by Joche Ojeda | May 30, 2023 | Uncategorized
Let’s do a quick overview of the main features of XPO before we dive into details.
XPO (eXpress Persistent Objects) is a full-featured Object-Relational Mapping (ORM) framework developed by DevExpress. It is used to provide a mapping between the relational database tables and the objects used in a .NET application.
XPO allows developers to interact with a database in a more natural, object-oriented manner and eliminates the need to write complex SQL statements. It provides a high-level API for working with databases, automating common tasks such as connecting to a database, querying data, and committing changes.
With XPO, developers can focus on the business logic of the application rather than worrying about the low-level details of working with databases.
Throughout the book, we will explore each feature of XPO in depth, providing a comprehensive understanding of its capabilities. However, here are some of the most notable features of XPO that we will highlight:
- Object-Relational Mapping (ORM): XPO provides a mapping between the relational database tables and the objects used in a .NET application. This makes it easier for developers to interact with databases in a more natural, object-oriented manner.
- High-Level API: XPO provides a high-level API for working with databases, automating common tasks such as connecting to a database, querying data, and committing changes.
- Data Types Mapping: XPO automatically maps .NET data types to their corresponding SQL data types and vice versa, eliminating the need for manual data type conversion.
- LINQ Support: XPO includes built-in LINQ (Language Integrated Query) support, making it easier to write complex, fine-tuned queries.
- Customizable SQL Generation: XPO allows developers to customize the SQL generated by the framework, providing greater control over the database operations.
- Lazy Loading: XPO supports lazy loading, meaning that related objects can be loaded on demand, reducing the amount of data that needs to be loaded at once and improving performance.
- Change Tracking: XPO tracks changes made to objects and automatically updates the database as needed, eliminating the need to write manual update statements.
- Validation: XPO provides built-in support for validating objects, making it easier to enforce business rules and ensure data integrity.
- Caching: XPO provides caching capabilities, allowing frequently used data to be cached and reducing the number of database queries required.
- Support for Multiple Databases: XPO supports a wide range of relational databases, including SQL Server, Oracle, MySQL, PostgreSQL, and more.
Enhancing XPO with Metadata : Annotations
In C#, annotations are attributes that can be applied to classes, properties, methods, and other program elements to add metadata or configuration information.
In XPO, annotations are used extensively to configure the behavior of persistent classes.
XPO provides a number of built-in annotations that can be used to customize the behavior of persistent classes, making it easier to work with relational data using object-oriented programming techniques.
Some of the most commonly used annotations include:
- Persistent: Specifies the name of the database table that the persistent class is mapped to.
- PersistentAlias: Specifies the name of the database column that a property is mapped to.
- Size: Specifies the maximum size of a database column that a property is mapped to.
- Key: Marks a property as a key property for the persistent class.
- NonPersistent: Marks a property as not persistent, meaning it is not mapped to a database column.
- Association: Specifies the name of a database column that contains a foreign key for a one-to-many or many-to-many relationship.
In addition to the built-in annotations, XPO also provides a mechanism for defining custom annotations. You can define a custom annotation by defining a class that is inherited from the Attribute class.
Annotations can be applied using a variety of mechanisms, including directly in code, via configuration files, or through attributes on other annotations.
We will witness the practical implementation of annotations throughout the book, including our own custom annotations. However, we wanted to introduce them early on as they play a crucial role in the efficient mapping and management of data within XPO.
Now that we have refreshed our understanding of XPO’s main goal and features, let’s delve into the “O”, the “R”, and the “M” of an ORM.
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
SOLID design pattern and XPO
What is an O.R.M (Object-Relational Mapping)
ADO The origin of data access in .NET
Relational database systems: the holy grail of data

by Joche Ojeda | May 29, 2023 | Uncategorized
SOLID is an acronym that stands for five fundamental principles of object-oriented programming and design. These principles were first introduced by Robert C. Martin (also known as Uncle Bob) and have since become a cornerstone of software development best practices. Each letter in SOLID represents a principle that, when applied correctly, leads to more maintainable and modular code.
Let’s dive into each of the SOLID principles and understand how they contribute to building high-quality software systems:
Single Responsibility Principle (SRP):
The SRP states that a class should have only one reason to change. In other words, a class should have a single responsibility or a single job. This principle encourages developers to break down complex systems into smaller, cohesive modules. By ensuring that each class has a focused responsibility, it becomes easier to understand, test, and modify the code without affecting other parts of the system.
Open-Closed Principle (OCP):
The OCP promotes the idea that software entities (classes, modules, functions, etc.) should be open for extension but closed for modification. This principle emphasizes the importance of designing systems that can be easily extended with new functionality without modifying existing code. By relying on abstractions, interfaces, and inheritance, developers can add new features by writing new code rather than changing the existing one. This approach reduces the risk of introducing bugs or unintended side effects.
Liskov Substitution Principle (LSP):
The LSP states that objects of a superclass should be replaceable with objects of its subclasses without affecting the correctness of the program. In simpler terms, if a class is a subtype of another class, it should be able to be used interchangeably with its parent class without causing any issues. This principle ensures that inheritance hierarchies are well-designed, avoiding situations where subclass behavior contradicts or breaks the functionality defined by the superclass. Adhering to the LSP leads to more flexible and reusable code.
