
by Joche Ojeda | Jan 15, 2025 | C#, dotnet, Emit, MetaProgramming, Reflection
Every programmer encounters that one technology that draws them into the darker arts of software development. For some, it’s metaprogramming; for others, it’s assembly hacking. For me, it was the mysterious world of runtime code generation through Emit in the early 2000s, during my adventures with XPO and the enigmatic Sage Accpac ERP.
The Quest Begins: A Tale of Documentation and Dark Arts
Back in the early 2000s, when the first version of XPO was released, I found myself working alongside my cousin Carlitos in our startup. Fresh from his stint as an ERP consultant in the United States, Carlitos brought with him deep knowledge of Sage Accpac, setting us on a path to provide integration services for this complex system.
Our daily bread and butter were custom reports – starting with Crystal Reports before graduating to DevExpress’s XtraReports and XtraPivotGrid. But we faced an interesting challenge: Accpac’s database was intentionally designed to resist reverse engineering, with flat tables devoid of constraints or relationships. All we had was their HTML documentation, a labyrinth of interconnected pages holding the secrets of their entity relationships.
Genesis: When Documentation Meets Dark Magic
This challenge birthed Project Genesis, my ambitious attempt to create an XPO class generator that could parse Accpac’s documentation. The first hurdle was parsing HTML – a quest that led me to CodePlex (yes, I’m dating myself here) and the discovery of HTMLAgilityPack, a remarkable tool that still serves developers today.
But the real dark magic emerged when I faced the challenge of generating classes dynamically. Buried in our library’s .NET books, I discovered the arcane art of Emit – a powerful technique for runtime assembly and class generation that would forever change my perspective on what’s possible in .NET.
Diving into the Abyss: Understanding Emit
At its core, Emit is like having a magical forge where you can craft code at runtime. Imagine being able to write code that writes more code – not just as text to be compiled later, but as actual, executable IL instructions that the CLR can run immediately.
AssemblyName assemblyName = new AssemblyName("DynamicAssembly");
AssemblyBuilder assemblyBuilder = AssemblyBuilder.DefineDynamicAssembly(
assemblyName,
AssemblyBuilderAccess.Run
);
This seemingly simple code opens a portal to one of .NET’s most powerful capabilities: dynamic assembly generation. It’s the beginning of a spell that allows you to craft types and methods from pure thought (and some carefully crafted IL instructions).
The Power and the Peril
Like all dark magic, Emit comes with its own dangers and responsibilities. When you’re generating IL directly, you’re dancing with the very fabric of .NET execution. One wrong move – one misplaced instruction – and your carefully crafted spell can backfire spectacularly.
The first rule of Emit Club is: don’t use Emit unless you absolutely have to. The second rule is: if you do use it, document everything meticulously. Your future self (and your team) will thank you.
Modern Alternatives and Evolution
Today, the .NET ecosystem offers alternatives like Source Generators that provide similar power with less risk. But understanding Emit remains valuable – it’s like knowing the fundamental laws of magic while using higher-level spells for daily work.
In my case, Project Genesis evolved beyond its original scope, teaching me crucial lessons about runtime code generation, performance optimization, and the delicate balance between power and maintainability.
Conclusion: The Magic Lives On
Twenty years later, Emit remains one of .NET’s most powerful and mysterious features. While modern development practices might steer us toward safer alternatives, understanding these fundamental building blocks of runtime code generation gives us deeper insight into the framework’s capabilities.
For those brave enough to venture into this realm, remember: with great power comes great responsibility – and the need for comprehensive unit tests. The dark magic of Emit might be seductive, but like all powerful tools, it demands respect and careful handling.

by Joche Ojeda | Jan 14, 2025 | C#, dotnet, MetaProgramming, Reflection
The Beginning of a Digital Sorcerer
Every master of the dark arts has an origin story, and mine begins in the ancient realm of MS-DOS 6.1. What started as simple experimentation with BAT files would eventually lead me down a path to discovering one of programming’s most powerful arts: metaprogramming.
I still remember the day my older brother Oscar introduced me to the mystical DIR command. He was three years ahead of me in school, already initiated into the computer classes that would begin in “tercer ciclo” (7th through 9th grade) in El Salvador. This simple command, capable of revealing the contents of directories, was my first spell in what would become a lifelong pursuit of programming magic.
My childhood hobbies – playing video games, guitar, and piano (a family tradition, given my father’s musical lineage) – faded into the background as I discovered the enchanting world of DOS commands. The discovery that files ending in .exe were executable spells and .com files were commands that accepted parameters opened up a new realm of possibilities.
Armed with EDIT.COM, a primitive but powerful text editor, I began experimenting with every file I could find. The real breakthrough came when I discovered AUTOEXEC.BAT, a mystical scroll that controlled the DOS startup ritual. This was my first encounter with automated script execution, though I didn’t know it at the time.
The Path of Many Languages
My journey through the programming arts led me through many schools of magic: Turbo Pascal, C++, Fox Pro (more of an application framework than a pure language), Delphi, VB6, VBA, VB.NET, and finally, my true calling: C#.
During my university years, I co-founded my first company with my cousin “Carlitos,” supported by my uncle Carlos Melgar, who had been like a father to me. While we had some coding experience, our ambition to create our own ERP system led us to expand our circle. This is where I met Abel, one of two programmers we recruited who were dating my cousins at the time. Abel, coming from a Delphi background, introduced me to a concept that would change my understanding of programming forever: reflection.
Understanding the Dark Arts of Metaprogramming
What Abel revealed to me that day was just the beginning of my journey into metaprogramming, a form of magic that allows code to examine and modify itself at runtime. In the .NET realm, this sorcery primarily manifests through reflection, a power that would have seemed impossible in my DOS days.
