
by Joche Ojeda | Jul 26, 2023 | Blazor, C#, Sqlite, WebAssembly
In the evolving panorama of contemporary web application development, a technology that has particularly caught attention is Microsoft’s Blazor WebAssembly. This powerful tool allows for a transformative approach to managing and interacting with client-side data, offering innovative capabilities that are shaping the future of web applications.
Understanding Blazor WebAssembly
Blazor WebAssembly is a client-side web framework from Microsoft. It allows developers to build interactive web applications using C# instead of JavaScript. As the name suggests, it uses WebAssembly, a binary instruction format for a stack-based virtual machine, providing developers with the ability to run client-side web applications directly in the browser using .NET.
The Power of SQLite
SQLite, on the other hand, is a software library that provides a relational database management system (RDBMS). It operates directly on disk files without the need for a separate server process, making it ideal for applications that need local storage. It’s compact, requires zero-configuration, and supports most of the SQL standard, making it an excellent choice for client-side data storage and manipulation.
Combining Blazor WebAssembly with SQLite
By combining these two technologies, you can unlock the full potential of client-side data handling. Here’s how:
Self-Contained and Cross-Platform Development
Both Blazor WebAssembly and SQLite are self-contained systems, requiring no external dependencies. They also both provide excellent cross-platform support. This makes your applications highly portable and reduces the complexity of the development environment.
Offline Availability
SQLite enables the storage of data directly in the client’s browser, allowing your Blazor applications to work offline. Changes made offline can be synced with the server database once the application goes back online, providing a seamless user experience.
Superior Performance
Blazor WebAssembly runs directly in the browser, offering near-native performance. SQLite, being a lightweight yet powerful database, reads and writes directly to ordinary disk files, providing high-speed data access. This combination ensures your application runs quickly and smoothly.
Full .NET Support and Shared Codebase
With Blazor, you can use .NET for both client and server-side code, enabling code sharing and eliminating the need to switch between languages. Coupled with SQLite, developers can use Entity Framework Core to interact with the database, maintaining a consistent, .NET-centric development experience.
Where does the magic happens?
The functionality of SQLite with WebAssembly may vary based on your target framework. If you’re utilizing .NET 6 and Microsoft.Data.SQLite 6, your code will reference SQLitePCLRaw.bundle_e_sqlite3 version 2.0.6. This bundle doesn’t include the native SQLite reference, as demonstrated in the following image
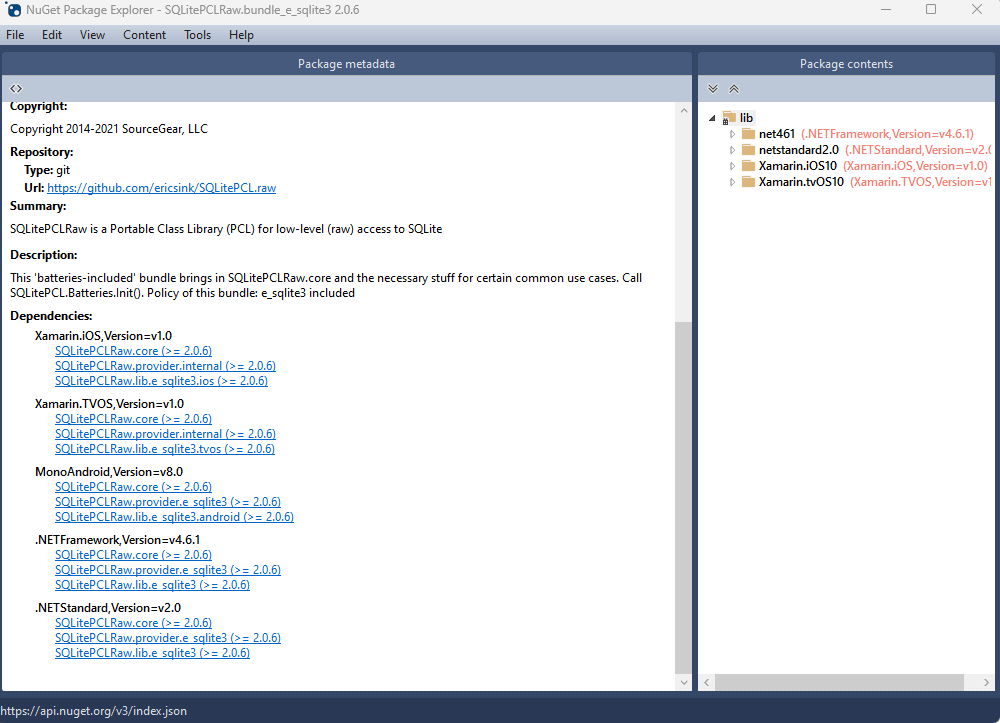
This implies that you’ll need to rely on .NET 6’s native dependencies to include your custom version of lib.e_sqlite3, compiled specifically for WebAssembly. For more detailed information about native dependencies, please refer to the provided links.