Interface Segregation Principle (ISP):
The ISP advises developers to design interfaces that are specific to the needs of the clients that use them. It suggests that clients should not be forced to depend on interfaces they don’t use. By creating small and focused interfaces, rather than large and monolithic ones, the ISP enables clients to be decoupled from unnecessary dependencies. This principle enhances modularity, testability, and maintainability, as changes to one part of the system are less likely to impact other parts.
Dependency Inversion Principle (DIP):
The DIP encourages high-level modules to depend on abstractions rather than concrete implementations. It states that high-level modules should not depend on low-level modules; both should depend on abstractions. This principle promotes loose coupling between components, making it easier to substitute or modify dependencies without affecting the overall system. By relying on interfaces or abstract classes, the DIP facilitates extensibility, testability, and the ability to adapt to changing requirements.
By applying the SOLID principles, software engineers can create codebases that are modular, flexible, and easy to maintain. These principles provide a roadmap for designing systems that are resilient to change, promote code reusability, and improve collaboration among development teams. SOLID principles are not strict rules but rather guidelines that help developers make informed design decisions and create high-quality software systems.
It’s worth mentioning that the SOLID principles should not be applied blindly in all situations. Context matters, and there may be scenarios where strict adherence to one principle might not be the best approach. However, understanding and incorporating these principles into the software design process can significantly improve the overall quality of the codebase.
SOLID and XPO
XPO is designed with SOLID design principles in mind. Here’s how XPO applies each of the SOLID principles:
Single Responsibility Principle (SRP)
XPO uses separate classes for each major concern such as mapping, persistence, connection providers, and data access. Each class has a clearly defined purpose and responsibility.
Open-Closed Principle (OCP)
XPO is extensible and customizable, allowing you to create your own classes and derive them from the XPO base classes. XPO also provides a range of extension points and hooks to allow for customization and extension without modifying the core XPO code.
Liskov Substitution Principle (LSP)
XPO follows this principle by providing a uniform API that works with all persistent objects, regardless of their concrete implementation. This allows you to write code that works with any persistent object, without having to worry about the specific implementation details.
Interface Segregation Principle (ISP)
XPO provides a number of interfaces that define specific aspects of its behavior, allowing clients to use only the interfaces they need. This reduces the coupling between the clients and the XPO library.
Dependency Inversion Principle (DIP)
XPO was developed prior to the widespread popularity of Dependency Injection (DI) patterns and frameworks.
As a result, XPO does not incorporate DI as a built-in feature. However, this does not mean that XPO cannot be used in conjunction with DI. While XPO itself does not provide direct support for DI, you can still integrate it with popular DI containers or frameworks, such as the .NET Core DI container or any other one.
By integrating XPO with a DI container, you can leverage the benefits of DI principles in your application while utilizing XPO’s capabilities for database access and mapping. The DI container can handle the creation and management of XPO-related objects, facilitating loose coupling, improved modularity, and simplified testing.
A clear example is the XPO Extensions for ASP.NET Core DI:
using DevExpress.Xpo.DB;
Using Microsoft.Extensions.DependencyInjection; // ...
var builder = WebApplication.CreateBuilder(args); builder.Services.AddXpoDefaultUnitOfWork(true, options => options.UseConnectionString(builder.Configuration.GetConnectionString("MSSqlServer")) .UseAutoCreationOption(AutoCreateOption.DatabaseAndSchema) .UseEntityTypes(new Type[] { typeof(User) }));
More information about XPO and DI here: https://docs.devexpress.com/XPO/403009/connect-to-a-data-store/xpo-extensions-for-aspnet-core-di
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
What is an O.R.M (Object-Relational Mapping)
ADO The origin of data access in .NET
Relational database systems: the holy grail of data

by Joche Ojeda | May 26, 2023 | ADO, ADO.NET, ORM
ORM is a technique for converting data between incompatible type systems using object-oriented programming languages. In the context of database management, an ORM provides a way to interact with a database using objects and methods, rather than writing raw SQL queries. This allows for a higher level of abstraction, reducing the amount of repetitive and error-prone code that needs to be written, and making it easier to maintain the application.
ORM and RDBMS
Object-Relational Mapping (ORM) tools and RDBMS have different approaches to querying data.
RDBMS uses SQL which is a low-level, language-agnostic query language that is used to communicate with relational databases. When using SQL, developers write raw SQL statements that are executed directly against the database. The results of the query are then returned in the form of a table or set of tables, which must be manually mapped to objects in code.
On the other hand, an ORM tool abstracts the underlying SQL code, allowing developers to query data using an object-oriented syntax that is similar to the programming language used in the application.
The ORM tool automatically generates the necessary SQL statements and executes them against the database, and then maps the resulting data to objects in code.
One of the main advantages of using an ORM tool is that it eliminates the need for manual data mapping, making it easier for developers to write data-access code and reducing the chances of errors. Additionally, because ORM tools use a higher-level syntax, they can also be more intuitive and easier to use than raw SQL.
