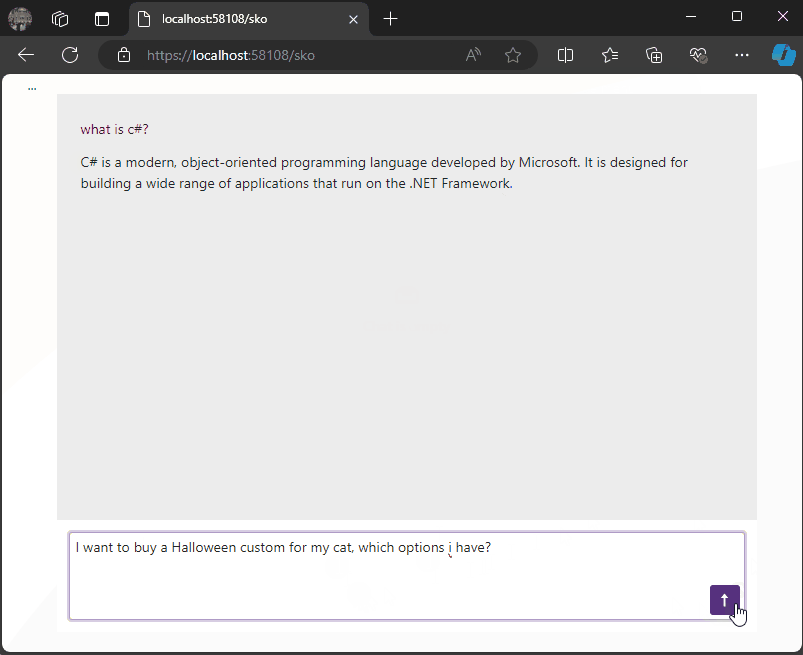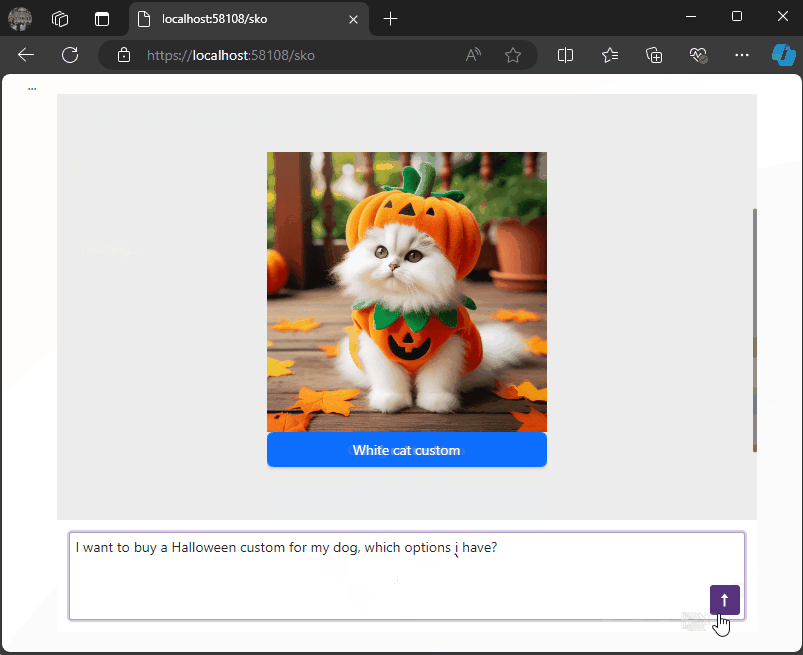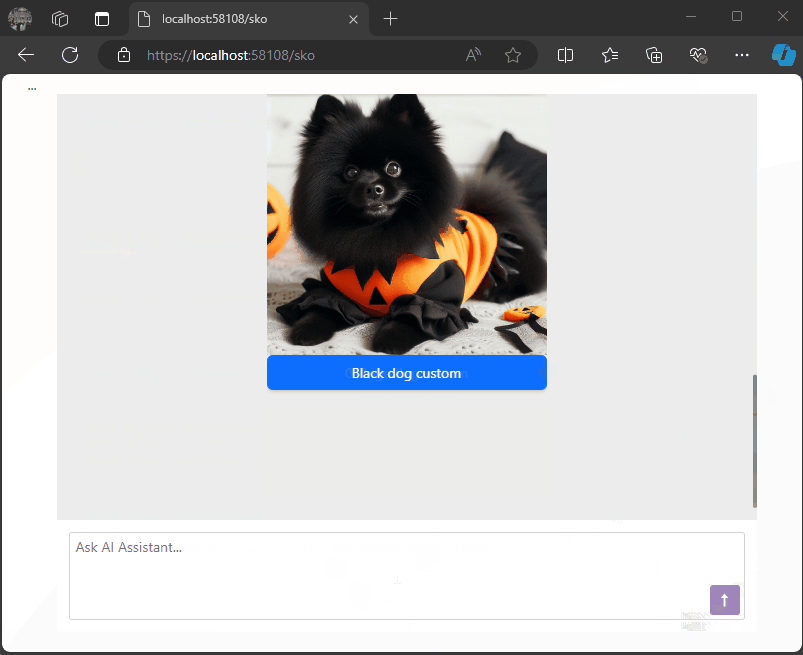
- Prompt: “Show me a list of Halloween costumes for cats.”