https://github.com/egarim/XpoNet6WasmSqlite
https://learn.microsoft.com/en-us/aspnet/core/blazor/webassembly-native-dependencies?view=aspnetcore-6.0
If you’re using .NET 7 or later, your reference from Microsoft.Data.SQLite will depend on SQLitePCLRaw.bundle_e_sqlite3 version 2.1.5. This bundle provides several targets for the native SQLite library (e_sqlite3), as can see in the accompanying image.
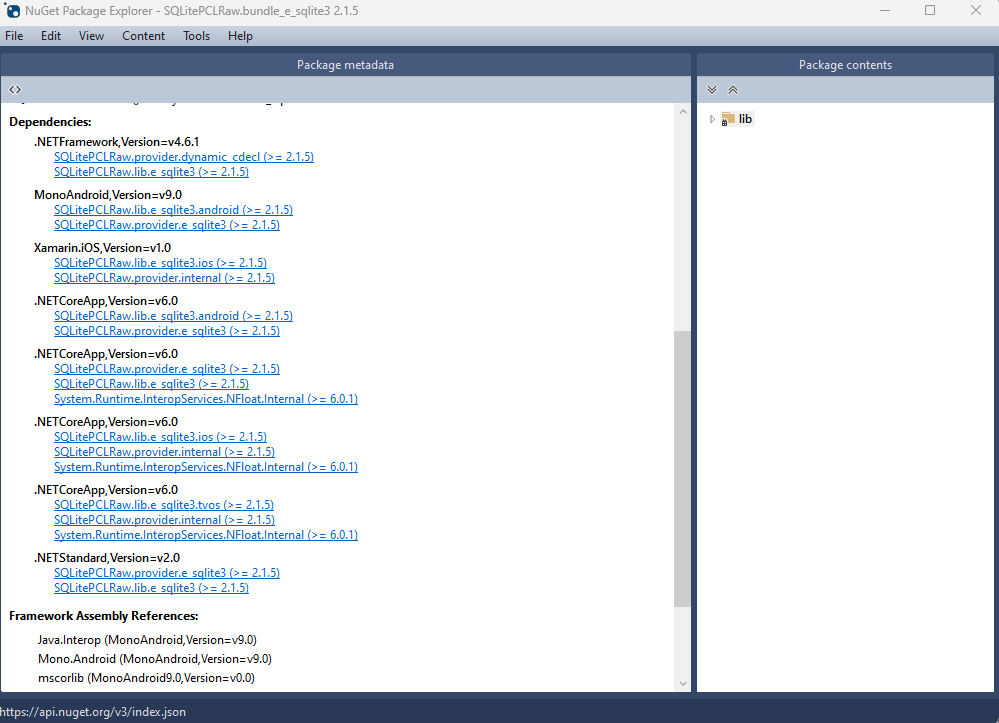
This indicates that we can utilize SQLite on any platform supported by .NET, provided that we supply the native reference for SQLite.
Conclusion
Blazor WebAssembly and SQLite together offer a compelling option for developers looking to leverage the power of client-side data. Their combination enables the development of web applications with high performance, offline availability, and a unified language platform.
This potent mix empowers developers to rethink what’s possible with web application development, pushing the boundaries of what we can achieve with client-side data storage and manipulation. In a world where user experience is paramount, the coupling of these technologies truly helps in unleashing the full potential of client-side data.
by Joche Ojeda | Jul 17, 2023 | Blazor, C#, Data Synchronization, EfCore, WebAssembly
Last week, I decided to create a playground for the SyncFramework to demonstrate how synchronization works. The sync framework itself is not designed in a client-server architecture, but as a set of APIs that you can use to synchronize data.
Synchronization scenarios usually involve a client-server architecture, but when I created the SyncFramework, I decided that network communication was something outside the scope and not directly related to data synchronization. So, instead of embedding the client-server concept in the SyncFramework, I decided to create a set of extensions to handle these scenarios. If you want to take a look at the network extensions, you can see them here.