However, ORM tools can also introduce performance overhead and complexity, as they must manage the mapping between the database and objects in code. In some cases, raw SQL may still be necessary to achieve the desired performance or to perform complex data manipulation that is not supported by the ORM tool.
As a simple example we will use the database table “customer”. It has four columns:
- id: A unique identifier for each customer, usually an auto-incrementing integer.
- name: The name of the customer, represented as a string.
- email: The email address of the customer, represented as a string.
- address: The address of the customer, represented as a string.
Each row in the table represents a single customer, and each column represents a piece of information about that customer. The table is used to store the data for the customer objects created in the code. The ORM maps the table to a class, allowing you to interact with the data using objects and methods.
Here is an example of how an ORM can map a database table named “customer” to a class representation in C#:
class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Email { get; set; }
public string Address { get; set; }
}
// The ORM maps the customer table in the database to the Customer class.
// The columns of the table become properties of the class, and each row in the table becomes an instance of the class.
In this example, the ORM abstracts away the underlying database and provides a high-level, object-oriented interface for working with the data.
The main advantage of using an ORM (Object-Relational Mapping) instead of using the direct results from the database in C# is increased abstraction and convenience. This provides several benefits:
- Improved readability and maintainability: Code written using an ORM is easier to understand and maintain, as it uses a higher-level, object-oriented interface, rather than raw SQL.
- Reduced code duplication: With an ORM, you can encapsulate database-related logic in reusable classes and methods, reducing the amount of repetitive code that needs to be written.
- Increased safety: An ORM can help prevent SQL injection attacks by automatically escaping user input, ensuring that data is safely inserted into the database.
- Increased flexibility: An ORM provides a layer of abstraction between the application code and the database, allowing you to switch between different database systems without changing the application code.
Direct database access
var connection = new SqlConnection("connection string");
connection. Open();
var command = new SqlCommand("SELECT * FROM customers", connection);
var reader = command.ExecuteReader();
List < Customer > customers = new List < Customer > ();
while (reader. Read()) {
var customer = new Customer {
Id = reader.GetInt32(0),
Name = reader.GetString(1),
Email = reader.GetString(2),
Address = reader.GetString(3)
};
customers. Add(customer);
}
reader.Close();
connection. Close();
ORM access
var customers = ORM.Query<Customer>().ToList();
As you can see, using an ORM simplifies the code and makes it more readable, while also providing additional safety and flexibility benefits.
Different types of O.R.M
Micro O.R.M
A micro ORM is a type of Object-Relational Mapping (ORM) library that is designed to be lightweight and simple, offering a minimalistic and easy-to-use interface for interacting with a relational database.
Micro ORMs are typically faster and require less configuration and setup than full-featured ORMs, but also have fewer features and less advanced capabilities.
Micro ORMs provide a higher-level, object-oriented interface for working with databases, allowing you to interact with the data using classes, properties, and methods, rather than writing raw SQL queries as well but they typically offer a smaller, more focused set of features than full-featured ORMs, including support for basic CRUD (Create, Read, Update, Delete) operations, and often provide basic querying and data mapping capabilities.
Micro ORMs are often used in small projects or in environments where performance is critical. They are also commonly used in microservices and other architectures that prioritize simplicity, scalability, and ease of deployment.
Full-fledged Object-Relational Mapping (ORM)
A full-fledged Object-Relational Mapping (ORM) is a software library that provides a convenient and efficient way of working with relational databases.
A full-fledged ORM typically has the following characteristics:
- Object Mapping: The ORM maps database tables to object-oriented classes, allowing developers to interact with the database using objects instead of tables.
- Query Generation: The ORM generates SQL statements based on the object-oriented query syntax, reducing the need for developers to write and manage raw SQL.
- Data Validation: The ORM provides built-in data validation and type checking, reducing the risk of incorrect data being written to the database.
- Caching: The ORM may provide caching of data to improve performance, reducing the number of databases round trips.
- Transactions: The ORM supports transactions, making it easier to ensure that database operations are atomic and consistent.
- Database Independence: The ORM is typically designed to be database agnostic, allowing developers to switch between different database platforms without changing the application code.
- Lazy Loading: The ORM supports lazy loading, which can improve performance by loading related objects only when they are needed.
- Performance: A comprehensive ORM is crafted to deliver satisfactory performance, and we can customize each aspect of the ORM to enhance its performance. However, it is important to note that a solid understanding of how the ORM operates is necessary to make these customizations effective.
One of the disadvantages of using an Object-Relational Mapping (ORM) tool is that you may not be able to create specialized, fine-tuned queries with the same level of precision as you can with raw SQL. This is because ORMs typically abstract the underlying database and expose a higher-level, more object-oriented API for querying data.
For example, it may not be possible to use specific SQL constructs, such as subqueries or window functions, in your ORM queries. Additionally, some ORMs may not provide a way to optimize query performance, such as by specifying index hints or controlling the execution plan.
As a result, developers who need to write specialized or fine-tuned queries may find it easier and more efficient to write raw SQL statements. However, this comes at the cost of having to manually manage the mapping between the database and the application, which is one of the main benefits of using an ORM in the first place.
