
by Joche Ojeda | Jul 28, 2024 | PropertyEditors, XAF
Introduction
The eXpressApp Framework (XAF) from DevExpress is a versatile application framework that supports multiple UI platforms, including Windows Forms and Blazor. Maintaining separate property editors for each platform can be cumbersome. This article explores how to create unified property editors for both Windows Forms and Blazor by leveraging WebView for Windows Forms and the Monaco Editor, the editor used in Visual Studio Code.
Blazor Implementation
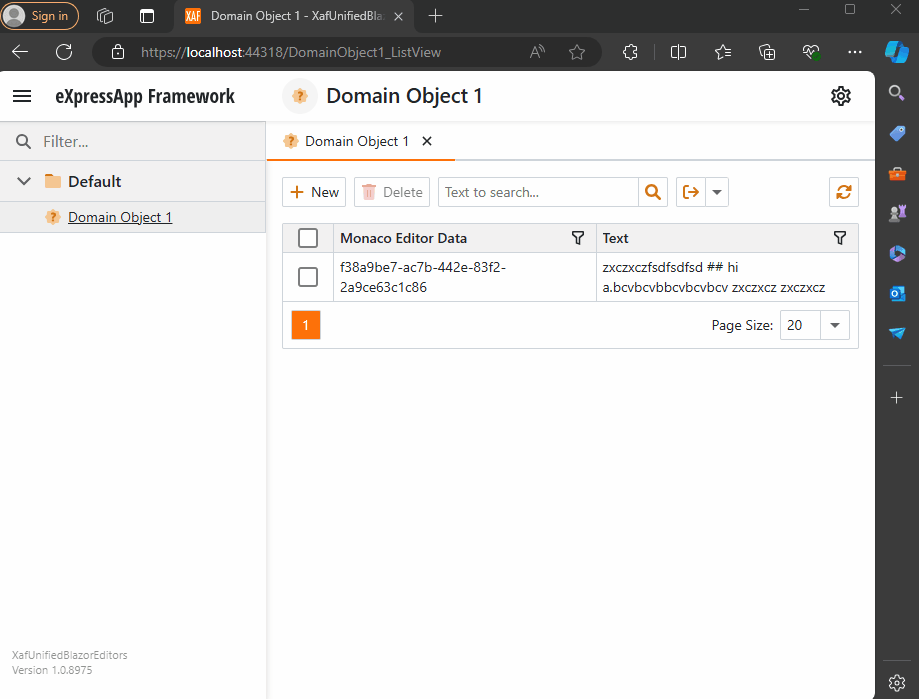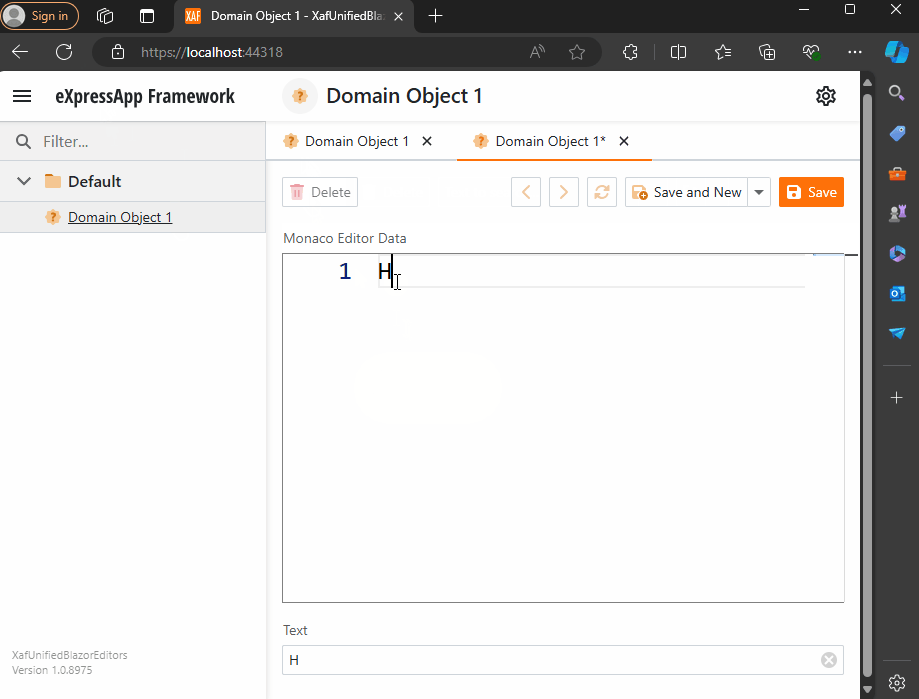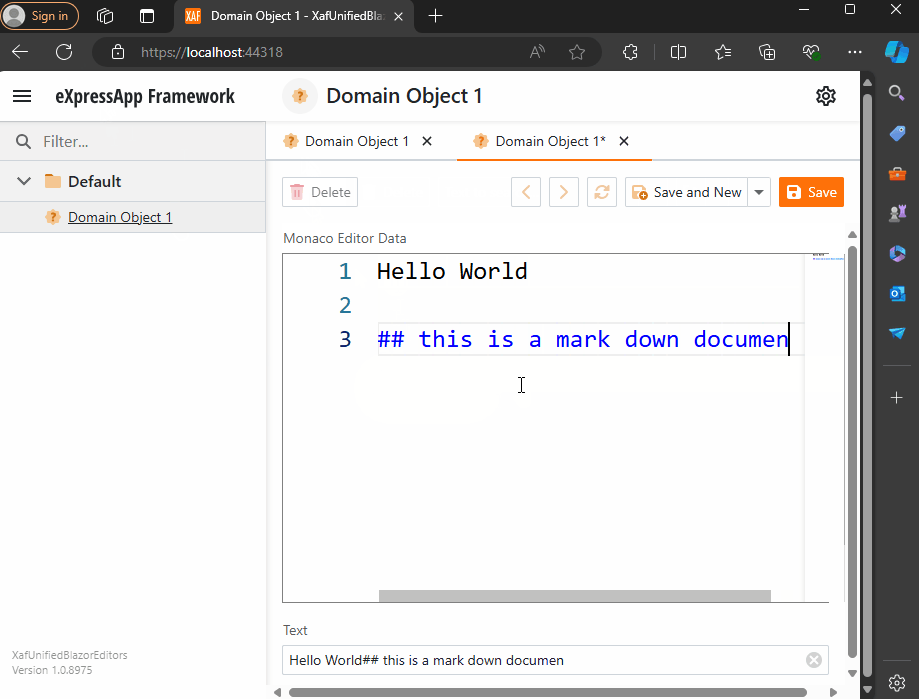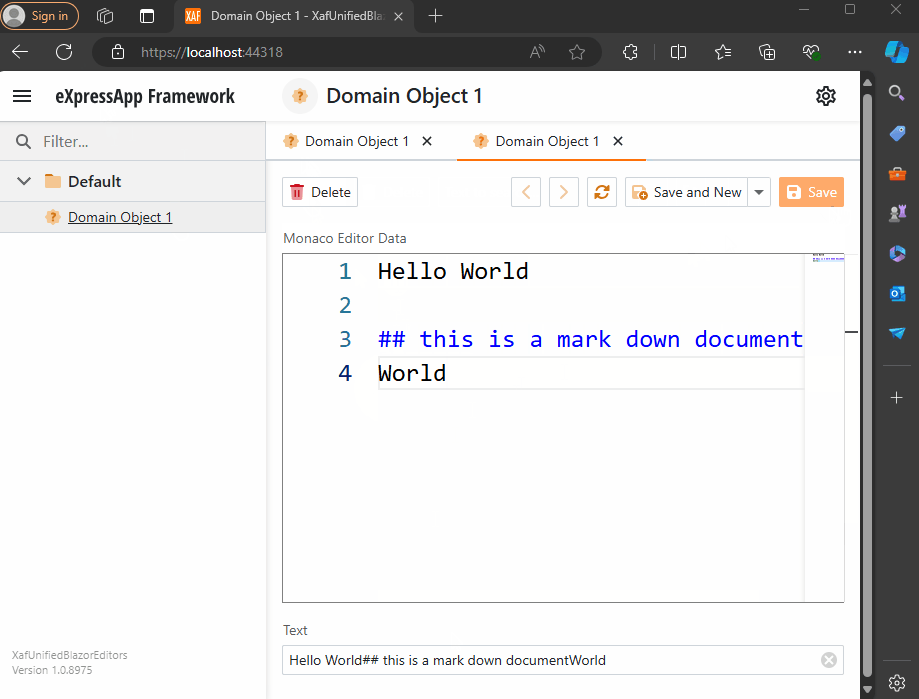
Windows forms Implementation
Prerequisites
Before we begin, ensure you have the following installed:
- Visual Studio 2022 or later
- .NET 8.0 SDK or later
- DevExpress XAF 22.2 or later
Step 1: Create a XAF Application for Windows Forms and Blazor
- Create a New Solution:
- Open Visual Studio and create a new solution.
- Add two projects to this solution:
- A Windows Forms project.
- A Blazor project.
- Set Up XAF:
- Follow the DevExpress documentation to set up XAF in both projects. Official documentation here
Step 2: Create a Razor Class Library
- Create a Razor Class Library:
- Add a new Razor Class Library project to the solution.
- Name it XafVsCodeEditor.
- Design the Monaco Editor Component:
We are done with the shared library that we will reference in both Blazor and Windows projects.