Let me share with you the secrets I’ve learned along this path:
The Power of Reflection: Your First Spell
// A basic spell of introspection
Type stringType = typeof(string);
MethodInfo[] methods = stringType.GetMethods();
foreach (var method in methods)
{
Console.WriteLine($"Discovered spell: {method.Name}");
}
This simple incantation allows your code to examine itself, revealing the methods hidden within any type. But this is just the beginning.
Conjuring Objects from the Void
As your powers grow, you’ll learn to create objects dynamically:
public class ObjectConjurer
{
public T SummonAndEnchant<T>(Dictionary<string, object> properties) where T : new()
{
T instance = new T();
Type type = typeof(T);
foreach (var property in properties)
{
PropertyInfo prop = type.GetProperty(property.Key);
if (prop != null && prop.CanWrite)
{
prop.SetValue(instance, property.Value);
}
}
return instance;
}
}
Advanced Rituals: Expression Trees
Expression<Func<int, bool>> ageCheck = age => age >= 18;
var parameter = Expression.Parameter(typeof(int), "age");
var constant = Expression.Constant(18, typeof(int));
var comparison = Expression.GreaterThanOrEqual(parameter, constant);
var lambda = Expression.Lambda<Func<int, bool>>(comparison, parameter);
The Price of Power: Security and Performance
Like any powerful magic, these arts come with risks and costs. Through my journey, I learned the importance of protective wards:
Guarding Against Dark Forces
// A protective ward for your reflective operations
[SecurityPermission(SecurityAction.Demand, ControlEvidence = true)]
public class SecretKeeper
{
private readonly string _arcaneSecret = "xyz";
public string RevealSecret(string authToken)
{
if (ValidateToken(authToken))
return _arcaneSecret;
throw new ForbiddenMagicException("Unauthorized attempt to access secrets");
}
}
The Cost of Power
| Ritual Type |
Energy Cost (ms) |
Mana Usage |
| Direct Cast |
1 |
Baseline |
| Reflection |
10-20 |
2x-3x |
| Cached Cast |
2-3 |
1.5x |
| Compiled |
1.2-1.5 |
1.2x |
To mitigate these costs, I learned to cache my spells:
public class SpellCache
{
private static readonly ConcurrentDictionary<string, MethodInfo> SpellBook
= new ConcurrentDictionary<string, MethodInfo>();
public static MethodInfo GetSpell(Type type, string spellName)
{
string key = $"{type.FullName}.{spellName}";
return SpellBook.GetOrAdd(key, _ => type.GetMethod(spellName));
}
}
Practical Applications in the Modern Age
Today, these dark arts power many of our most powerful frameworks:
- Entity Framework uses reflection for its magical object-relational mapping
- Dependency Injection containers use it to automatically wire up our applications
- Serialization libraries use it to transform objects into different forms
- Unit testing frameworks use it to create test doubles and verify behavior
Wisdom for the Aspiring Sorcerer
From my journey from DOS batch files to the heights of .NET metaprogramming, I’ve gathered these pieces of wisdom:
- Cache your incantations whenever possible
- Guard your secrets with proper wards
- Measure the cost of your rituals
- Use direct casting when available
- Document your dark arts thoroughly
Conclusion
Looking back at my journey from those first DOS commands to mastering the dark arts of metaprogramming, I’m reminded that every programmer’s path is unique. That young boy who first typed DIR in MS-DOS could never have imagined where that path would lead. Today, as I work with advanced concepts like reflection and metaprogramming in .NET, I’m reminded that our field is one of continuous learning and evolution.
The dark arts of metaprogramming may be powerful, but like any tool, their true value lies in knowing when and how to use them effectively. Remember, while the ability to make code write itself might seem like sorcery, the real magic lies in understanding the fundamentals and growing from them. Whether you’re starting with basic commands like I did or diving straight into advanced concepts, every step of the journey contributes to your growth as a developer.
And who knows? Maybe one day you’ll find yourself teaching these dark arts to the next generation of digital sorcerers.

by Joche Ojeda | Jan 12, 2025 | ADO.NET, C#, CPU, dotnet, ORM, XAF, XPO
Introduction
In the .NET ecosystem, “AnyCPU” is often considered a silver bullet for cross-platform deployment. However, this assumption can lead to significant problems when your application depends on native assemblies. In this post, I want to share a personal story that highlights how I discovered these limitations and how native dependencies affect the true portability of AnyCPU applications, especially for database access through ADO.NET and popular ORMs.
My Journey to Understanding AnyCPU’s Limitations
Every year, around Thanksgiving or Christmas, I visit my friend, brother, and business partner Javier. Two years ago, during one of these visits, I made a decision that would lead me to a pivotal realization about AnyCPU architecture.
At the time, I was tired of traveling with my bulky MSI GE72 Apache Pro-24 gaming laptop. According to MSI’s official specifications, it weighed 5.95 pounds—but that number didn’t include the hefty charger, which brought the total to around 12 pounds. Later, I upgraded to an MSI GF63 Thin, which was lighter at 4.10 pounds—but with the charger, it was still around 7.5 pounds. Lugging these laptops through airports felt like a workout.
Determined to travel lighter, I purchased a MacBook Air with the M2 chip. At just 2.7 pounds, including the charger, the MacBook Air felt like a breath of fresh air. The Apple Silicon chip was incredibly fast, and I immediately fell in love with the machine.
Having used a MacBook Pro with Bootcamp and Windows 7 years ago, I thought I could recreate that experience by running a Windows virtual machine on my MacBook Air to check projects and do some light development while traveling.
The Virtualization Experiment
As someone who loves virtualization, I eagerly set up a Windows virtual machine on my MacBook Air. I grabbed my trusty Windows x64 ISO, set up the virtual machine, and attempted to boot it—but it failed. I quickly realized the issue was related to CPU architecture. My x64 ISO wasn’t compatible with the ARM-based M2 chip.