ORM and Querying data
Before the existence of LINQ, Object-Relational Mapping (ORM) tools used a proprietary query language to query data. This meant that each ORM had to invent its own criteria or query language, and developers had to learn the specific syntax of each ORM in order to write queries.
For example, in XPO, developers used the Criteria API to write queries. The Criteria API allowed developers to write queries in a type-safe and intuitive manner, but the syntax was specific to XPO and not easily transferable to other ORMs.
Similarly, in NHibernate, developers used the Hibernate Query Language (HQL) to write queries. Like the Criteria API in XPO, HQL was a proprietary query language specific to NHibernate, and developers had to learn the syntax in order to write queries.
This lack of a standardized query language was one of the main limitations of ORMs before the introduction of LINQ. LINQ provided a common, language-agnostic query language that could be used with a variety of data sources, including relational databases. This made it easier for developers to write data-access code, as they only had to learn one query language, regardless of the ORM or data source being used.
The introduction of LINQ, a new era for O.R.M in dot net
Language Integrated Query (LINQ) is a Microsoft .NET Framework component that was introduced in .NET Framework 3.5. It is a set of language and library features that enables developers to write querying and manipulation operations over data in a more intuitive and readable way.
LINQ was created to address the need for a more unified and flexible approach to querying and manipulating data in .NET applications. Prior to LINQ, developers had to write separate code to access and manipulate data in different data sources, such as databases, XML documents, and in-memory collections. This resulted in a fragmented and difficult-to-maintain codebase, with different syntax and approaches for different data sources.
With LINQ, developers can now write a single querying language that works with a wide range of data sources, including databases, XML, in-memory collections, and more.
In addition, LINQ also provides a number of other benefits, such as improved performance, better type safety, and integrated support for data processing operations, such as filtering, grouping, and aggregating.
using (var context = new DbContext())
{
var selectedCustomers = context.Customers
.Where(c => c.Address.Contains("San Salvador"))
.Select(c => new
{
c.Id,
c.Name,
c.Email,
c.Address
})
.ToList();
foreach(var customer in selectedCustomers)
foreach(var customer in selectedCustomers)
{
Console.WriteLine($"Id: {customer.Id}, Name: {customer.Name}, Email: {customer.Email}, Address: {customer. Address}");
}
}
And that’s all for this post, until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
ADO The origin of data access in .NET
Relational database systems: the holy grail of data

by Joche Ojeda | May 24, 2023 | XPO
.NET communicates with a database using ADO.NET, which provides a set of classes and interfaces for accessing and manipulating data stored in a database.
ADO.NET supports various database systems, including relational databases and XML databases.
ADO.NET uses the following protocols to communicate with a database:
1. OLE DB (Object Linking and Embedding, Database) – This is a low-level, component-based API that provides a generic interface for accessing various types of data sources, including relational databases, spreadsheet data, and more.
2. ODBC (Open Database Connectivity) – This is a widely used API for accessing relational databases. It provides a standardized interface for accessing data, regardless of the underlying database management system.
3. ADO.NET Provider – This is a high-level, .NET-based API for accessing data stored in a specific database management system, such as Microsoft SQL Server, Oracle, or MySQL.
The choice of protocol used by ADO.NET to communicate with a database depends on the specific requirements of the application and the database management system being used.
The ADO.NET provider approach is the most common and provides a flexible and scalable solution for accessing and manipulating data stored in a database, supporting a wide range of database systems and communication protocols.
ADO.NET Main Components
The main classes in ADO.NET include:
1. Connection – Represents a connection to a database, providing methods for opening and closing a connection and for executing commands against the database.
2. Command – Represents a database command, such as a SELECT, INSERT, UPDATE, or DELETE statement, and provides methods for executing the command and for retrieving the results of the command.
3. DataReader – Provides a forward-only, read-only view of the results of a command. The DataReader is optimized for retrieving large amounts of data from a database, as it retrieves data in a streaming manner, rather than retrieving all data into memory at once.
4. DataAdapter – Represents a set of data commands and a database connection that are used to fill a DataSet and to resolve changes made to the data back to the database. The DataAdapter is often used in combination with a DataSet to provide a flexible and scalable way to access and manipulate data stored in a database.
5. DataSet – Represents an in-memory cache of data, providing a disconnected view of data that can be used to work with data independently of a database connection. The DataSet provides a rich set of features for manipulating and querying data, including support for relationships between tables, constraints, and transactions.
6. Parameter – Represents a parameter for a database command, providing a way to specify input values for a command, such as the values for parameters in a stored procedure.
These are the main classes in ADO.NET, and they provide a comprehensive and flexible set of tools for accessing and manipulating data stored in a database.
Design problems in ADO.NET 1
ADO.NET 1 refers to the first version of ADO.NET, which was introduced in .NET Framework 1.0, released in 2002. In this version of ADO.NET, data access was performed using direct methods and properties of the various ADO.NET classes, such as SqlConnection and SqlCommand for SQL Server.
The main design problem for ADO.NET 1 is that it requires developers to write database-specific code for each database management system that they wanted to access.
ADO.NET 2 and the DbProviderFactory
With the introduction of .NET Framework 2.0 in 2005, the ADO.NET DbProviderFactory was introduced.