Step 3: Integrate the Razor Class Library into Windows Forms
- Add NuGet References:
- In the Windows Forms project, add the following NuGet packages:
- Microsoft.AspNetCore.Components.WebView.WindowsForms
- XafVsCodeEditor (the Razor Class Library created earlier).
- You can see all the references in the csproj file.
- Change the Project Type: In order to add the ability to host Blazor components, we need to change the project SDK from Microsoft.NET.Sdk to Microsoft.NET.Sdk.Razor.
- Add Required Files:
- wwwroot: folder to host CSS, JavaScript, and the index.html.
- _Imports.razor: this file adds global imports. Source here.
- index.html: one of the most important files because it hosts a special blazor.webview.js to interact with the WebView. See here.
Official Microsoft tutorial is available here.
Step 4: Implementing the XAF Property Editors
I’m not going to show the full steps to create the property editors. Instead, I will focus on the most important parts of the editor. Let’s start with Windows.
In Windows Forms, the most important method is when you create the instance of the control, in this case, the WebView. As you can see, this is where you instantiate the services that will be passed as a parameter to the component, in our case, the data model. You can find the full implementation of the property editor for Windows here and the official DevExpress documentation here.
protected override object CreateControlCore()
{
control = new BlazorWebView();
control.Dock = DockStyle.Fill;
var services = new ServiceCollection();
services.AddWindowsFormsBlazorWebView();
control.HostPage = "wwwroot\\index.html";
var tags = MonacoEditorTagHelper.AddScriptTags;
control.Services = services.BuildServiceProvider();
parameters = new Dictionary<string, object>();
if (PropertyValue == null)
{
PropertyValue = new MonacoEditorData() { Language = "markdown" };
}
parameters.Add("Value", PropertyValue);
control.RootComponents.Add<MonacoEditorComponent>("#app", parameters);
control.Size = new System.Drawing.Size(300, 300);
return control;
}
Now, for the property editor for Blazor, you can find the full source code here and the official DevExpress documentation here.
protected override IComponentModel CreateComponentModel()
{
var model = new MonacoEditorDataModel();