Undeterred, I downloaded a Windows 11 ISO for ARM architecture and created the VM. Success! Windows was up and running, and I installed Visual Studio along with my essential development tools, including DevExpress XPO (my favorite ORM).
The Demo Disaster
The real test came during a trip to Dubai, where I was scheduled to give a live demo showcasing how quickly you can develop Line-of-Business (LOB) apps with XAF. Everything started smoothly until I tried to connect my XAF app to the database. Despite my best efforts, the connection failed.
In the middle of the demo, I switched to an in-memory data provider to salvage the presentation. After the demo, I dug into the issue and realized the root cause was related to the CPU architecture. The native database drivers I was using weren’t compatible with the ARM architecture.
A Familiar Problem
This situation reminded me of the transition from x86 to x64 years ago. Back then, I encountered similar issues where native drivers wouldn’t load unless they matched the process architecture.
The Native Dependency Challenge
Platform-Specific Loading Requirements
Native DLLs must exactly match the CPU architecture of your application:
- If your app runs as x86, it can only load x86 native DLLs.
- If running as x64, it requires x64 native DLLs.
- ARM requires ARM-specific binaries.
- ARM64 requires ARM64-specific binaries.
There is no flexibility—attempting to load a DLL compiled for a different architecture results in an immediate failure.
How Native Libraries are Loaded
When your application loads a native DLL, the operating system follows a specific search pattern:
- The application’s directory
- System directories (System32/SysWOW64)
- Directories listed in the PATH environment variable
Crucially, these native libraries must match the exact architecture of the running process.
// This seemingly simple code
[DllImport("native.dll")]
static extern void NativeMethod();
// Actually requires:
// - native.dll compiled for x86 when running as 32-bit
// - native.dll compiled for x64 when running as 64-bit
// - native.dll compiled for ARM64 when running on ARM64
The SQL Server Example
Let’s look at SQL Server connectivity, a common scenario where the AnyCPU illusion breaks down:
// Traditional ADO.NET connection
using (var connection = new SqlConnection(connectionString))
{
// This requires SQL Native Client
// Which must match the process architecture
await connection.OpenAsync();
}
Even though your application is compiled as AnyCPU, the SQL Native Client must match the process architecture. This becomes particularly problematic on newer architectures like ARM64, where native drivers may not be available.
Impact on ORMs
Entity Framework Core
Entity Framework Core, despite its modern design, still relies on database providers that may have native dependencies:
public class MyDbContext : DbContext
{
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
// This configuration depends on:
// 1. SQL Native Client
// 2. Microsoft.Data.SqlClient native components
optionsBuilder.UseSqlServer(connectionString);
}
}
DevExpress XPO
DevExpress XPO faces similar challenges:
// XPO configuration
string connectionString = MSSqlConnectionProvider.GetConnectionString("server", "database");
XpoDefault.DataLayer = XpoDefault.GetDataLayer(connectionString, AutoCreateOption.DatabaseAndSchema);
// The MSSqlConnectionProvider relies on the same native SQL Server components
Solutions and Best Practices
1. Architecture-Specific Deployment
Instead of relying on AnyCPU, consider creating architecture-specific builds:
<PropertyGroup>
<Platforms>x86;x64;arm64</Platforms>
<RuntimeIdentifiers>win-x86;win-x64;win-arm64</RuntimeIdentifiers>
</PropertyGroup>
2. Runtime Provider Selection
Implement smart provider selection based on the current architecture:
public static class DatabaseProviderFactory
{
public static IDbConnection GetProvider()
{
return RuntimeInformation.ProcessArchitecture switch
{
Architecture.X86 => new SqlConnection(), // x86 native provider
Architecture.X64 => new SqlConnection(), // x64 native provider
Architecture.Arm64 => new Microsoft.Data.SqlClient.SqlConnection(), // ARM64 support
_ => throw new PlatformNotSupportedException()
};
}
}
3. Managed Fallbacks
Implement fallback strategies when native providers aren’t available:
public class DatabaseConnection
{
public async Task<IDbConnection> CreateConnectionAsync()
{
try
{
var connection = new SqlConnection(_connectionString);
await connection.OpenAsync();
return connection;
}
catch (DllNotFoundException)
{
var managedConnection = new Microsoft.Data.SqlClient.SqlConnection(_connectionString);
await managedConnection.OpenAsync();
return managedConnection;
}
}
}
4. Deployment Considerations
- Include all necessary native dependencies for each target architecture.
- Use architecture-specific directories in your deployment.
- Consider self-contained deployment to include the correct runtime.
Real-World Implications
This experience taught me that while AnyCPU provides excellent flexibility for managed code, it has limitations when dealing with native dependencies. These limitations become more apparent in scenarios like cloud deployments, ARM64 devices, and live demos.
Conclusion
The transition to ARM architecture is accelerating, and understanding the nuances of AnyCPU and native dependencies is more important than ever. By planning for architecture-specific deployments and implementing fallback strategies, you can build more resilient applications that can thrive in a multi-architecture world.
by Joche Ojeda | Jan 9, 2025 | dotnet
While researching useful features in .NET 9 that could benefit XAF/XPO developers, I discovered something particularly interesting: Version 7 GUIDs (RFC 9562 specification). These new GUIDs offer a crucial feature – they’re sortable.