The DbProviderFactory abstract class provides a set of methods for creating database-specific implementations of various ADO.NET classes, such as DbConnection, DbCommand, and DbDataAdapter, and makes it easier for developers to write database-agnostic code.
ADO.NET DbProviderFactory is a factory pattern that provides a standard way to create instances of database-specific classes, such as connection and command classes, in ADO.NET.
The DbProviderFactory is used by the ADO.NET data providers, such as the SqlClient data provider for SQL Server, the OleDb data provider for OLE DB data sources, and the ODBC data provider for ODBC data sources, to provide a common way to create instances of the classes that they implement. This makes it easier for developers to switch between different data providers and to write database-agnostic code that can work with different databases without modification.
The introduction of DbProviderFactory in ADO.NET was an exceptional milestone that revolutionized database access in .NET. By providing a standardized interface for creating database-specific connection objects, DbProviderFactory enhanced the flexibility and portability of data access code. Its ingenious design allowed developers to write data access logic without being tightly coupled to a specific database provider, thereby promoting code reusability and adaptability. This breakthrough was the steppingstone to the emergence and widespread adoption of Object-Relational Mapping Systems (ORMs).
ORMs leveraged DbProviderFactory’s capabilities to abstract the complexities of database interactions and map database entities to object-oriented representations seamlessly. As a result, developers could focus more on business logic and application development rather than dealing with low-level data access intricacies.
The symbiotic relationship between DbProviderFactory and ORMs continues to shape modern software development, empowering developers with powerful tools to efficiently manage and manipulate data in a database-agnostic manner.
Until next time ))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.
Related Articles
Relational database systems: the holy grail of data

by Joche Ojeda | May 23, 2023 | XPO
RDBMS stands for Relational Database Management System. It is a type of database management system that is based on the relational model, which organizes data into tables with rows and columns, and uses relationships between tables to link data together.
In an RDBMS, data is stored in tables, with each table representing a specific type of data (such as customers, orders, or products). Each table has columns that represent the attributes of the data, and rows that represent individual instances of the data. Relationships between tables can be established using keys, allowing data from multiple tables to be linked and retrieved in a single query.
RDBMSs provide a variety of features and tools for managing, querying, and manipulating data stored in the database, including data validation, constraint enforcement, transaction management, backup and recovery, reporting and analysis capabilities. They are widely used in enterprise applications, web applications, and other systems that require the management of large amounts of structured data.
Examples of popular RDBMSs include Oracle, Microsoft SQL Server, MySQL, and PostgreSQL.
A Relational Database Management System (RDBMS) uses Data Manipulation Language (DML) and Data Definition Language (DDL) queries to interact with the data stored in the database. The specific syntax of the queries will vary depending on the database system being used.
DML queries are used to retrieve, insert, update, and delete data in the database. The most used DML queries are:
- SELECT: Retrieves data from one or more tables in the database.
- INSERT: Adds a new row of data to a table in the database.
- UPDATE: Modifies existing data in a table in the database.
- DELETE: Deletes data from a table in the database.
DDL queries are used to create, modify, and delete database structures, such as tables, indexes, and constraints. The most used DDL queries are:
- CREATE: Creates a new database object, such as a table or index.
- ALTER: Modifies the structure of an existing database object.
- DROP: Deletes a database object.
For example, the following is a DDL query to create a table named customers:
CREATE TABLE customers (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255),
email VARCHAR(255),
address VARCHAR(255)
);
And the following is a DML query to insert a new customer into the customers table:
INSERT INTO customers (name, email, address)
VALUES ('John Doe', 'johndoe@example.com', '123 Main St');
In the next article we will be talking about the origin of data access in net framework a.k.a ADO.NET
See you then )))
We are excited to announce that we are currently in the process of writing a comprehensive book about DevExpress XPO. As we work on this project, we believe it is essential to involve our readers and gather their valuable feedback. Therefore, we have decided to share articles from the book as we complete them, giving you an opportunity to provide input and suggestions that we can consider for inclusion in the final release. Keep in mind that the content presented is subject to change. We greatly appreciate your participation in this collaborative effort.

by Joche Ojeda | May 17, 2023 | AlchemyDotNet, C#
Alright, it’s time to start writing some code, but first, let’s decide how this project will be organized.
So far, the repository structure that I’ve found most appealing is the one I used for the SyncFramework (https://github.com/egarim/SyncFramework). Here is a representation with bullet points:
- Repo Folder: This is the parent folder that will contain all the code from our project. o Git Files: These are Ignore and attributes files.
- Clean.bat: This is a batch file that deletes all child BIN and OBJ folders to ensure our repository does not contain binary files (sometimes the ‘clean’ command from Visual Studio does not clear the outputs completely).
- CHANGES.MD: This is a Github markdown file that contains the history of changes in the code.
- README.MD: This is the landing page of the current repository where we can write some basic instructions and other important information about the project.
- src (folder): This is where the actual code resides.
Before I conclude this post, I want to discuss versioning. The main idea here is this: the project AlchemyDotNet.Core will start at version 1.0.0, and the version will change when there is a fix or an update to the core specification. We will only move to a new version like 2.0.0 when the specification introduces breaking changes. This means that we will be on version 1 for a very long time.