Now, let’s return to the playground. The main requirement for me, besides showing how the synchronization process works, was not having to maintain an infrastructure for it. You know, a Sync Server and a few databases that I would have to constantly delete. So, I decided to use Blazor WebAssembly and SQLite databases running in the browser. If you want to know more about how SQLite databases can run in the browser, take a look at this article.
Now, there’s still a problem. How do I run a server on the browser? I know it’s somehow possible, but I did not have the time to do the research. So, I decided to create my own HttpClientHandler.
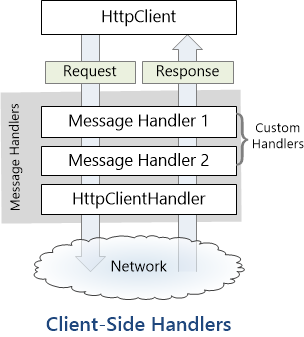
How the HttpClientHandler works
HttpClientHandler offers a number of attributes and methods for controlling HTTP requests and responses. It serves as the fundamental mechanism for HttpClient’s ability to send and receive HTTP requests and responses.
The HttpClientHandler manages aspects like the maximum number of redirects, redirection policies, handling cookies, and automated decompression of HTTP traffic. It can be set up and supplied to HttpClient to regulate the HTTP requests made by HttpClient.
HttpClientHandler might be helpful in testing situations when it’s necessary to imitate or mock HTTP requests and responses. The SendAsync method of HttpMessageHandler, from which HttpClientHandler also descended, can be overridden in a new class to deliver any response you require for your test.
here is a basic example
public class TestHandler : HttpMessageHandler
{
protected override async Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
// You can check the request details and return different responses based on that.
// For simplicity, we're always returning the same response here.
var responseMessage = new HttpResponseMessage(HttpStatusCode.OK)
{
Content = new StringContent("Test response.")
};
return await Task.FromResult(responseMessage);
}
}
And here’s how you’d use this handler in a test:
[Test]
public async Task TestHttpClient()
{
var handler = new TestHandler();
var client = new HttpClient(handler);
var response = await client.GetAsync("http://example.com");
var responseContent = await response.Content.ReadAsStringAsync();
Assert.AreEqual("Test response.", responseContent);
}
The TestHandler in this illustration consistently sends back an HTTP 200 response with the body “Test response.” In a real test, you might use SendAsync with more sophisticated logic to return several responses depending on the specifics of the request. By doing so, you may properly test your code’s handling of different answers without actually sending HTTP queries.
Going back to our main story
Now that we know we can catch the HTTP request and handle it locally, we can write an HttpClientHandler that takes the request from the client nodes and processes them locally. Now, we have all the pieces to make the playground work without a real server. You can take a look at the implementation of the custom handler for the playground here
Until next time, happy coding )))))

by Joche Ojeda | Jul 10, 2023 | Blazor, Sqlite, WebAssembly
Blazor is a framework for building interactive client-side web UI with .NET, developed by Microsoft. It allows developers to build full-stack web applications using C# instead of JavaScript.
Blazor comes in two different hosting models:
1. Blazor Server: In this model, the application runs on the server from within an ASP.NET Core app. UI updates, event handling, and JavaScript calls are handled over a SignalR connection.
2. Blazor Web Assembly: In this model, the application runs directly in the browser on a Web Assembly-based .NET runtime. Blazor Web Assembly includes a proper .NET runtime implemented in Web Assembly, a standard that defines a binary format for executable programs in web pages.
In both models, you can write your code in C#, compile it, and have it run in the browser. However, the way the code is executed differs significantly.
Blazor Web Assembly has a few key features:
– Runs in the browser: The app’s .NET assemblies and its runtime are downloaded into the browser and run locally. There’s no need for ongoing active server connection like in Blazor Server.
– Runs on Web Assembly: Web Assembly (wasm) is a binary instruction format for a stack-based virtual machine. It’s designed as a portable target for the compilation of high-level languages like C, C++, and Rust, allowing deployment on the web for client and server applications.
– Can be offline capable: Blazor Web Assembly apps can download the necessary resources to the client machine and run offline.
– Full .NET debugging support: Developers can debug their application using the tools they are accustomed to, like Visual Studio and Visual Studio Code.
– Sharing code between server and client: Since Blazor uses .NET for both server-side and client-side, code can easily be shared or moved, which is especially useful for data validation and model classes.
SQLite
As an alternative, Indexed DB, a low-level API for client-side storage of significant amounts of structured data, can be used as a backing store. However, using SQLite in a web browser through Web Assembly and Indexed DB is a rather advanced topic that may require additional libraries to manage the details.