This discovery brought me back to an issue I encountered two years ago while working on the SyncFramework. We faced a peculiar problem where Deltas were correctly generated but processed in the wrong order in production environments. The occurrences seemed random, and no clear pattern emerged. Initially, I thought using Delta primary keys (GUIDs) to sort the Deltas would ensure they were processed in their generation order. However, this assumption proved incorrect. Through testing, I discovered that GUID generation couldn’t be trusted to be sequential. This issue affected multiple components of the SyncFramework. Whether generating GUIDs in C# or at the database level, there was no guarantee of sequential ordering. Different database engines could sort GUIDs differently. To address this, I implemented a sequence service as a solution.Enter .NET 9 with its Version 7 GUIDs (conforming to RFC 9562 specification). These new GUIDs are genuinely sequential, making them reliable for sorting operations.
To demonstrate this improvement, I created a test solution for XAF with a custom base object. The key implementation occurs in the OnSaving method:
protected override void OnSaving()
{
base.OnSaving();
if (!(Session is NestedUnitOfWork) && Session.IsNewObject(this) && oid.Equals(Guid.Empty))
{
oid = Guid.CreateVersion7();
}
}
Notice the use of CreateVersion7() instead of the traditional NewGuid(). For comparison, I also created another domain object using the traditional GUID generation:
protected override void OnSaving()
{
base.OnSaving();
if (!(Session is NestedUnitOfWork) && Session.IsNewObject(this) && oid.Equals(Guid.Empty))
{
oid = Guid.NewGuid();
}
}
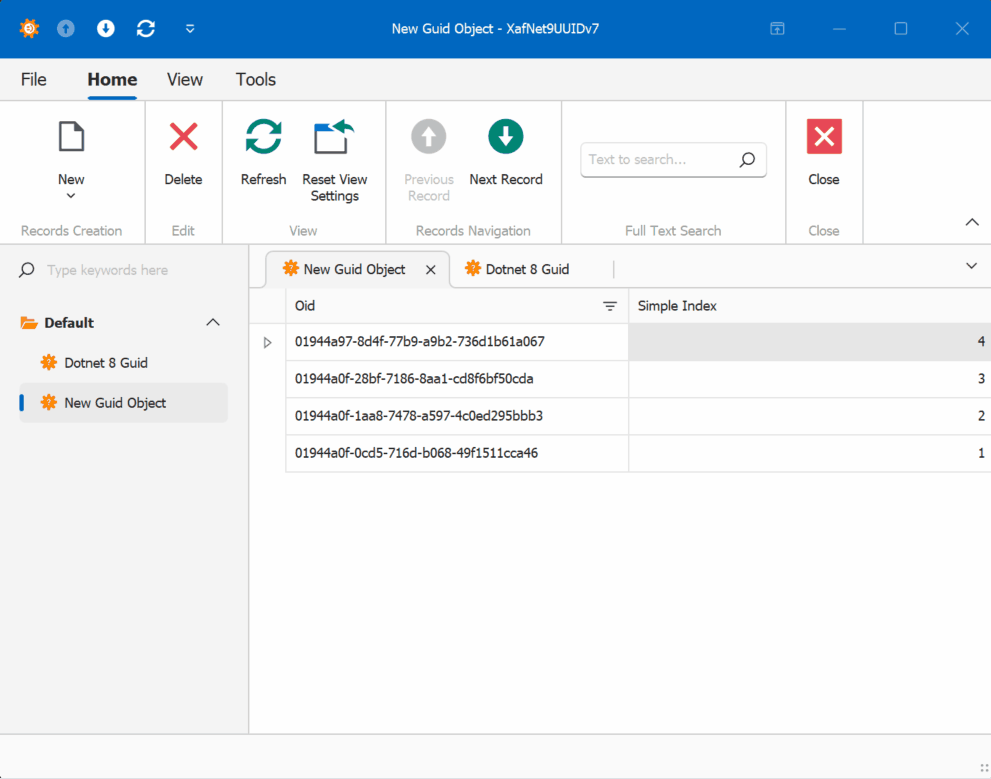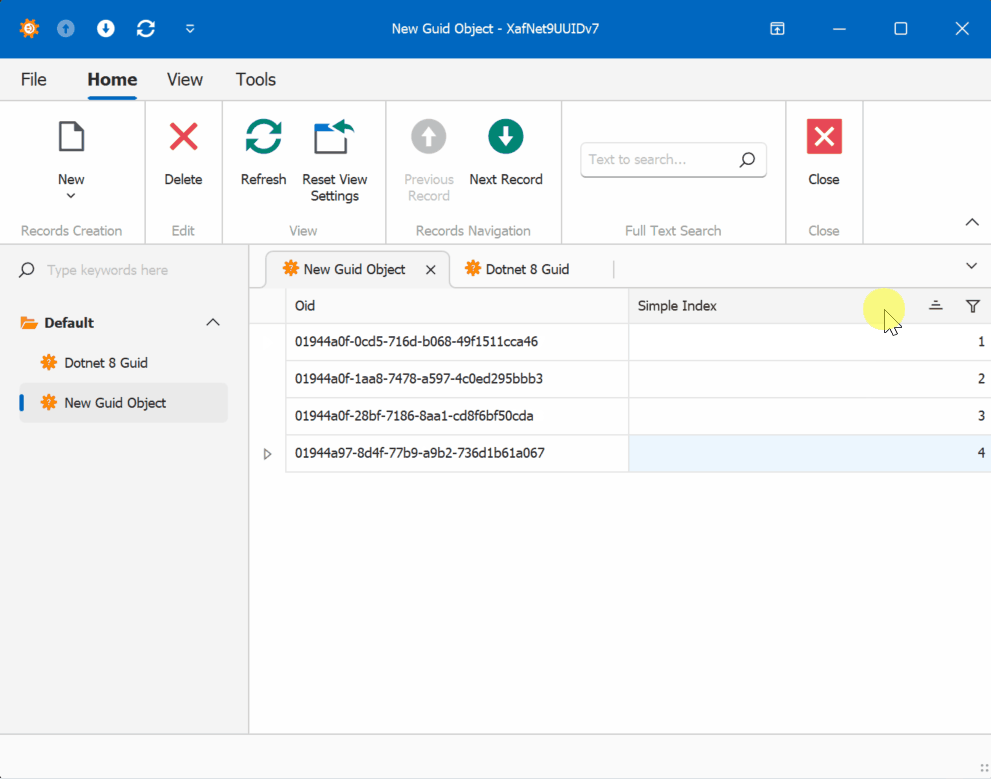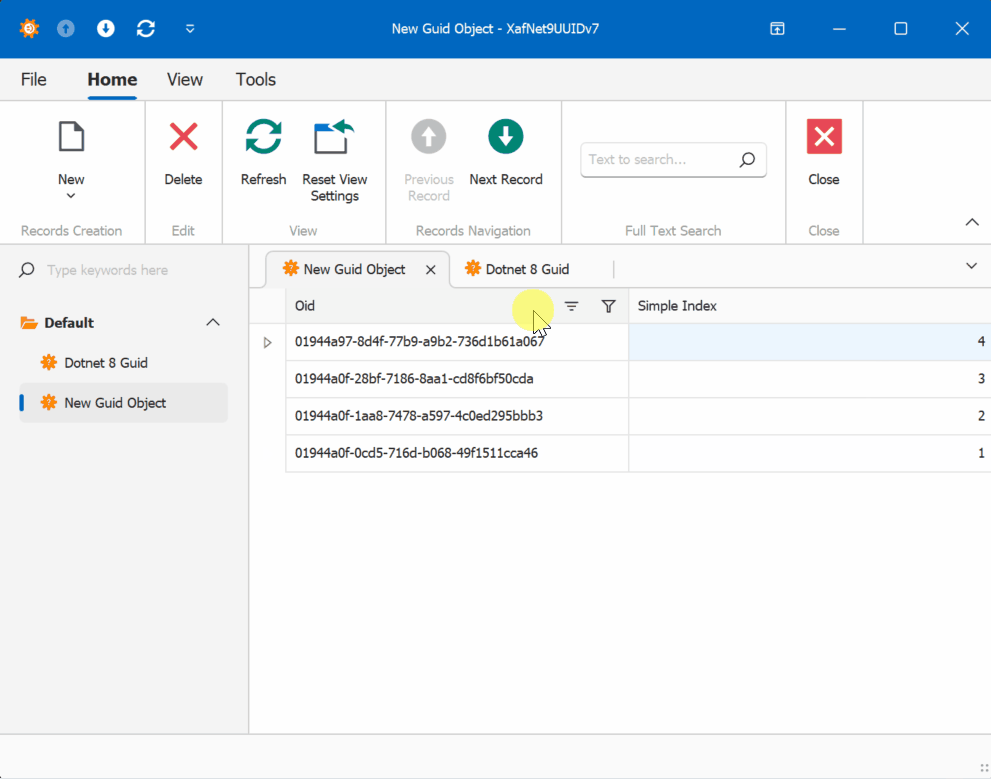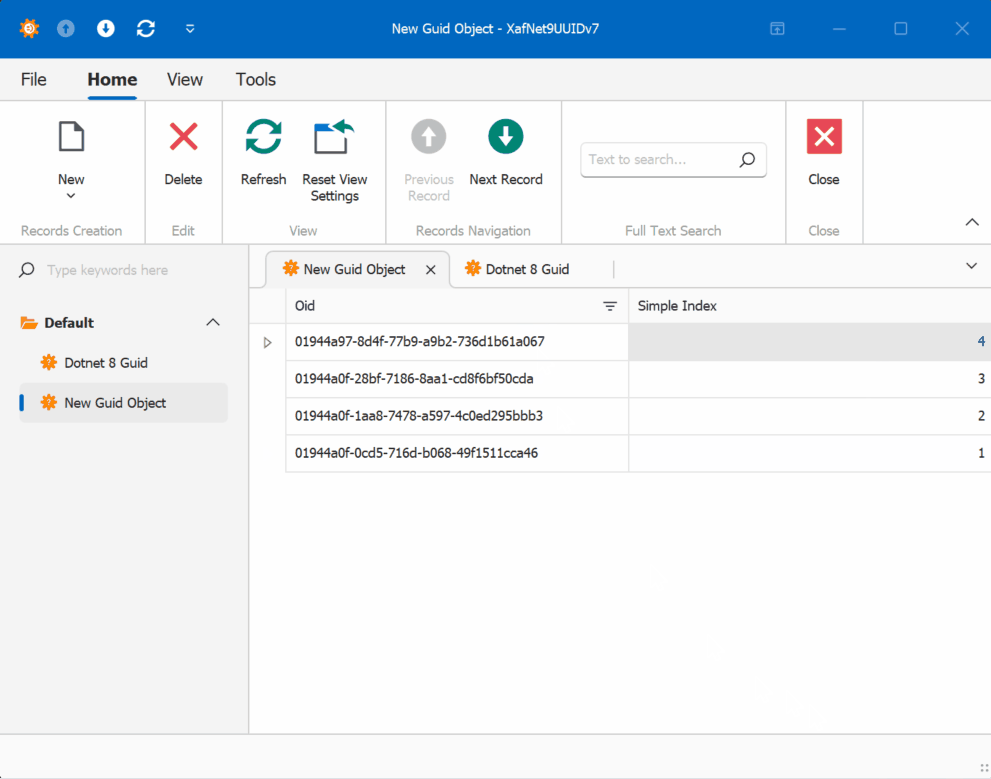
When creating multiple instances of the traditional GUID domain object, you’ll notice that the greater the time interval between instance creation, the less likely the GUIDs will maintain sequential ordering.