model.ValueChanged = EventCallback.Factory.Create<IMonacoEditorData>(this, value => {
model.Value = value;
OnControlValueChanged();
WriteValue();
});
return model;
}
One of the most important things to notice here is that in version 24 of XAF, Blazor property editors have been simplified so they require fewer layers of code. The magical databinding happens because in the data model there should be a property of the same value and type as one of the parameters in the Blazor component.
Step 5: Running the Application
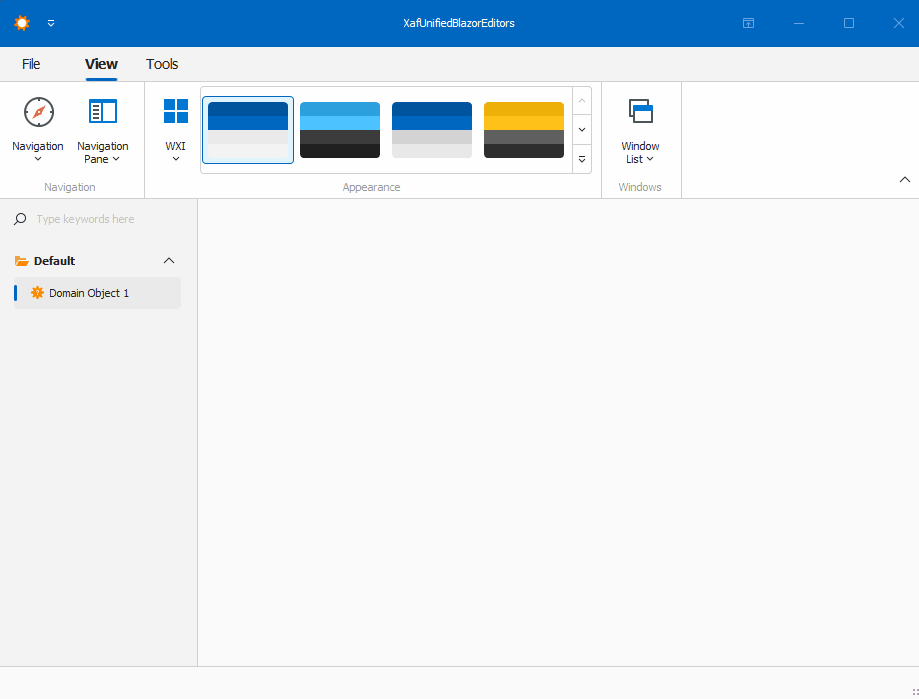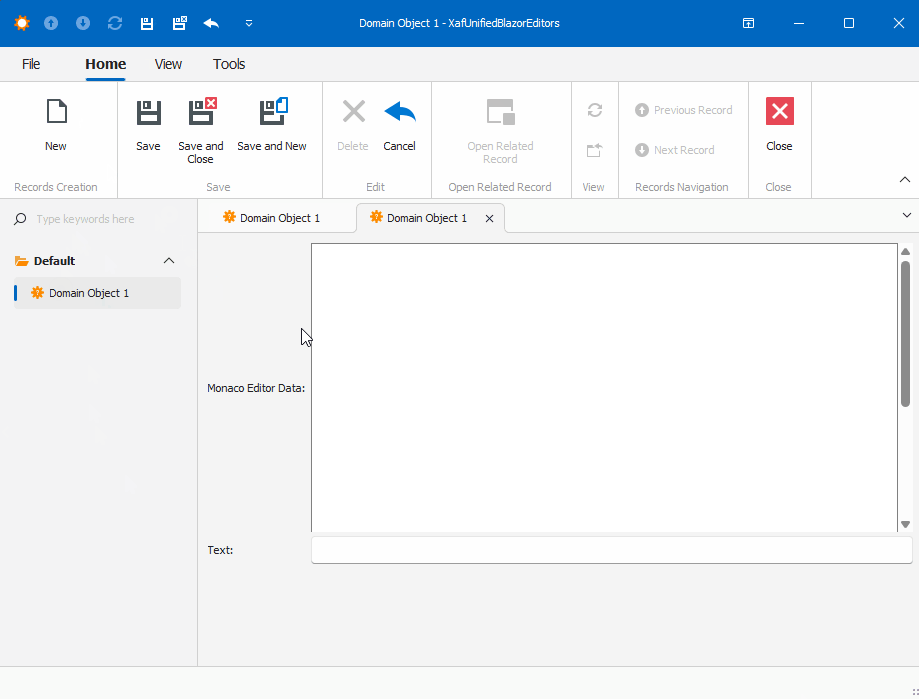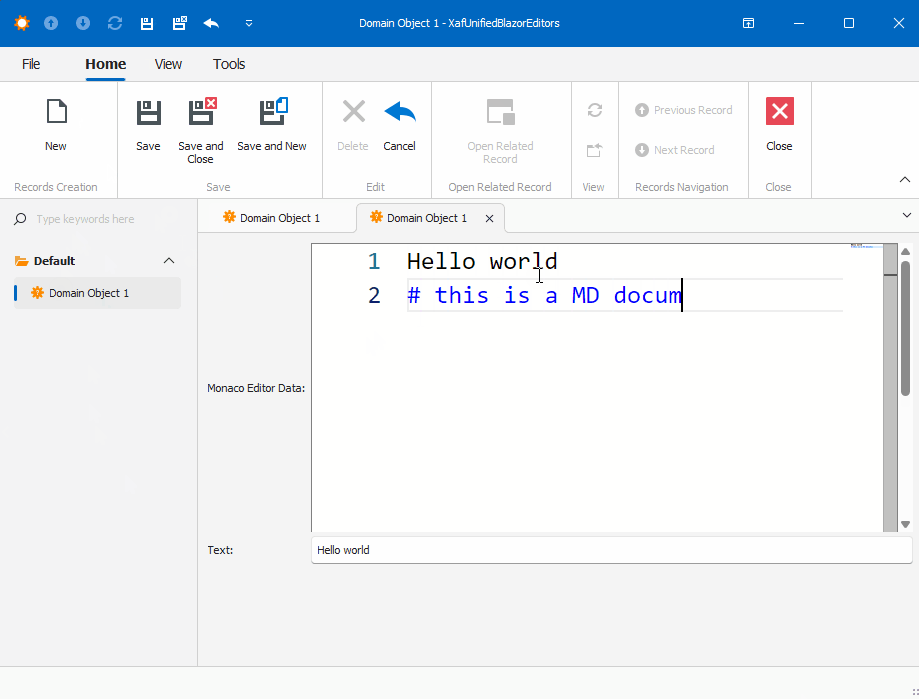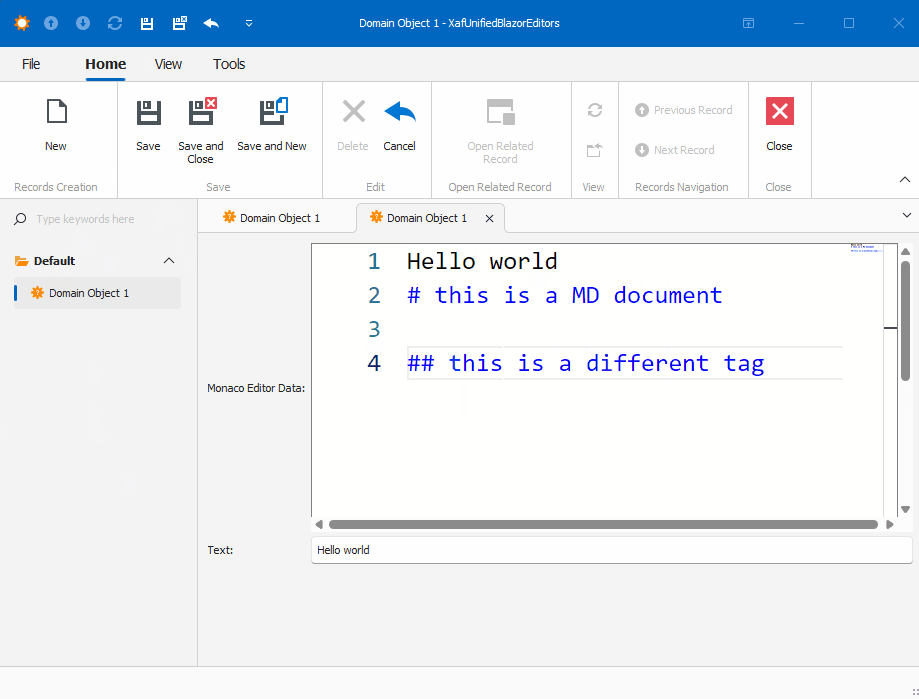
Before we run our solution, we need to add a domain object that implements a property of type IMonacoData, which is the interface we associated with our property editor. Here is a sample domain object that has a property of type MonacoEditorData:
[DefaultClassOptions]
public class DomainObject1 : BaseObject, IXafEntityObject
{
public DomainObject1(Session session) : base(session) { }
public override void AfterConstruction()
{
base.AfterConstruction();
}
MonacoEditorData monacoEditorData;
string text;
public MonacoEditorData MonacoEditorData
{
get => monacoEditorData;
set => SetPropertyValue(nameof(MonacoEditorData), ref monacoEditorData, value);
}
[Size(SizeAttribute.DefaultStringMappingFieldSize)]
public string Text
{
get => text;
set => SetPropertyValue(nameof(Text), ref text, value);
}
public void OnCreated()
{
this.MonacoEditorData = new MonacoEditorData("markdown", "");
MonacoEditorData.PropertyChanged += SourceEditor_PropertyChanged;
}
void IXafEntityObject.OnSaving()
{
this.Text = this.MonacoEditorData.Code;
}
void IXafEntityObject.OnLoaded()
{
this.MonacoEditorData = new MonacoEditorData("markdown", this.Text);
MonacoEditorData.PropertyChanged += SourceEditor_PropertyChanged;
}
private void SourceEditor_PropertyChanged(object sender, PropertyChangedEventArgs e)
{
this.Text = this.MonacoEditorData.Code;
}
}
As you can see, DomainObject1 implements the interface IXafEntityObject. We are using the interface events to load and save the content of the editor to the text property.