Another way to use SQLite with Web Assembly is on the server side, particularly when using technologies like WASI (Web Assembly System Interface), which aims to extend the capabilities of Web Assembly beyond the browser. With WASI, Web Assembly modules could directly access system resources like the file system, and thus could interact with an SQLite database in a more traditional way.
Web Assembly and Native References
Applications built with Blazor Web Assembly (since net6) can incorporate native dependencies that are designed to function on Web Assembly. The .NET Web Assembly construction tools, which are also utilized for ahead-of-time (AOT) compilation of a Blazor application to Web Assembly and for relinking the runtime to eliminate unnecessary features, allow you to integrate these native dependencies into the .NET Web Assembly runtime statically.
This mean that if you are targeting net 6 in your Blazor Web Assembly application you can include the SQLite native Web Assembly reference and use all the power of a full SQL engine in your SPA application. If you want to learn more about native references here is the link for the official documentation
https://learn.microsoft.com/en-us/aspnet/core/blazor/webassembly-native-dependencies?view=aspnetcore-6.0
Including SQLite native reference in you Blazor Web Assembly project
The first thing that we need to do to use SQLite native reference in a web assembly application is to compile it from the source, you can do that in Linux or WSL
sudo apt-get install cmake default-jre git-core unzip
git clone https://github.com/emscripten-core/emsdk.git
cd emsdk
./emsdk install latest
./emsdk activate latest
source ./emsdk_env.sh
Command to compile SQLite as a web assembly reference
emcc sqlite3.h -shared -o e_sqlite3.o
Now that we have the native reference we need to refence it in the web assembly project
First we need to suppress the warnings we will get by adding native refences, so we need to include this lines in the project
<PropertyGroup>
<!-- The following two are to suppress spurious build warnings from consuming Sqlite. -->
<!--These will become unnecessary when the Sqlite packages contain a dedicated WASM binary. -->
<AllowUnsafeBlocks>true</AllowUnsafeBlocks>
<EmccExtraLDFlags>-s WARN_ON_UNDEFINED_SYMBOLS=0</EmccExtraLDFlags>
</PropertyGroup>
Now we are ready to include the reference
<ItemGroup>
<PackageReference Include="Microsoft.Data.Sqlite" Version="6.0.3" />
<NativeFileReference Include="e_sqlite3.o" />
</ItemGroup>
And voila, now we can use a SQLite database in web assembly
If you want to learn more about native references here are a few links that you might find interesting
Remember in this example we just talked about SQLite native reference but there is a world of native reference to explore, until next time, happy coding ))

by Joche Ojeda | Jul 4, 2023 | Uncategorized
Last week, I had two presentations, during both of which I was to present an example of data synchronization using the open-source framework we developed in our office, Xari/BitFrameworks. you can read more about the framework here https://github.com/egarim/SyncFramework
I practiced the demo several times and felt confident about it. After all, I was the one who made the last commit to the source. When the conference began, it was my time to shine. I eagerly spoke about the merits of the framework, then it was time for the technical demo.
Everything started well, but after a while, the framework stopped synchronizing data. I was baffled; I had practiced my demo multiple times. What could have gone wrong?
At the end of the demo, I did what everyone does when their presentation fails—I blamed the demo gods.
After resting for a few hours, I reset my computer and cleaned the Visual Studio solution. I practiced several more times and was ready for round two.
I repeated my presentation and reached the technical demo. There was nothing to fear, right? The previous failure was just a fluke… or so I thought. The demo failed even earlier this time. I cursed the demo gods and finished my presentation.
It was a hard week. I didn’t get the dopamine rush I usually got from presentations. It was a rainy Saturday morning, perfect weather to contemplate my failure. I decided not to give up and wrote some integration tests to determine what went wrong.
So why did my demo fail? The demo was about database synchronization using delta encoding theory. For a successful synchronization, I needed to process the deltas in the exact order they were sent to the server. I had a GUID type of index to sort the deltas, which seemed correct because every time I ran the integration test, it worked fine.
Still puzzled by why the demo failed, I decided to go deeper and wrote an integration test for the GUID generation process. I even wrote an article about it, which you can read here.
On my GUID, common problems using GUID identifiers
Now I was even more puzzled. The tests passed sometimes and failed other times. After a while, I realized there was a random element in how GUIDs are generated that introduced a little-known factor: probabilistic errors.