GUID Version 7
GUID Old Version
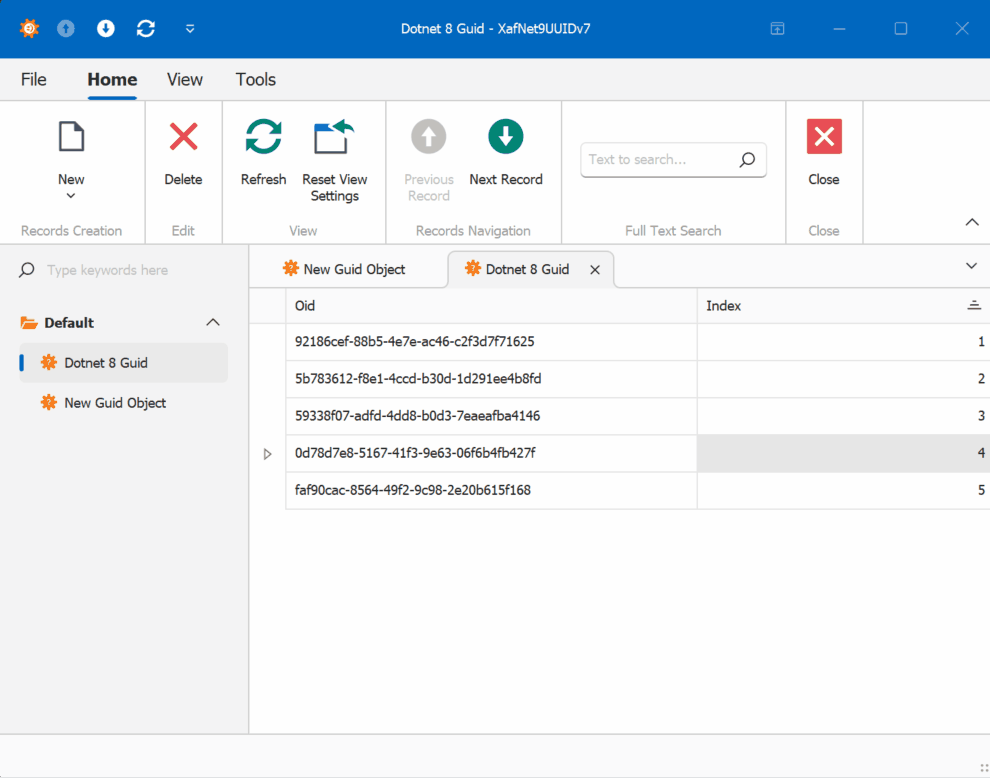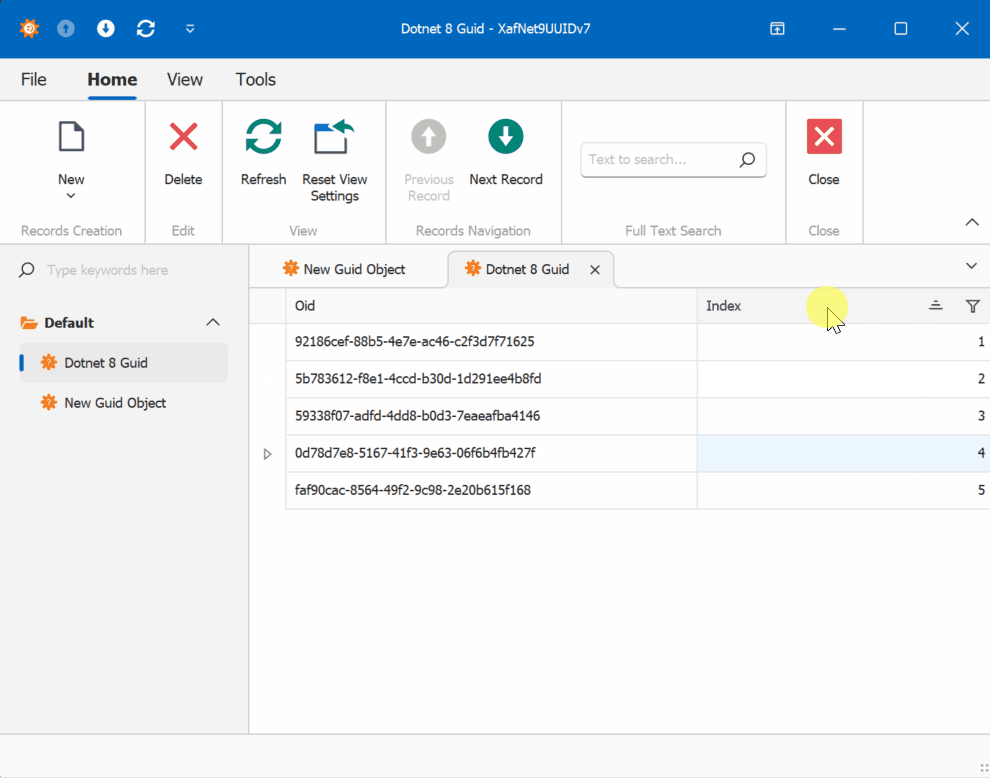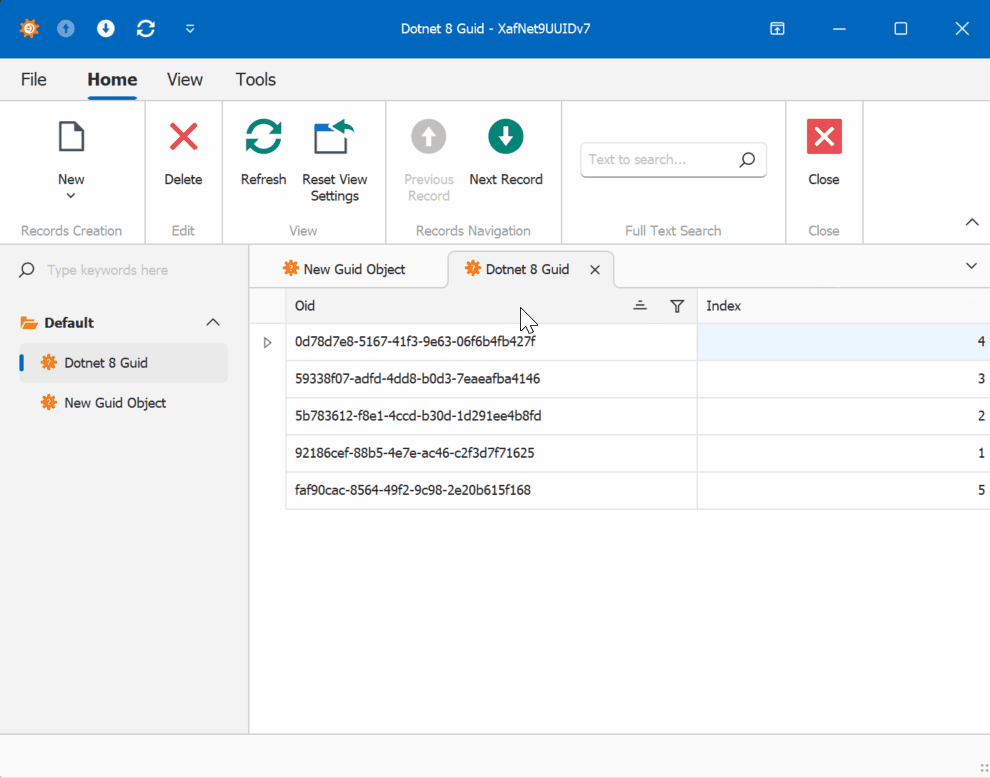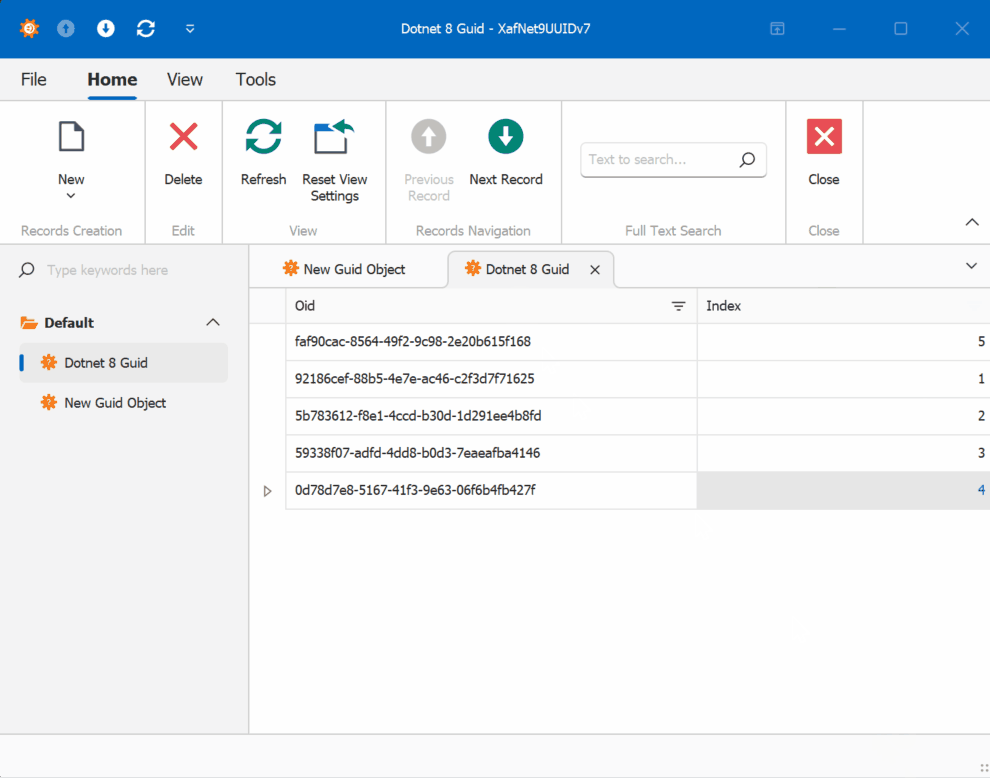
This new feature in .NET 9 could significantly simplify scenarios where sequential ordering is crucial, eliminating the need for additional sequence services in many cases. Here is the repo on GitHubHappy coding until next time!
Related article
On my GUID, common problems using GUID identifiers | Joche Ojeda

by Joche Ojeda | Jun 10, 2024 | C#, Data Synchronization, dotnet
The Ephemeral State of SOLID Code: Capturing the Perfect Snapshot
In the world of software development, the SOLID principles are often upheld as the gold standard for designing maintainable and scalable code. These principles — Single Responsibility, Open/Closed, Liskov Substitution, Interface Segregation, and Dependency Inversion — form the bedrock of robust object-oriented design. However, achieving a state where code fully adheres to these principles is a fleeting moment, much like capturing a perfect snapshot in time.
What Does It Mean for Code to Be in a SOLID State?
A SOLID state in source code is a condition where the code perfectly aligns with all five SOLID principles. This means:
- Single Responsibility Principle (SRP): Every class has one, and only one, reason to change.
- Open/Closed Principle (OCP): Software entities should be open for extension but closed for modification.
- Liskov Substitution Principle (LSP): Subtypes must be substitutable for their base types.
- Interface Segregation Principle (ISP): No client should be forced to depend on methods it does not use.
- Dependency Inversion Principle (DIP): Depend on abstractions, not concretions.