Now, build and run the solution. You should now have a Windows Forms application that hosts a Blazor property editor using WebView and the Monaco Editor, as well as a Blazor application using the same property editor.
You can find a working example here.
Conclusion
By leveraging WebView and the Monaco Editor, you can create unified property editors for both Windows Forms and Blazor in XAF applications. This approach simplifies maintenance and provides a consistent user experience across different platforms. With the flexibility of Blazor and the robustness of Windows Forms, you can build powerful and versatile property editors that cater to a wide range of user needs.

by Joche Ojeda | Jul 6, 2024 | Uncategorized
AI Integration and Future Plans
El Salvador has embarked on a remarkable journey of technological transformation under the leadership of President Nayib Bukele. Building on the momentum from its pioneering adoption of Bitcoin as legal tender, the nation is now setting its sights on integrating Artificial Intelligence (AI) into various sectors to foster innovation and growth. This article explores President Bukele’s vision for AI, the potential benefits and challenges, and the critical need for establishing robust AI legislation.
Government Vision for AI
President Bukele envisions a future where AI plays a central role in El Salvador’s development. In recent developments, he appointed Brian Roemmele, a renowned expert in voice technology and AI, as an AI advisor. Roemmele’s appointment highlights the government’s commitment to integrating AI to drive economic growth and educational opportunities, positioning El Salvador as a leader in the digital age[7][8][9].
Economic Growth: By fostering an environment conducive to AI innovation, El Salvador aims to attract tech companies and startups, thereby boosting economic growth and creating high-tech job opportunities.
Smart Governance: The integration of AI in government operations promises to enhance efficiency, transparency, and responsiveness, making public administration more effective and citizen-centric[28][30].
Global Competitiveness: Bukele’s vision includes positioning El Salvador as a leader in AI within Latin America, much like its pioneering role with Bitcoin. This involves not only adopting AI technologies but also setting standards that other countries can follow.