Probabilistic errors in software refer to a category of errors that occur due to the inherent randomness and uncertainty in some algorithms or systems. These errors are not deterministic, i.e., they may not happen every time the same operation is performed. Instead, they occur with a certain probability.
Here are a few examples of situations that could lead to probabilistic errors:
1. **Concurrency and Race Conditions**: In concurrent systems, the order in which operations are executed can be unpredictable and can lead to different outcomes. If the software is not designed to handle all possible execution orders, it can lead to probabilistic errors, such as race conditions, where the result depends on the timing of certain operations.
2. **Network Failures and Distributed Systems**: In distributed systems or systems that rely on network communications, network failures can lead to probabilistic errors. These can include lost messages, delays, and partial failures. As these events are inherently unpredictable, they can lead to errors that occur with a certain probability.
3. **Randomized Algorithms**: Some algorithms, such as those used in machine learning or optimization, involve an element of randomness. These algorithms can sometimes produce incorrect results due to this randomness, leading to probabilistic errors.
4. **Use of Unreliable Hardware**: Hardware failures can lead to probabilistic errors. For example, memory corruption, disk failures, or unreliable network hardware can cause unpredictable and probabilistic errors in the software that uses them.
5. **Birthday Paradox**: In probability theory, the birthday problem or birthday paradox concerns the probability that, in a set of n randomly chosen people, some pair of them will have the same birthday. Similarly, when generating random identifiers (like GUIDs), there is a non-zero chance that two of them might collide, even if the chance is extremely small.
Probabilistic errors can be difficult to diagnose and fix, as they often cannot be reproduced consistently. They require careful design and robust error handling to mitigate. Techniques for dealing with probabilistic errors can include redundancy, error detection and correction codes, robust software design principles, and extensive testing.
So tell me, have it ever happened to you? how did you detected the error? and how did you fix it?
Until next time, happy coding!!!!

by Joche Ojeda | Jul 3, 2023 | Programming Situations
A GUID (Globally Unique Identifier) is a unique reference number used as an identifier in computer systems. GUIDs are usually 128-bit numbers and are created using specific algorithms that are designed to make each GUID unique.
Characteristics of GUIDs:
- Uniqueness: The primary characteristic of a GUID is its uniqueness. The intent of a GUID is to be able to uniquely identify a resource, entity, or a record in any context, across multiple systems and databases, without overlap.
- Size: A GUID is typically a 128-bit number, which means there are a huge number of possible GUIDs (2 to the power of 128, or about 3.4 × 10^38).
- Format: GUIDs are usually expressed as 32 hexadecimal digits, grouped in a specific way and separated by hyphens, e.g.,
3F2504E0-4F89-11D3-9A0C-0305E82C3301.
- No Semantic Meaning: A GUID itself does not carry any information about the data it represents. It is simply a unique identifier.
Why are GUIDs useful?
- Distributed Systems: GUIDs are especially useful in distributed systems for ensuring unique identifiers across different parts of the system without needing to communicate with a central authority.
- No Central Authority Needed: With GUIDs, there’s no need for a central authority to manage the issuance of unique identifiers. Any part of your system can generate a GUID and be fairly certain of its uniqueness.
- Database Operations: GUIDs are also used as unique identifiers in databases. They are useful for primary keys, and they help avoid collisions that might occur during database operations like replication.
- Safer Data Exposure: Because a GUID does not disclose information about the data it represents, it is safer to expose in public-facing operations, such as in URLs for individual data records, compared to an identifier that might be incrementing or otherwise guessable.
However, using GUIDs also has its trade-offs. Their large size compared to a simple integer ID means they take up more storage space and index memory, and are slower to compare. Also, because they are typically generated randomly, they can lead to fragmentation in the database, which can negatively impact performance.
Disadvantages
While GUIDs (Globally Unique Identifiers) have several advantages, such as providing a unique identifier across different systems and domains without the need for a central authority, they do come with their own set of problems and limitations. Here are some common issues associated with using GUIDs:
- Size: A GUID is 128 bits, much larger than an integer or long. This increased size can lead to more memory and storage usage, especially in large systems. They also take longer to compare than integers.
- Non-sequential: GUIDs are typically generated randomly, so they are not sequential. This can lead to fragmentation in databases, where data that is frequently accessed together is stored in scattered locations. This can slow down database performance.
- Readability: GUIDs are not human-friendly, which makes them difficult to debug or troubleshoot. For example, if you’re using GUIDs in URLs, it’s hard for users to manually enter them or understand them.