We’ll get this response from the LLM:
{
"Message": "Please select one of the Halloween costumes for cats",
"Options": [
{"Image": "./images/catblack.png", "Url": "https://cat.com/black", "Description": "Black cat costume"},
{"Image": "./images/catwhite.png", "Url": "https://cat.com/white", "Description": "White cat costume"},
{"Image": "./images/catorange.png", "Url": "https://cat.com/orange", "Description": "Orange cat costume"}
],
"MessageTemplateName": "Options"
}
With this JSON structure, we can conditionally render messages in the chat component as follows:
<DxAIChat CssClass="my-chat" MessageSent="MessageSent">
<MessageTemplate>
<div>
@{
if (@context.Typing)
{
<span>Loading...</span>
}
else
{
MessageData md = null;
try
{
md = JsonSerializer.Deserialize<MessageData>(context.Content);
}
catch
{
md = null;
}
if (md == null)
{
<div class="my-chat-content">
@context.Content
</div>
}
else
{
if (md.MessageTemplateName == "Options")
{
<div class="centered-carousel">
<Carousel class="carousel-container" Width="280" IsFade="true">
@foreach (var option in md.Options)
{
<CarouselItem>
<ChildContent>
<div>
<img src="@option.Image" alt="demo-image" />
<Button Color="Color.Primary" class="carousel-button">@option.Description</Button>
</div>
</ChildContent>
</CarouselItem>
}
</Carousel>
</div>
}
else if (md.MessageTemplateName == "Message")
{
<div class="my-chat-content">
@md.Message
</div>
}
}
}
}
</div>
</MessageTemplate>
</DxAIChat>
End Solution Example
Here’s an example of the final solution:
You can find the full source code here: https://github.com/egarim/devexpress-ai-chat-samples and a short video here https://youtu.be/dxMnOWbe3KA

by Joche Ojeda | Sep 4, 2024 | A.I, Semantic Kernel
In the world of AI and large language models (LLMs), understanding how to manage memory is crucial for creating applications that feel responsive and intelligent. Many developers are turning to Semantic Kernel, a lightweight and open-source development kit, to integrate these capabilities into their applications. For those already familiar with Semantic Kernel, let’s dive into how memory functions within this framework, especially when interacting with LLMs via chat completions.
Chat Completions: The Most Common Interaction with LLMs
When it comes to interacting with LLMs, one of the most intuitive and widely used methods is through chat completions. This allows developers to simulate a conversation between a user and an AI agent, facilitating various use cases like building chatbots, automating business processes, or even generating code.
In Semantic Kernel, chat completions are implemented through models from popular providers like OpenAI, Google, and others. These models enable developers to manage the flow of conversation seamlessly. While using chat completions, one key aspect to keep in mind is how the conversation history is stored and managed.
Temporary Memory: ChatHistory and Kernel String Arguments
Within the Semantic Kernel framework, the memory that a chat completion model uses is managed by the ChatHistory object. This object stores the conversation history temporarily, meaning it captures the back-and-forth between the user and the model during an active session. Alternatively, you can use a string argument passed to the kernel, which contains context information for the conversation. However, like the ChatHistory, this method is also not persistent.
Once the host class is disposed of, all stored context and memory from both the ChatHistory object and the string argument are lost. This transient nature of memory means that these methods are useful only for short-term interactions and are destroyed after the session ends.
What’s Next? Exploring Long-Term Memory Options
In this article, we’ve discussed how Semantic Kernel manages short-term memory with ChatHistory and kernel string arguments. However, for more complex applications that require retaining memory over longer periods—think customer support agents or business process automation—temporary memory might not be sufficient. In the next article, we’ll explore the options available for implementing long-term memory within Semantic Kernel, providing insights on how to make your AI applications even more powerful and context-aware.
Stay tuned for the deep dive into long-term memory solutions!
by Joche Ojeda | Jan 7, 2024 | A.I
Introduction
In the ever-evolving landscape of artificial intelligence, LangChain has emerged as a pivotal framework for harnessing the capabilities of large language models like GPT-3. This article delves into what LangChain is, its historical development, its applications, and concludes with its potential future impact.
What is LangChain?
LangChain is a software framework designed to facilitate the integration and application of advanced language models in various computational tasks. Developed by Shawn Presser, it stands as a testament to the growing need for accessible and versatile tools in the realm of AI and natural language processing (NLP). LangChain’s primary aim is to provide a modular and scalable environment where developers can easily implement and customize language models for a wide range of applications.
Historical Development
The Advent of Large Language Models
The genesis of LangChain is closely linked to the emergence of large language models. With the introduction of models like GPT-3 by OpenAI, the AI community witnessed a significant leap in the ability of machines to understand and generate human-like text.