Potential Benefits and Challenges
The potential benefits of AI integration are immense:
Economic Benefits: AI can drive significant economic growth by improving productivity, fostering innovation, and creating new job sectors[28][30].
Social Benefits: AI can enhance the quality of life by improving healthcare, education, and public services, leading to a more inclusive and equitable society[27][29].
However, the challenges cannot be overlooked:
Ethical Concerns: Ensuring that AI systems are fair, transparent, and free from bias is crucial to prevent societal harm.
Data Privacy: Protecting the personal data of citizens is essential to maintain trust and prevent misuse.
Workforce Displacement: The transition to an AI-driven economy must be managed carefully to support workers displaced by automation through reskilling and education initiatives.
The Need for AI Legislation
To harness the full potential of AI while addressing its challenges, it is imperative to establish a comprehensive AI legal framework. This framework should cover several key areas:
1. Ethical Standards
- Transparency: AI developers must disclose methodologies and data sources to ensure clarity and trust.
- Accountability: Clear accountability mechanisms for AI decisions, especially in critical sectors like healthcare and finance.
- Fairness: Measures to prevent bias and ensure equitable treatment for all users of AI systems.
2. Data Protection
- Privacy Laws: Strengthened data privacy laws to safeguard citizens’ information.
- Consent: Ensuring individuals have control over their data, including the ability to opt-out of AI data processing.
3. Innovation Incentives
- Research Grants: Funding for AI research and development projects.
- Tax Breaks: Tax incentives for companies investing in AI technologies and infrastructure.
4. Workforce Transition
- Reskilling Programs: Programs to help workers displaced by AI acquire new skills and transition to new job opportunities in the AI sector.
- Education Initiatives: Integrating AI and digital literacy into the national education curriculum.
5. International Cooperation
- Standards Collaboration: Working with international bodies to adopt global AI standards and best practices.
- Regional Partnerships: Fostering regional cooperation in AI research and development.
Conclusion
El Salvador’s journey towards technological transformation continues with the integration of AI. By setting the rules for AI through robust legislation, El Salvador can ensure that it remains at the forefront of innovation in Latin America. The proposed AI legal framework not only addresses the ethical and practical challenges of AI but also positions the country as a leader in the digital future. As El Salvador charts this new course, the commitment to innovation and responsible governance will be key to its success.
This article outlines the government’s vision for AI in El Salvador, the potential benefits and challenges, and the critical need for AI legislation. It aims to inform and engage readers, encouraging them to support and contribute to the country’s digital future.
Related Articles
El Salvador: Digital Transformation Initiatives
El Salvador: The Implementation of Bitcoin as Legal Tender
El Salvador’s Technological Revolution

by Joche Ojeda | Jul 5, 2024 | El Salvador, Uncategorized
Partnerships with Tech Giants
El Salvador has embarked on an ambitious journey of digital transformation, significantly bolstered by strategic partnerships with leading technology companies. These collaborations have been pivotal in advancing the country’s technological landscape across various sectors.
One notable partnership is with Google, focusing on enhancing healthcare, education, and digital government services. Google’s involvement includes the deployment of cloud services to streamline government operations and the integration of AI tools to improve healthcare delivery. Through these initiatives, El Salvador aims to enhance the efficiency and accessibility of public services, ensuring that technology benefits all citizens.
In the education sector, partnerships with tech giants are transforming learning environments. Google Classroom and other digital platforms are being integrated into schools, enabling remote learning and enhancing the quality of education. These tools not only facilitate learning during crises like the COVID-19 pandemic but also prepare students for a digital future.
Development of Digital Infrastructure
Central to El Salvador’s digital transformation is the robust development of digital infrastructure. The government has made significant investments to ensure widespread internet access, recognizing it as a cornerstone for digital inclusion. Efforts include expanding broadband coverage to rural areas and implementing 5G technology in urban centers.
Digital payment systems have also seen substantial growth. The introduction of the Chivo Wallet, a government-backed digital wallet, marked a significant step in promoting cashless transactions. This initiative aligns with the broader goal of fostering a digital economy and reducing the reliance on traditional banking systems. Moreover, the Chivo Wallet’s integration with Bitcoin and other cryptocurrencies opens new avenues for financial inclusion and innovation.
E-government platforms are another critical component of this transformation. The government has launched various online portals to streamline public services, from tax filing to business registrations. These platforms not only enhance efficiency but also reduce bureaucratic hurdles, making it easier for citizens and businesses to interact with the government.
Efforts to Improve Digital Literacy
Recognizing that technological advancements are only as effective as the population’s ability to use them, El Salvador has prioritized digital literacy. The government, in collaboration with educational institutions and private sector partners, has launched comprehensive programs aimed at improving digital skills across the population.