- Collision Risk: While the risk of generating a duplicate GUID is incredibly small, it is not zero. Especially in systems that generate a very large number of GUIDs, the probability of collision (though still extremely small) is greater than zero. This is known as the “birthday problem” in probability theory.
- No Information Content: GUIDs don’t provide any information about the data they represent. Unlike structured identifiers, you can’t encode any information in a GUID.
- Network Sorting: GUIDs can have different sort orders, depending on whether they’re sorted as strings or as raw byte arrays, and this can lead to confusion and mistakes.
To mitigate some of these problems, some systems use GUIDs in a modified or non-standard way. For example, COMB (combined GUID/timestamp) GUIDs or sequential GUIDs add a sequential element to reduce database fragmentation, but these come with their own trade-offs and complexities.
COMB GUIDS
A COMB (Combined Guid/Timestamp) GUID is a strategy that combines the uniqueness of GUIDs with the sequential nature of timestamps to mitigate some of the issues associated with GUIDs, particularly the database fragmentation issue.
A typical GUID is 128 bits and is usually displayed as 32 hexadecimal characters. When generating a COMB GUID, part of the GUID is replaced with the current timestamp. The portion of the GUID that is replaced and the format of the timestamp can vary depending on the specific implementation, but a common strategy is to replace the least significant bits of the GUID with the current timestamp.
Here’s a broad overview of how it works:
- Generate a regular GUID.
- Get the current timestamp (in a specific format, such as the number of milliseconds since a particular epoch).
- Replace a part of the GUID with the timestamp.
Because the timestamp is always increasing, the resulting COMB GUIDs will also increase over time, meaning that when new rows are inserted into a database, they are likely to be added to the end of the table or index, thus minimizing fragmentation.
However, there are some trade-offs to consider:
- Uniqueness: Because part of the GUID is being replaced with a timestamp, there is a slightly higher chance of collision compared to a regular GUID. However, as long as the non-timestamp portion of the GUID is sufficiently large and random, the chance of collision is still extremely small.
- Size: A COMB GUID is the same size as a regular GUID, so it doesn’t mitigate the issue of GUIDs being larger than simpler identifiers like integers.
- Readability and information content: Like regular GUIDs, COMB GUIDs are not human-friendly and don’t provide information about the data they represent.
- Sorting dependance: In most cases, COMB GUIDs are generated by a custom algorithm that adds a timestamp. This means that you also need an algorithm to extract the timestamp and execute the sorting based on these timestamp values. Additionally, you might need to implement your algorithm twice: once for the client side and once for the database engine
It’s worth noting that different systems and languages may have their own libraries or functions for generating COMB GUIDs. For example, in .NET, the NHibernate ORM has a comb identifier generator that generates COMB GUIDs.
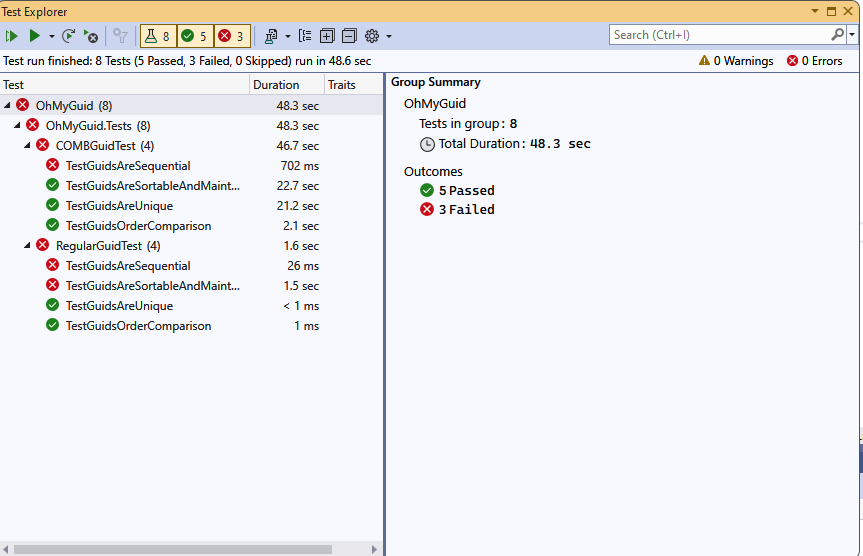
And before I say good bye to this article, here is a test project to probe my point
https://github.com/egarim/OhMyGuid
And here are the test results
Until the next time, happy coding ))