Link to the repo
https://github.com/egarim/Alchemy.Net
Previous posts
Alchemy Framework: 1 – Creating a framework for import data

by Joche Ojeda | May 15, 2023 | Uncategorized
Last Friday, I received a message from a dear friend and colleague, Pedro Hernandez. He asked me if I had the latest compiled version of the XPO import framework we created in our office. As it turned out, I did not have it readily available and had to search extensively for it.
While conducting this search across my computers, repositories, and virtual machines, I was inspired to create another import framework — yes, another piece of code to maintain.
Most of the time, my research projects begin in the same manner, typically after a conversation with my close friend Jose Javier Columbie. As always, he would say something like this: “Jose, do you think this can be possible? Why don’t you give it a try? If we succeed, that will be el batazo (like hitting a home run).”
In this specific case, that conversation didn’t happen. However, I could hear his words echoing in my mind.
Furthermore, I want this project to be community-driven, not just a technical experiment I have to maintain alone. I truly believe in the power of a community.
First Step
So, let’s begin. I’ll start with my favorite part: naming the project. I spent all weekend pondering this, attempting to condense the concept and associate it with a literary term or a Latin word (these are my preferred methods for naming a project).
Let’s define what the ultimate goal is. In an import process, the aim is to take information from a source ‘A’, translate or transform the information, and then store it in a target ‘B’.
Growing up, I was an avid reader – and I mean, I read a lot. (Now, I’ve switched to audiobooks.) Therefore, after defining what this project is about, naming it became incredibly easy.
noun
noun: alchemy
- the medieval forerunner of chemistry, concerned with the transmutation of matter, in particular with attempts to convert base metals into gold or find a universal elixir.
“occult sciences, such as alchemy and astrology”
Origin
late Middle English: via Old French and medieval Latin from Arabic al-kīmiyā’, from al ‘the’ + kīmiyā’ (from Greek khēmia, khēmeia ‘art of transmuting metals’).
The alchemy Framework
Alchemy is a framework created for DotNet, designed to import data from a data source to a data target. These sources and targets can be anything from a text file, CSV file, a database, ORMs, and so on.
The framework consists of a set of contracts, interfaces, and base classes. When implemented, these allow you to import and transform data between various sources and targets.
The requirement in a few words
As stated in the framework’s description, the requirement is only to define the contracts that represent the sources and targets, as well as a job configuration that describes how the information flows from one source to a target. The concrete implementations are not important at this point and should be discussed individually for each case.
The design patterns.
For this project, we will use the SOLID design principles and dependency injection. This will enable us to easily replace small functionalities, allowing us to mix and match different implementations depending on the data source and data target.
by Joche Ojeda | May 5, 2023 | Application Framework, XAF, XPO, XPO Database Replication
I will explain what XAF is just for the sake of the consistency of this article, XAF is a low code application framework for line of business applications that runs on NET framework (windows forms and web forms) and in dotnet (windows forms, Blazor and Web API)