For the general public, initiatives include community training programs and digital literacy campaigns. These efforts focus on teaching basic computer skills, internet navigation, and the safe use of digital tools. By equipping citizens with these skills, the government aims to ensure that everyone can participate in the digital economy and access online services.
In the education sector, digital literacy is being integrated into the national curriculum. Schools are now equipped with modern technology, and teachers receive training on digital teaching methods. This approach not only prepares students for future job markets but also fosters a culture of innovation and technological proficiency from a young age.
Government employees are also a focus of digital literacy efforts. Specialized training programs have been developed to enhance the digital skills of public sector workers. These programs aim to improve the efficiency of government operations and ensure that public servants can effectively use new technologies in their daily tasks.
Conclusion
El Salvador’s digital transformation under President Nayib Bukele is a multifaceted effort encompassing strategic partnerships, infrastructure development, and comprehensive digital literacy programs. By working with tech giants like Google, investing in digital infrastructure, and prioritizing digital education, the country is laying a strong foundation for a technologically advanced future. These initiatives not only improve the quality of life for Salvadorans but also position the country as a leader in digital innovation within Latin America. As El Salvador continues to embrace digital transformation, it serves as a compelling case study for other nations seeking to navigate the complexities of the digital age.
Related Articles
El Salvador: The Implementation of Bitcoin as Legal Tender
El Salvador’s Technological Revolution

by Joche Ojeda | Jul 4, 2024 | Bitcoin, El Salvador
Background
Before delving into the specifics of Bitcoin’s adoption, it’s crucial to understand the economic landscape of El Salvador. Historically, the country has faced significant economic challenges, including high poverty rates, limited access to financial services, and a heavy reliance on remittances, which account for about 20% of its GDP. Since 2001, El Salvador has used the US dollar as its official currency, which has provided stability but also limited monetary policy options for the government.
Bitcoin Law
On June 9, 2021, El Salvador made headlines worldwide by becoming the first country to adopt Bitcoin as legal tender. The Bitcoin Law, proposed by President Nayib Bukele and swiftly passed by the Legislative Assembly, mandates that Bitcoin must be accepted as a form of payment by all businesses and allows it to be used for all debts, public or private. The law’s key provisions include:
- Mandatory Acceptance: All economic agents must accept Bitcoin as payment when offered by the buyer.
- Tax Contributions: Tax contributions can be paid in Bitcoin.
- Pricing: Prices can be expressed in Bitcoin.
- Exchanges: Exchanges between Bitcoin and the US dollar will be exempt from capital gains tax.
- Government Support: The government will promote the necessary training and mechanisms so that the population can access Bitcoin transactions.
The initial public response was mixed. While some saw it as a groundbreaking move to modernize the economy, others were skeptical about the volatility of Bitcoin and its potential impacts on everyday transactions.
Implementation
The implementation of Bitcoin involved several key steps:
- Chivo Wallet: The government developed the Chivo Wallet, a digital wallet that allows users to store and transact in Bitcoin and US dollars. To incentivize adoption, each user who signed up received $30 worth of Bitcoin.
- Bitcoin ATMs: A network of Bitcoin ATMs was established across the country to facilitate the exchange between Bitcoin and US dollars.
- Government Investments: The Salvadoran government made several Bitcoin purchases, intending to stabilize the market and show confidence in the new system.
Despite initial technical glitches and skepticism, the government continued to promote Bitcoin adoption through educational campaigns and infrastructure development.
Impact
Economic Impact
- Financial Inclusion: Bitcoin has provided an opportunity for financial inclusion, particularly for the unbanked population. With around 70% of Salvadorans lacking access to traditional banking services, Bitcoin offers an alternative means of participating in the economy.
- Remittances: The use of Bitcoin for remittances has the potential to reduce transaction fees and speed up transfer times, benefiting many Salvadoran families who rely on money sent from abroad.
- Investment and Tourism: The Bitcoin initiative has attracted international attention, potentially boosting tourism and foreign investment. The country has seen a surge in crypto-related tourism, with enthusiasts visiting to experience a Bitcoin-driven economy firsthand.
Social Impact
- Education and Awareness: The push for Bitcoin has necessitated widespread educational efforts to ensure that the population understands how to use and benefit from digital currency. This has sparked broader discussions about financial literacy and digital technologies.
- Public Sentiment: Public opinion remains divided. While some embrace the innovation, others fear the volatility of Bitcoin and the implications for price stability and everyday transactions.
Conclusion
El Salvador’s bold move to adopt Bitcoin as legal tender marks a significant milestone in its technological transformation. While the long-term effects are still unfolding, this initiative positions the country at the forefront of digital currency adoption. The next steps involve addressing the challenges of volatility, continuing to educate the population, and monitoring the broader economic impacts. As the world watches, El Salvador’s experiment with Bitcoin will provide valuable lessons for other nations considering similar paths.