In this state, the codebase is a model of clarity, flexibility, and robustness. But this state is inherently transient.
The Moment of SOLID Perfection
The reality of software development is that code is in a constant state of flux. New features are added, bugs are fixed, and refactoring is a continuous process. During these periods of active development, maintaining perfect adherence to SOLID principles is challenging. The code may temporarily violate one or more principles as developers refactor or introduce new functionality.
The truly SOLID state can thus be seen as a snapshot — a moment frozen in time when the code perfectly adheres to all five principles. This moment typically occurs:
- Post-Refactoring: After a significant refactoring effort, where the focus has been on aligning the code with SOLID principles.
- Before Major Changes: Just before starting a new major feature or overhaul, the existing codebase might be in a perfect SOLID state.
- Code Reviews: Following a rigorous code review process, where adherence to SOLID principles is explicitly checked and enforced.
- Milestone Deliveries: Before delivering a major milestone or release, when the code is thoroughly tested and cleaned up.
The Nature of Active Development
Active development is a chaotic process. As new requirements emerge and priorities shift, developers might temporarily sacrifice adherence to SOLID principles for the sake of rapid progress or to meet deadlines. This is a natural part of the development cycle. The key is to recognize that while the code may deviate from these principles during active development, the goal is to continually steer it back towards a SOLID state.
The SOLID State as Nirvana
Achieving a perfect SOLID state can be likened to reaching nirvana — an ideal that is almost impossible to fully attain. Just as nirvana represents a state of ultimate peace and enlightenment, a perfectly SOLID codebase represents the pinnacle of software design. However, this state is incredibly difficult to reach and even harder to maintain. Therefore, it is more practical to view adherence to SOLID principles as a spectrum rather than a binary state.
Measuring SOLID Adherence
Instead of aiming for an elusive perfect state, it’s more pragmatic to measure adherence to SOLID principles using metrics. Tools and techniques can help quantify how well your code aligns with each principle, providing a percentage that reflects its current state. These metrics can include:
- Class Responsibility: Assessing the number of responsibilities each class has to evaluate adherence to SRP.
- Change Impact Analysis: Measuring the extent to which modifications to the code require changes in other parts of the system, reflecting adherence to OCP.
- Subtype Tests: Ensuring subclasses can replace their base classes without altering the correctness of the program, in line with LSP.
- Interface Utilization: Analyzing the usage of interfaces to ensure they are not overly broad, adhering to ISP.
- Dependency Metrics: Evaluating dependencies between high-level and low-level modules, supporting DIP.
By regularly measuring these metrics, developers can maintain a clear view of how their code is evolving in relation to SOLID principles. This approach allows for continuous improvement and helps teams prioritize refactoring efforts where they are most needed.
Embracing the Snapshot
Understanding that a perfectly SOLID state is a temporary snapshot can help developers maintain a healthy perspective. It’s crucial to strive for SOLID principles as a guiding star but also to accept that deviations are part of the journey. Regular refactoring sessions, continuous integration practices, and diligent code reviews are essential practices to frequently bring the code back to a SOLID state.
Conclusion
In conclusion, a SOLID state of source code is a valuable but ephemeral achievement, akin to reaching nirvana in the realm of software development. It represents a moment of perfection in the ongoing evolution of a software project. By recognizing this, developers can better manage their expectations and maintain a balance between striving for perfection and the practical realities of software development. Embrace the snapshot of SOLID perfection when it occurs, but also understand that the true measure of a healthy codebase is its ability to evolve while frequently realigning with these timeless principles, using metrics and percentages to guide the way.

by Joche Ojeda | May 15, 2024 | C#, dotnet, Linux, Ubuntu, WSL
Hello, dear readers! Today, we’re going to talk about something called the Windows Subsystem for Linux, or WSL for short. Now, don’t worry if you’re not a tech wizard – this guide is meant to be approachable for everyone!
What is WSL?
In simple terms, WSL is a feature in Windows that allows you to use Linux right within your Windows system. Think of it as having a little bit of Linux magic right in your Windows computer!
Why Should I Care?
Well, WSL is like having a Swiss Army knife on your computer. It can make certain tasks easier and faster, and it can even let you use tools that were previously only available on Linux.
Is It Hard to Use?
Not at all! If you’ve ever used the Command Prompt on your Windows computer, then you’re already halfway there. And even if you haven’t, there are plenty of easy-to-follow guides out there to help you get started.
Do I Need to Be a Computer Expert to Use It?
Absolutely not! While WSL is a powerful tool that many developers love to use, it’s also quite user-friendly. With a bit of curiosity and a dash of patience, anyone can start exploring the world of WSL.
As a DotNet developer, you might be wondering why there’s so much buzz around the Windows Subsystem for Linux (WSL). Let’s dive into the reasons why WSL could be a game-changer for you.
- Seamless Integration: WSL provides a full-fledged Linux environment right within your Windows system. This means you can run Linux commands and applications without needing a separate machine or dual-boot setup.
- Development Environment Consistency: With WSL, you can maintain consistency between your development and production environments, especially if your applications are deployed on Linux servers. This can significantly reduce the “it works on my machine” syndrome.
- Access to Linux-Only Tools: Some tools and utilities are only available or work better on Linux. WSL brings these tools to your Windows desktop, expanding your toolkit without additional overhead.
- Improved Performance: WSL 2, the latest version, runs a real Linux kernel inside a lightweight virtual machine (VM), which leads to faster file system performance and complete system call compatibility.
- Docker Support: WSL 2 provides full Docker support without requiring additional layers for translation between Windows and Linux, resulting in a more efficient and seamless Docker experience.
In conclusion, WSL is not just a fancy tool; it’s a powerful ally that can enhance your productivity and capabilities as a DotNet developer.