Shawn Presser and LangChain
Recognizing the potential of these models, Shawn Presser embarked on developing a framework that would simplify their integration into practical applications. His vision led to the creation of LangChain, which he open-sourced to encourage community-driven development and innovation.
Applications
LangChain has found a wide array of applications, thanks to its versatile nature:
- Customer Service: By powering chatbots with nuanced and context-aware responses, LangChain enhances customer interaction and satisfaction.
- Content Creation: The framework assists in generating diverse forms of written content, from articles to scripts, offering tools for creativity and efficiency.
- Data Analysis: LangChain can analyze large volumes of text, providing insights and summaries, which are invaluable in research and business intelligence.
Conclusion
The story of LangChain is not just about a software framework; it’s about the democratization of AI technology. By making powerful language models more accessible and easier to integrate, LangChain is paving the way for a future where AI can be more effectively harnessed across various sectors. Its continued development and the growing community around it suggest a future rich with innovative applications, making LangChain a key player in the unfolding narrative of AI’s role in our world.

by Joche Ojeda | Jan 3, 2024 | A.I
Enhancing AI Language Models with Retrieval-Augmented Generation
Introduction
In the world of natural language processing and artificial intelligence, researchers and developers are constantly searching for ways to improve the capabilities of AI language models. One of the latest innovations in this field is Retrieval-Augmented Generation (RAG), a technique that combines the power of language generation with the ability to retrieve relevant information from a knowledge source. In this article, we will explore what RAG is, how it works, and its potential applications in various industries.
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation is a method that enhances AI language models by allowing them to access external knowledge sources to generate more accurate and contextually relevant responses. Instead of relying solely on the model’s internal knowledge, RAG enables the AI to retrieve relevant information from a database or a knowledge source, such as Wikipedia, and use that information to generate a response.
How does Retrieval-Augmented Generation work?
RAG consists of two main components: a neural retriever and a neural generator. The neural retriever is responsible for finding relevant information from the external knowledge source. It does this by searching for documents that are most similar to the input text or query. Once the relevant documents are retrieved, the neural generator processes the retrieved information and generates a response based on the context provided by the input text and the retrieved documents.
The neural retriever and the neural generator work together to create a more accurate and contextually relevant response. This combination allows the AI to produce higher-quality outputs and reduces the likelihood of generating incorrect or nonsensical information.
Potential Applications of Retrieval-Augmented Generation
Retrieval-Augmented Generation has a wide range of potential applications in various industries. Some of the most promising use cases include:
- Customer service: RAG can be used to improve the quality of customer service chatbots, allowing them to provide more accurate and relevant information to customers.
- Education: RAG can be used to create educational tools that provide students with accurate and up-to-date information on a wide range of topics.
- Healthcare: RAG can be used to develop AI systems that can assist doctors and healthcare professionals by providing accurate and relevant medical information.
- News and media: RAG can be used to create AI-powered news and media platforms that can provide users with accurate and contextually relevant information on current events and topics.
Conclusion
Retrieval-Augmented Generation is a powerful technique that has the potential to significantly enhance the capabilities of AI language models. By combining the power of language generation with the ability to retrieve relevant information from external sources, RAG can provide more accurate and contextually relevant responses. As the technology continues to develop, we can expect to see a wide range of applications for RAG in various industries.

by Joche Ojeda | Dec 31, 2023 | A.I
Unpacking Memes and AI Embeddings: An Intriguing Intersection
The Essence of Embeddings in AI
In the realm of artificial intelligence, the concept of an embedding is pivotal. It’s a method of converting complex, high-dimensional data like text, images, or sounds into a lower-dimensional space. This transformation captures the essence of the data’s most relevant features.
Imagine a vast library of books. An embedding is like a skilled librarian who can distill each book into a single, insightful summary. This process enables machines to process and understand vast swathes of data more efficiently and meaningfully.
The Meme: A Cultural Embedding
A meme is a cultural artifact, often an image with text, that encapsulates a collective experience, emotion, or idea in a highly condensed format. It’s a snippet of culture, distilled down to its most essential and relatable elements.
The Intersection: AI Embeddings and Memes
The connection between AI embeddings and memes lies in their shared essence of abstraction and distillation. Both serve as compact representations of more complex entities. An AI embedding abstracts media into a form that captures its most relevant features, just as a meme condenses an experience or idea into a simple format.
Implications and Insights
This intersection offers fascinating implications. For instance, when AI learns to understand and generate memes, it’s tapping into the cultural and emotional undercurrents that memes represent. This requires a nuanced understanding of human experiences and societal contexts – a significant challenge for AI.
Moreover, the study of memes can inform AI research, leading to more adaptable and resilient AI models.
Conclusion
In conclusion, while AI embeddings and memes operate in different domains, they share a fundamental similarity in their approach to abstraction. This intersection opens up possibilities for both AI development and our understanding of cultural phenomena.