Related Articles
El Salvador’s Technological Revolution

by Joche Ojeda | Jul 3, 2024 | A.I, Blockchain, El Salvador
El Salvador, my birthplace, has recently emerged as a focal point for technological innovation under the leadership of President Nayib Bukele. Born in Suchitoto during the civil war and now living as a digital nomad in Saint Petersburg, Russia, I have witnessed El Salvador’s transformation from a distance and feel compelled to share its story. This article is the first in a series exploring how blockchain technology, financial services, and artificial intelligence (AI) can help a small country like El Salvador grow.
Historical Context and Economic Challenges
El Salvador has faced significant economic challenges over the past few decades, including poverty, gang violence, and a heavy reliance on remittances from abroad. The economy has traditionally been rooted in agriculture, with coffee and sugar being key exports. However, President Bukele, who took office on June 1, 2019, has sought to address these challenges by diversifying the economy and embracing technology as a key driver of growth.
Bukele’s Vision for Economic Transformation
President Bukele’s administration has prioritized technological innovation as a catalyst for economic transformation. His vision is to modernize the country’s infrastructure and position El Salvador as a hub for technological innovation in Latin America. This vision includes the strategic shift from an agriculture-based economy to one focused on technology, financial services, and tourism. The goal is to create a more resilient and diverse economic base that can sustain long-term growth and development.
The Adoption of Bitcoin as Legal Tender
One of the most groundbreaking moves by Bukele’s administration was the introduction of the Bitcoin Law, passed by the Legislative Assembly on June 9, 2021. This law made Bitcoin legal tender alongside the US dollar, which had been the country’s official currency since 2001. The rationale behind this decision was multifaceted:
- Financial Inclusion: With a significant portion of the population lacking access to traditional banking services, Bitcoin offers an alternative means of financial inclusion.
- Reduction in Remittance Costs: Remittances make up a substantial part of El Salvador’s economy. Bitcoin’s adoption aims to reduce the high transaction fees associated with remittance services.
- Economic Innovation: By adopting Bitcoin, El Salvador aims to attract foreign investment and position itself as a leader in cryptocurrency and blockchain technology.
The implementation of Bitcoin involved launching the Chivo Wallet, a state-sponsored digital wallet designed to facilitate Bitcoin transactions. The government also incentivized adoption by offering $30 worth of Bitcoin to citizens who registered for the wallet.
Initial Reactions and Impact
The reaction to the Bitcoin Law was mixed. While some praised the move as innovative and forward-thinking, others raised concerns about the volatility of Bitcoin and its potential impact on the economy. Despite these concerns, the Bukele administration has remained committed to its Bitcoin strategy, continuing to invest in Bitcoin and integrate it into the national economy.
Digital Transformation Initiatives
I
n addition to Bitcoin adoption, El Salvador has partnered with global tech giants like Google to enhance its digital infrastructure. These partnerships aim to modernize government services, improve healthcare through telemedicine platforms, and revolutionize education by integrating AI-driven tools. For instance, Google’s collaboration with the Salvadoran government includes training government agencies on cloud technologies and developing platforms that allow interoperability between institutions.
Strategic Shift to Technology, Financial Services, and Tourism
President Bukele’s broader economic strategy involves shifting El Salvador’s economic focus from traditional agriculture to more dynamic and sustainable sectors like technology, financial services, and tourism. This shift aims to create high-value jobs, attract foreign investment, and build a more diversified economy.
- Technology: By investing in digital infrastructure and fostering a favorable environment for tech startups, El Salvador aims to become a regional tech hub.
- Financial Services: The adoption of Bitcoin and other fintech innovations is intended to transform the financial landscape, making it more inclusive and efficient.
- Tourism: Enhancing the country’s tourism sector, with initiatives to promote its natural beauty and cultural heritage, is another key pillar of Bukele’s economic strategy.
Conclusion and Future Prospects
El Salvador’s journey towards becoming a technological leader in Latin America is a testament to the transformative power of visionary leadership and innovative policies. Under President Bukele, the country has taken bold steps to embrace technology, from adopting Bitcoin to integrating AI into public services. This series of articles will delve deeper into these initiatives, exploring their impact, challenges, and the future prospects for El Salvador in the global technological landscape.
By understanding El Salvador’s technological revolution, we can gain insights into the potential for other nations to leverage technology for economic and social development. The next article in this series will focus on the detailed implementation of Bitcoin as legal tender, examining the steps taken by the Bukele administration and the outcomes observed so far.
This introductory article sets the stage for a comprehensive exploration of El Salvador’s technological transformation under President Bukele. The subsequent articles will provide in-depth analyses and propose potential AI legislation to ensure the country’s continued leadership in technology within Latin America.