XAF is laser focus on productivity, DevExpress team has created several modules that encapsulate design patterns and common tasks needed on L.O.B apps.
The starting point in XAF is to provide a domain model using an ORMs like XPO or Entity framework and then XAF will create an application for you using the target platform of choice.
It’s a common misunderstanding that you need to use and ORM in order to provide a domain model to XAF
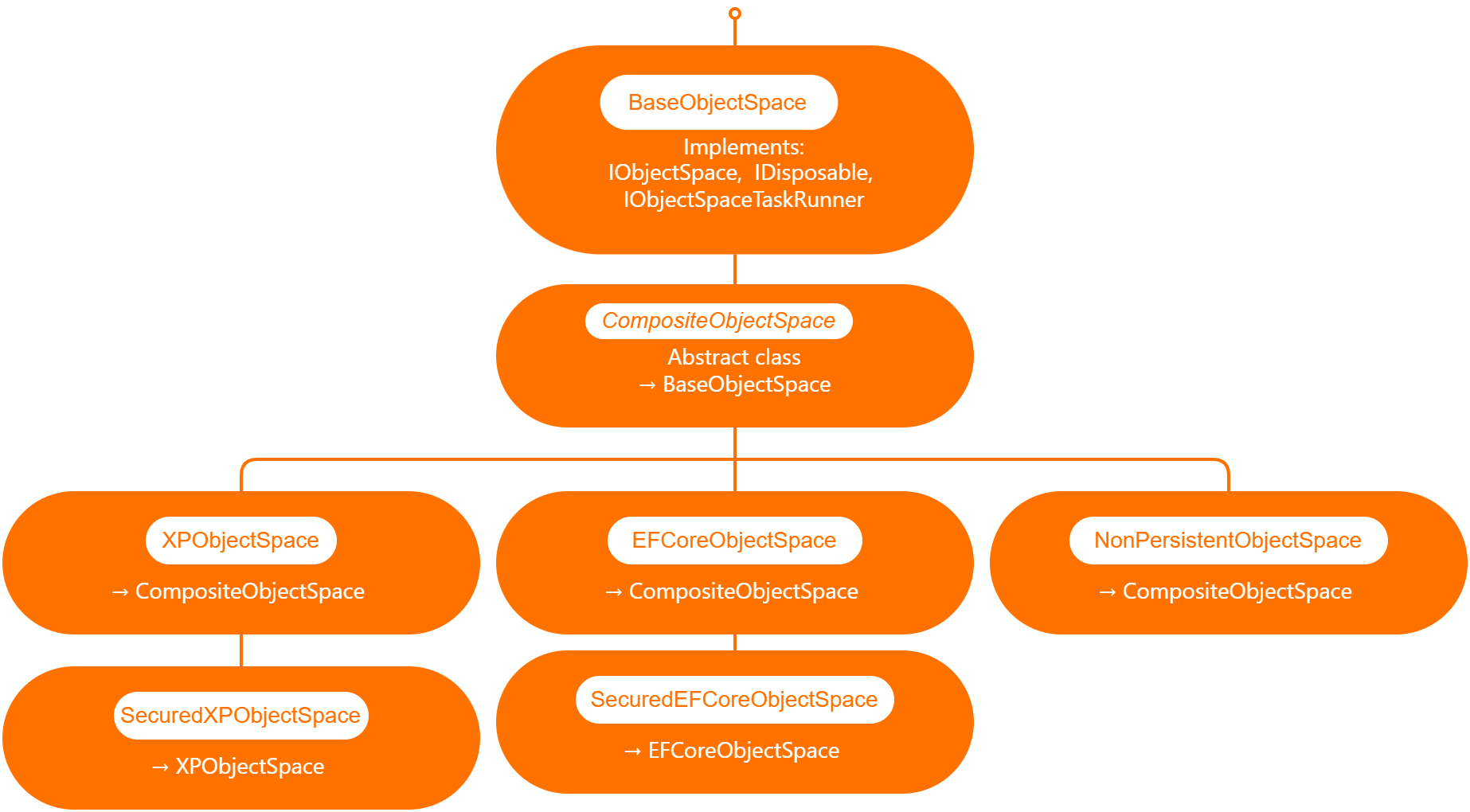
DevExpress team has created ObjectSpace abstraction so XAF can be extended to use different data access technologies ( you can read more about it here https://docs.devexpress.com/eXpressAppFramework/DevExpress.ExpressApp.BaseObjectSpace)
Out of the box XAF provide 3 branches of object spaces as show is the graph below.
XPObjectSpace: this is the object space that allows you to use XPO as a data access technology.
EfCoreObjectSpace: this is the object space that allows you to use Microsoft Entity Framework as a data access technology.
NonPersistenObjectSpace: this object space is interesting as it provides the domain model needed for XAF to generate the views and interact with the data is not attached to an ORM technology so it’s up to us to provide the data, also this type of object space can be used in combination with XPObjectSpace and EfCoreObjectSpace
When querying external data sources, you also need to solve the problem of filtering and sorting data in order to provide a full solution, for that reason DevExpress team provide us with the DynamicCollection class, that is a proxy collection that allows you to filter and sort an original collection without changing it.
Now that we know the parts involved in presenting data in a XAF application, we can define the required flow.
[DefaultClassOptions]
[DefaultProperty(nameof(Article.Title))]
[DevExpress.ExpressApp.ConditionalAppearance.Appearance("", Enabled = false, TargetItems = "*")]
[DevExpress.ExpressApp.DC.DomainComponent]
public class Article : NonPersistentObjectBase {
internal Article() { }
public override void Setup(XafApplication application) {
base.Setup(application);
// Manage various aspects of the application UI and behavior at the module level.
application.SetupComplete += Application_SetupComplete;
}
- Wire the application object space created event.
private void Application_SetupComplete(object sender, EventArgs e) {
Application.ObjectSpaceCreated += Application_ObjectSpaceCreated;
}
private void Application_ObjectSpaceCreated(object sender, ObjectSpaceCreatedEventArgs e) {
var npos = e.ObjectSpace as NonPersistentObjectSpace;
if (npos != null) {
new ArticleAdapter(npos);
new ContactAdapter(npos);
}
}
public ArticleAdapter(NonPersistentObjectSpace npos) {
this.objectSpace = npos;
objectSpace.ObjectsGetting += ObjectSpace_ObjectsGetting;
}
private void ObjectSpace_ObjectsGetting(object sender, ObjectsGettingEventArgs e) {
if(e.ObjectType == typeof(Article)) {
var collection = new DynamicCollection(objectSpace, e.ObjectType, e.Criteria, e.Sorting, e.InTransaction);
collection.FetchObjects += DynamicCollection_FetchObjects;
e.Objects = collection;
}
}
private void DynamicCollection_FetchObjects(object sender, FetchObjectsEventArgs e) {
if(e.ObjectType == typeof(Article)) {
e.Objects = articles;
e.ShapeData = true;
}
}
Full source code here
In conclusion the ObjectSpace abstraction ensures that different data access technologies can be employed, while the DynamicCollection class allows for seamless filtering and sorting of data from external sources. By following the outlined steps, developers can create robust, adaptable, and efficient applications with XAF, ultimately saving time and effort while maximizing application performance.

by Joche Ojeda | Mar 29, 2023 | C#, Linux, netcore, Oqtane, Postgres, Ubuntu
A stack in software development refers to a collection of technologies, tools, and frameworks that are used together to build and run a complete application or solution. A typical stack consists of components that handle different aspects of the software development process, including frontend, backend, databases, and sometimes even the hosting environment.
A stack is often categorized into different layers based on the functionality they provide:
- Frontend: This layer is responsible for the user interface (UI) and user experience (UX) of an application. It consists of client-side technologies like HTML, CSS, and JavaScript, as well as libraries or frameworks such as React, Angular, or Vue.js.
- Backend: This layer handles the server-side logic, processing user requests, and managing interactions with databases and other services. Backend technologies can include programming languages like Python, Ruby, Java, or PHP, and frameworks like Django, Ruby on Rails, or Spring.
- Database: This layer is responsible for storing and managing the application’s data. Databases can be relational (e.g., MySQL, PostgreSQL, or Microsoft SQL Server) or NoSQL (e.g., MongoDB, Cassandra, or Redis), depending on the application’s data structure and requirements.
- Hosting Environment: This layer refers to the infrastructure where the application is deployed and run. It can include on-premises servers, cloud-based platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), or Microsoft Azure, or container orchestration platforms like Kubernetes or Docker Swarm.
Developers often refer to specific combinations of these technologies as named stacks. Some examples include:
- LAMP: Linux (operating system), Apache (web server), MySQL (database), and PHP (backend programming language).
- MEAN: MongoDB (database), Express.js (backend framework), Angular (frontend framework), and Node.js (runtime environment).
- MERN: MongoDB (database), Express.js (backend framework), React (frontend library), and Node.js (runtime environment).
Selecting a stack depends on factors such as project requirements, team expertise, performance, and scalability needs. By using a well-defined stack, developers can streamline the development process, improve collaboration, and ensure that all components work together efficiently.
The P.O.U.N.D. Stack is an innovative software development stack that combines Postgres, Oqtane, Ubuntu, and DotNet to create powerful, modern, and scalable applications. This stack is designed to leverage the strengths of each technology, providing developers with an integrated and efficient environment for building web applications.
- Postgres (P): As the database layer, Postgres offers robust performance, scalability, and support for advanced data types, such as GIS and JSON. Its open-source nature and active community make it a reliable choice for handling the storage and management of application data.
- Oqtane (O): Serving as the frontend framework, Oqtane is built on top of the Blazor technology in .NET, allowing for the creation of modern, responsive, and feature-rich user interfaces. With Oqtane, developers can create modular and extensible applications, while also benefiting from built-in features such as authentication, authorization, and multi-tenancy.
- Ubuntu (U): As the operating system and hosting environment, Ubuntu provides a stable, secure, and easy-to-use platform for deploying and running applications. It is widely supported and offers excellent compatibility with a variety of hardware and cloud platforms, making it an ideal choice for hosting P.O.U.N.D. Stack applications.
- DotNet (D): The backend layer is powered by the .NET framework, which offers a versatile and high-performance environment for server-side development. With support for multiple programming languages (such as C#, F#, and VB.NET), powerful libraries, and a large ecosystem, .NET allows developers to build scalable and efficient backend logic for their applications.
In summary, the P.O.U.N.D. Stack brings together the power of Postgres, Oqtane, Ubuntu, and DotNet to deliver a comprehensive and efficient development stack. By leveraging the unique capabilities of each technology, developers can build modern, scalable, and high-performance web applications that cater to diverse business needs.

by Joche Ojeda | Mar 29, 2023 | Application Framework, Uncategorized, XAF, XPO
based on my experience with numerous application frameworks, I regard XAF as the most efficient in delivering robust solutions quickly and with minimal code. Our company has trained over 100 software firms in utilizing eXpressApp Framework (XAF) and XPO, leading me to believe that the issue typically stems from three factors:
The illusion of productivity
Many software developers perceive themselves as more productive when not using frameworks, as they often associate productivity with the volume of code they produce. This frequently involves reinventing the wheel, and more code does not necessarily bring them closer to their goals.
Grasping the business requirements
This factor is connected to the first, as an unclear or poorly understood business requirement can lead programmers to focus on trivial tasks, such as adding a row to a database, instead of tackling complex business scenarios. As a result, the application framework might be seen as an obstacle by the development team, since it already addresses basic tasks and forces them to confront challenging business problems early on, which they may then attribute to the framework.
Familiarity with both the application framework and the business problem
These two aspects are the primary challenges in Line-of-Business (LOB) software development. The general principle is that one must be equally well-versed in the business problem and the application framework. The worst-case scenario arises when there is limited technical knowledge and high business demands, which, surprisingly, is the most common situation.
In conclusion, the efficiency and effectiveness of application frameworks, such as XAF, in delivering robust solutions with minimal code are often undervalued due to misconceptions and challenges that developers face. Overcoming the illusion of productivity, ensuring a clear understanding of business requirements, and achieving a balance between technical and business expertise are crucial for harnessing the full potential of application frameworks. By addressing these challenges, development teams can unlock the true power of XAF and similar frameworks, streamlining the development process and paving the way for more successful software solutions that cater to complex business needs.